[CL]《Think Deep, Not Just Long: Measuring LLM Reasoning Effort via Deep-Thinking Tokens》W Chen, L Peng, T Tan, C Zhao... [Google & University of Virginia] (2026) 推理模型(LLM)的“思考”究竟该如何衡量?是靠输出的长篇大论,还是靠深不可测的逻辑?
本文提出了一个颠覆性的观点:衡量推理能力的尺子,不应是 Token 的长度,而应是 Token 的“深度”。
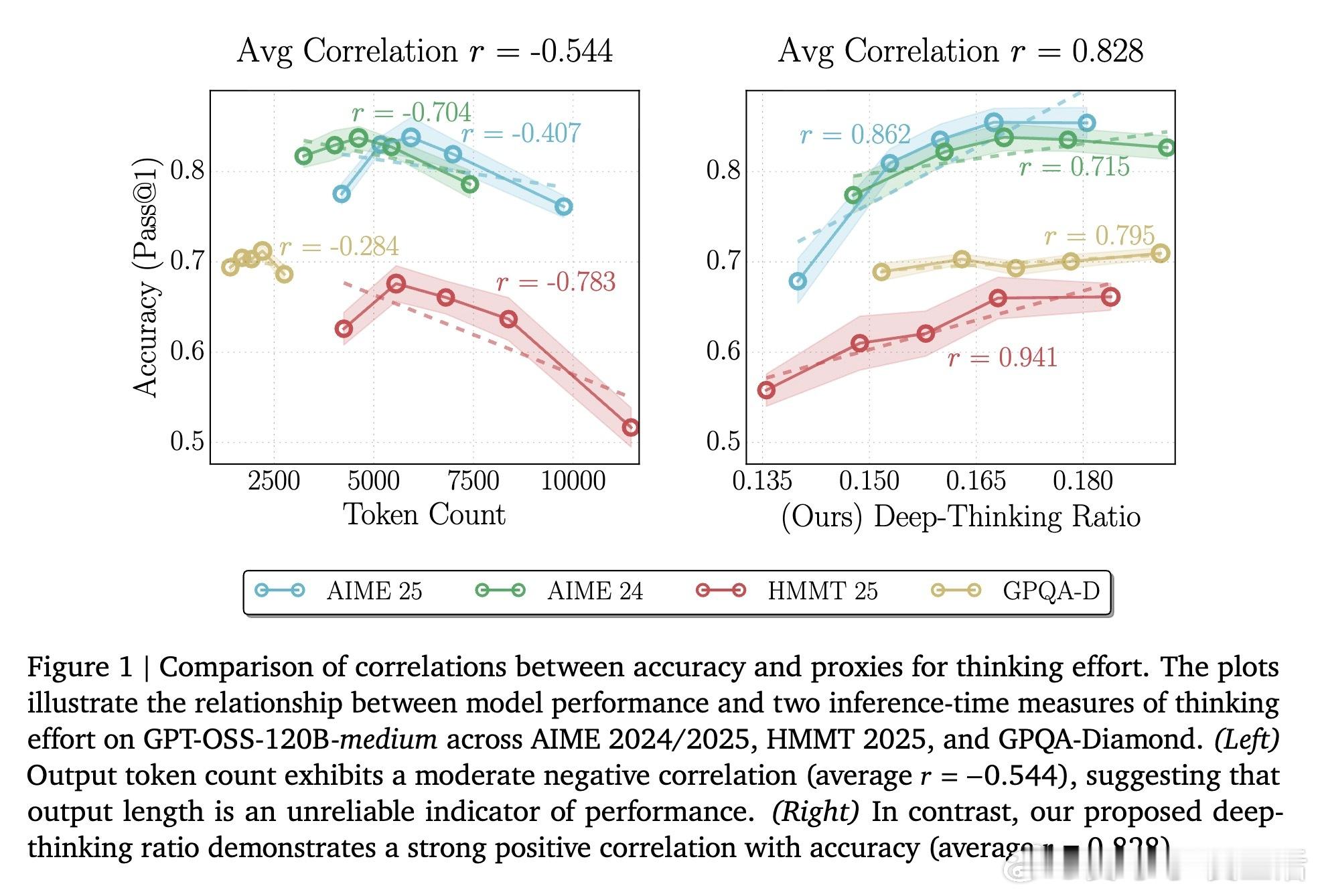
1. 长度陷阱:多想不代表想对过去我们迷信“思维链(CoT)越长,推理越强”。但研究发现,Token 数量与准确率之间往往呈现负相关,甚至会出现“过度思考”导致的性能下降。模型可能只是在废话文学中循环,或者在错误的假设上反复横跳。
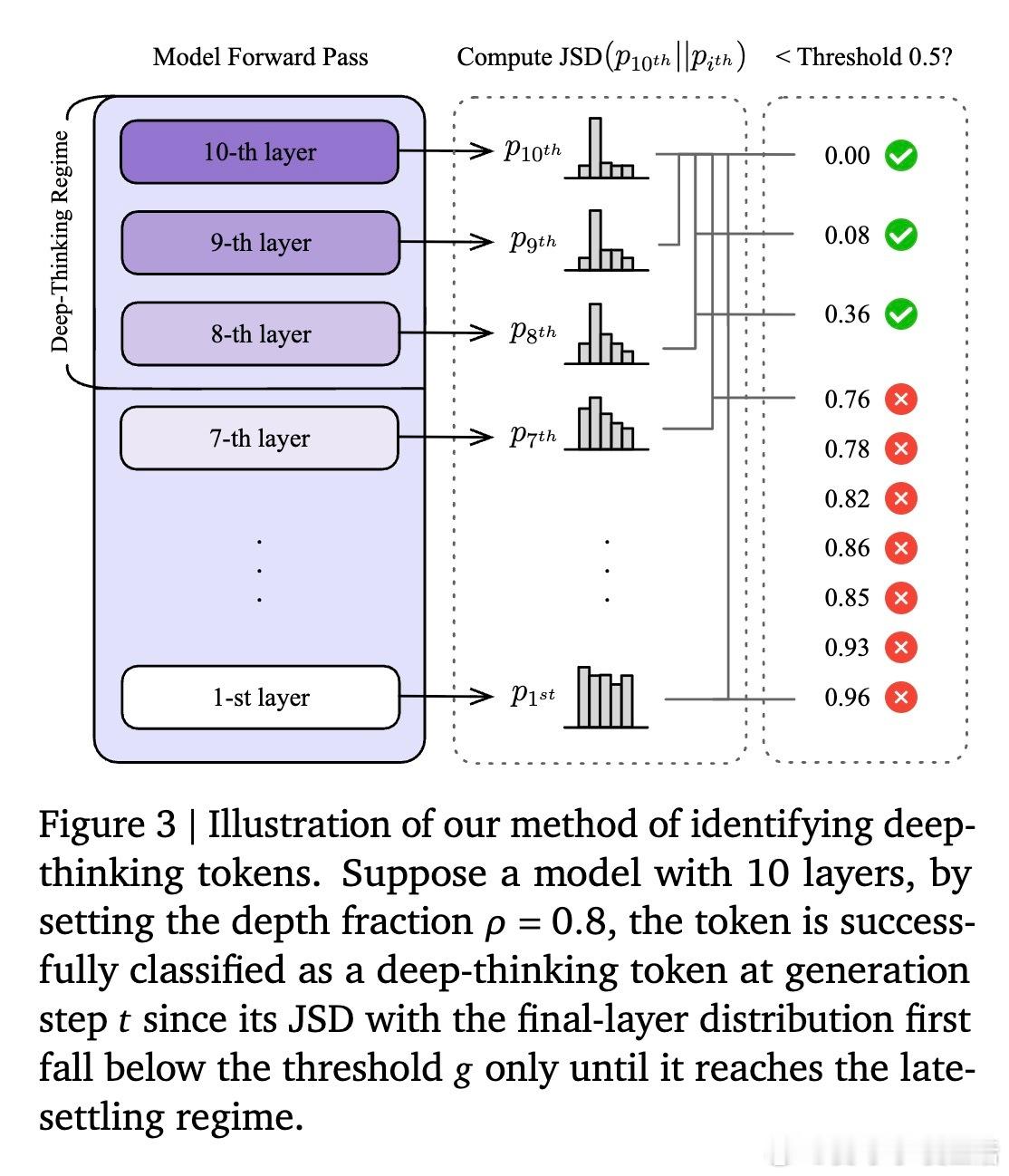
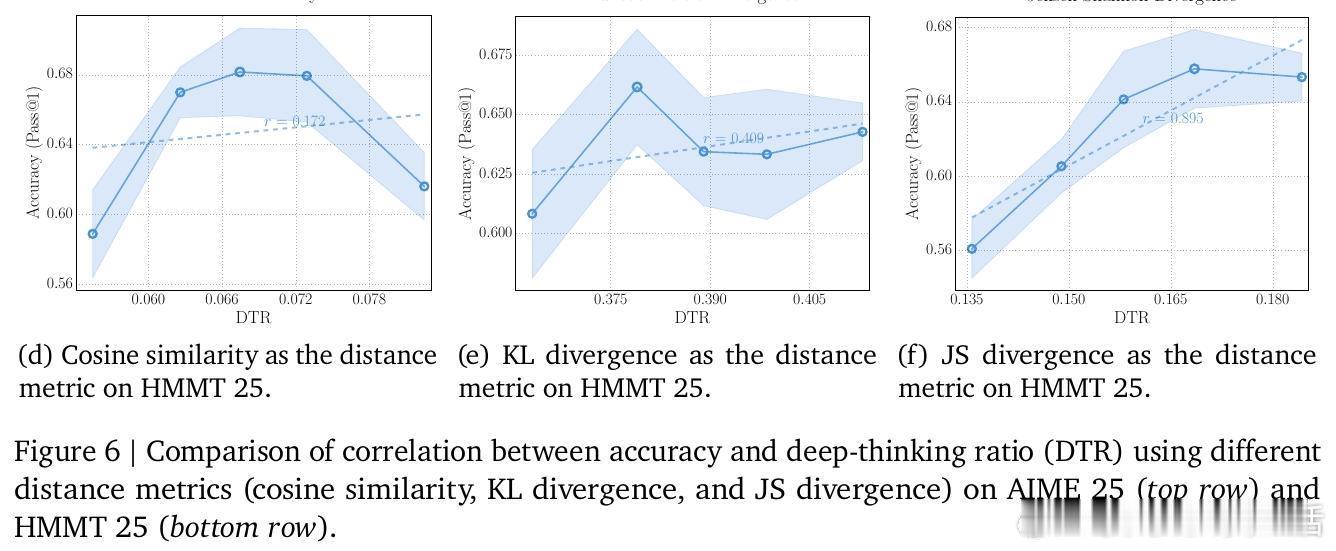
