[LG]《Goldilocks RL: Tuning Task Difficulty to Escape Sparse Rewards for Reasoning》I Mahrooghi, A Lotfi, E Abbe [EPFL & Apple] (2026)
在强化学习(RL)重塑大模型推理能力的今天,我们正面临一个隐形的效率陷阱:稀疏奖励。当模型在浩如烟海的搜索空间中盲目摸索,却因为题目太难或太易而收不到有效反馈时,昂贵的算力便在无声中被浪费。
本文提出了 Goldilocks RL,通过动态调整任务难度,让模型训练告别盲目,进入高效进化的快车道。
1. 稀疏奖励的沉默杀手
在推理任务中,我们通常采用结果监督(Outcome Supervision)。这意味着模型只有在得出完全正确的最终答案时才能获得奖励。这种二元论的反馈机制极其稀疏:如果题目太难,模型永远做不对,梯度就会消失;如果题目太简单,模型闭着眼都能做对,同样无法产生学习信号。
这种无效的探索让 RL 训练变得异常低效。目前的课程学习往往依赖于预设的难度标签或频繁的回头复习,但在海量数据的时代,这种静态或回溯式的方法已难以为继。
2. 金发姑娘原则:恰到好处的难度
Goldilocks RL 的核心逻辑非常直观:为学生模型寻找那些既不太难也不太易的问题。
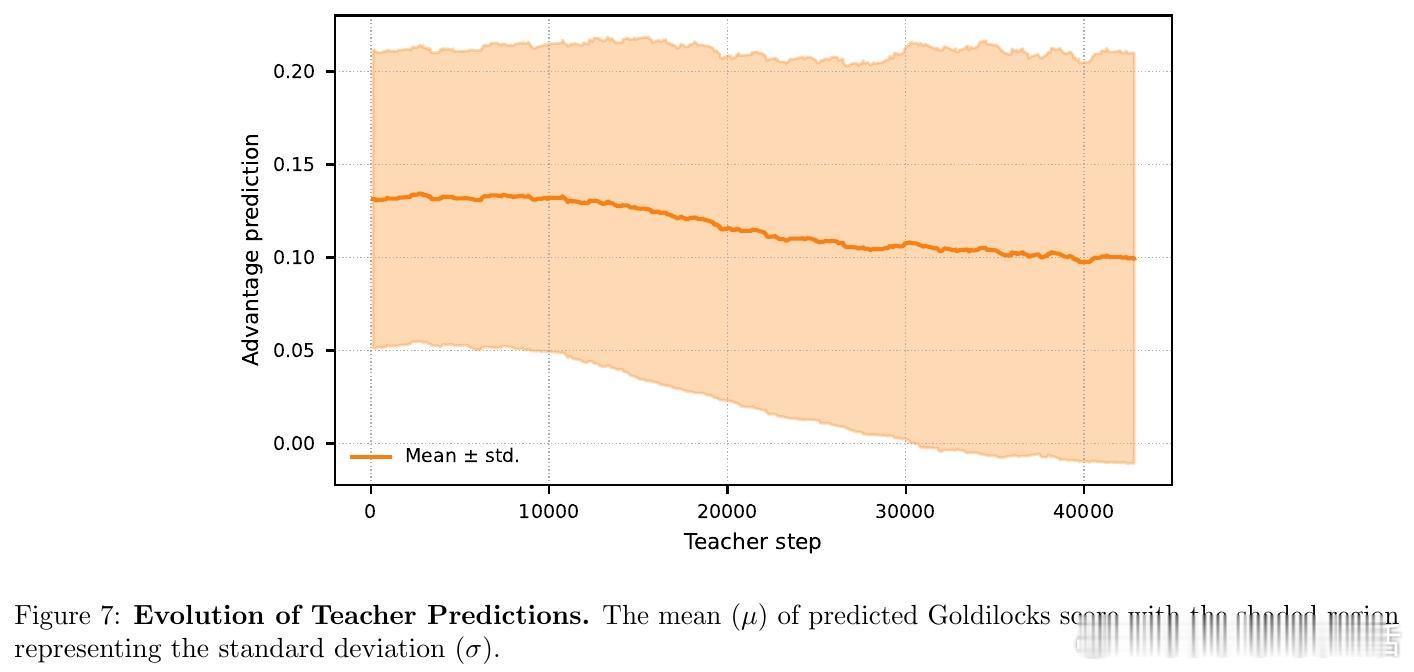
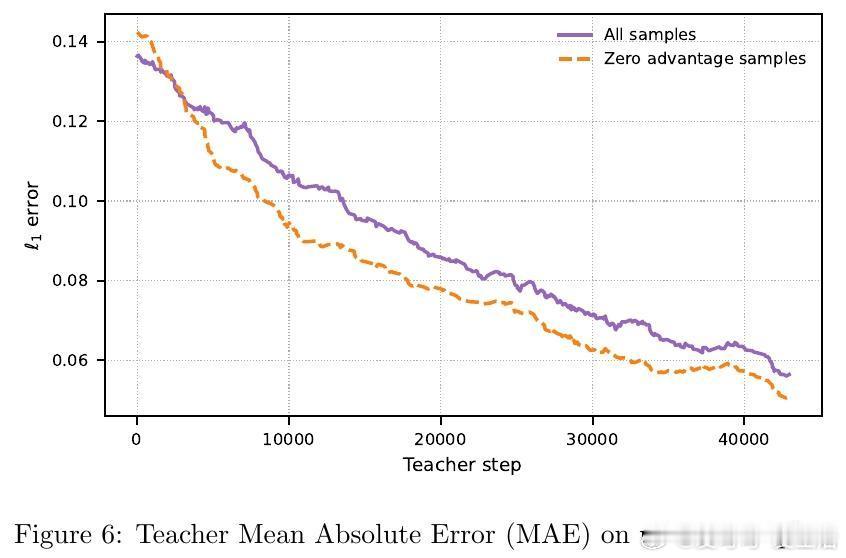
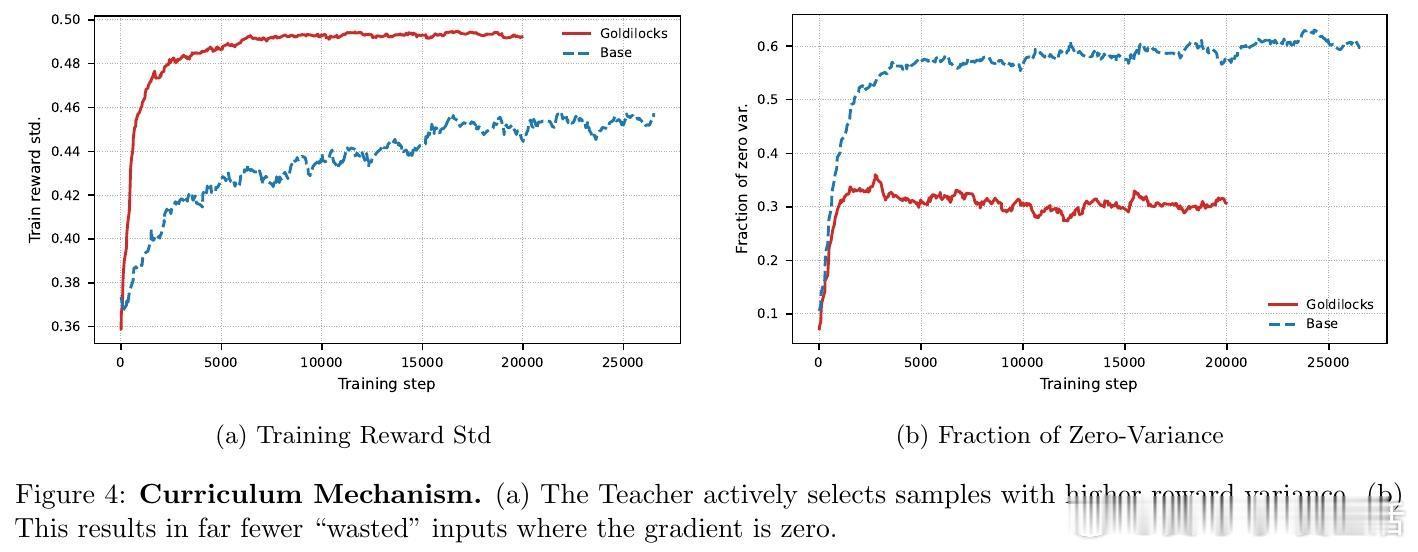