2. 深度定义:预测分布的“定型”时刻真正的思考发生在线性序列的背后。研究者提出了“深层思考比例(DTR)”这一指标。它观察模型内部每一层对下一个 Token 的预测。如果一个 Token 在浅层就已确定,那是直觉;如果它直到最后几层才发生剧烈修正并最终定型,那才是真正的“深度思考”。
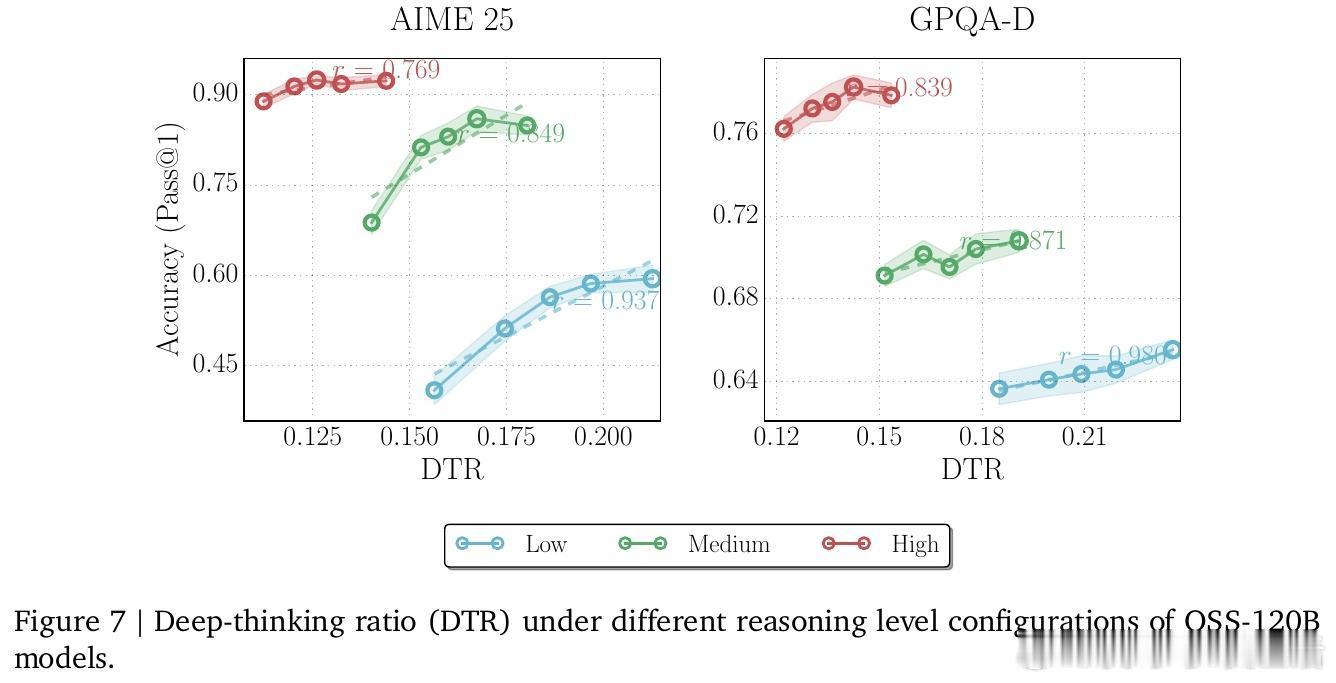
3. 核心发现:DTR 是更可靠的导航仪在 AIME 和 GPQA 等高难度数学与科学竞赛测试中,DTR 与准确率的正相关性高达 0.828,远超传统的 Token 计数和置信度指标。这意味着:一个模型是否真的在解决难题,看它内部逻辑的修订深度,比看它写了多少字要准得多。
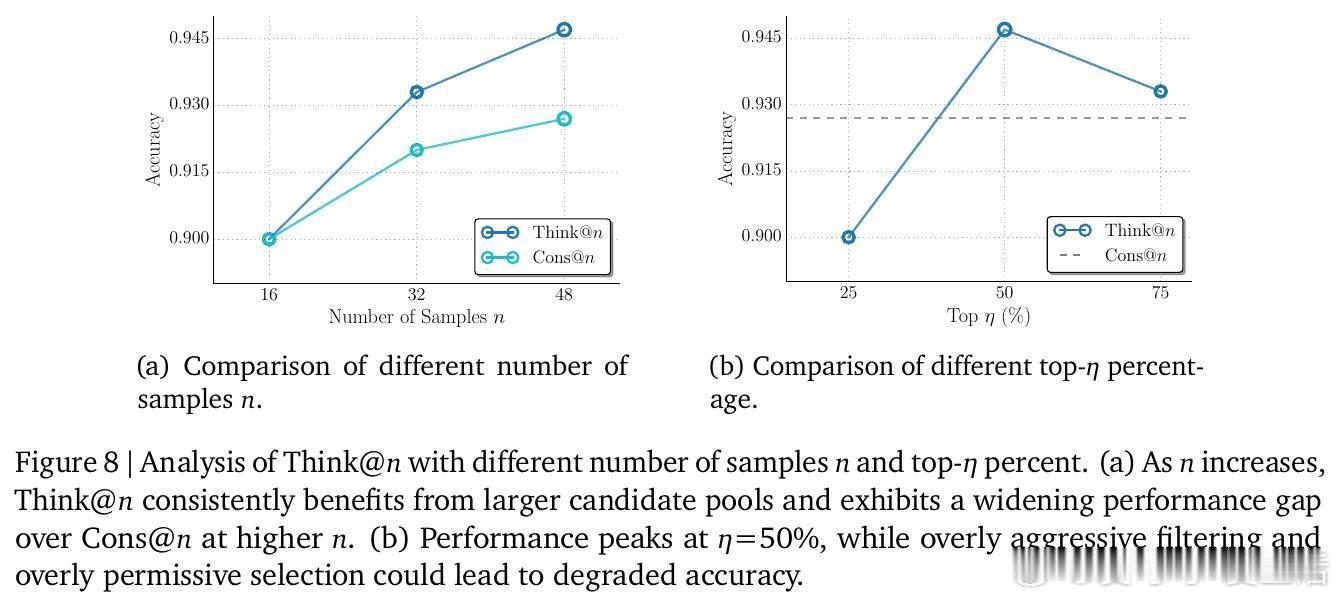
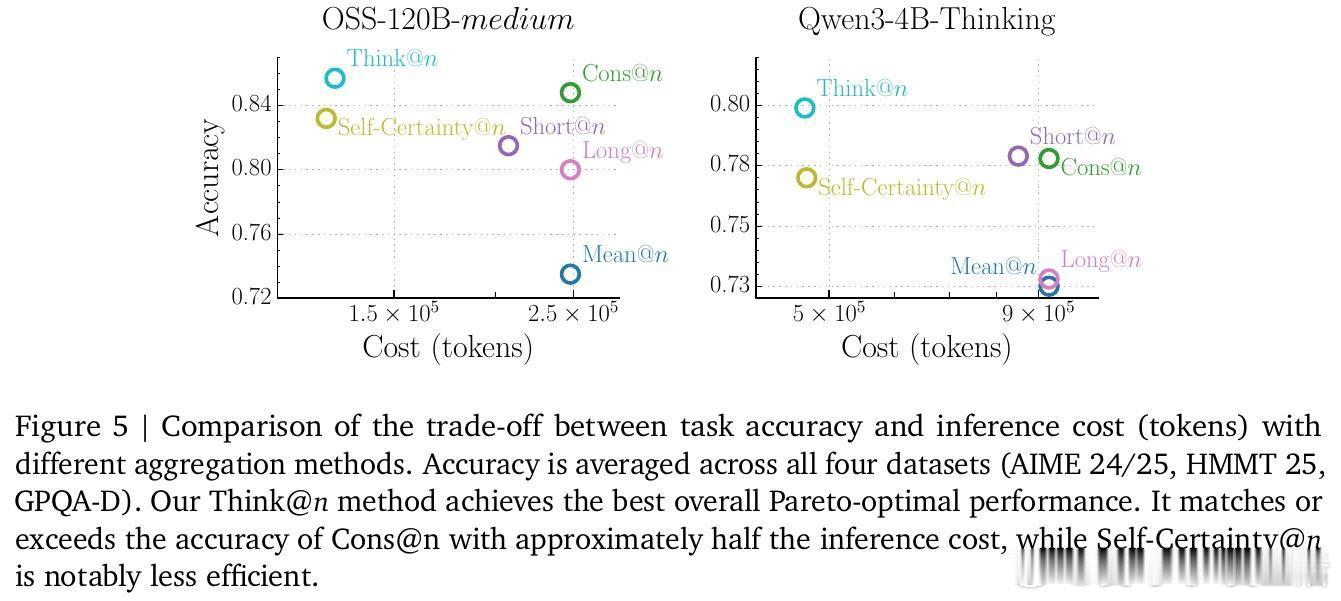
4. 效率革命:Think策略基于这一发现,研究者开发了 Think推理策略。通过分析生成序列前 50 个 Token 的深度思考比例,模型可以提前判断这是否是一条“通往真理”的路径。如果 DTR 过低,直接掐断重来。这种方法在保持甚至超越标准自一致性(Self-Consistency)准确率的同时,节省了近 50% 的计算成本。
5. 深度启发:从“量产”转向“质变”这项研究给 AI 社区带来了一个深刻的启示:推理的本质不是时间的堆砌,而是信息的蒸馏。未来的推理模型不应该追求变得更“健谈”,而应该追求在每一层网络中进行更高效的逻辑碰撞。
思考:- 废话是推理的噪音,深层的自我修正才是智慧的火花。- 优秀的模型不一定想得久,但一定想得深。- 计算资源的浪费往往始于对“长度”的盲目崇拜,而效率的提升始于对“深度”的精准捕捉。
arxiv.org/abs/2602.13517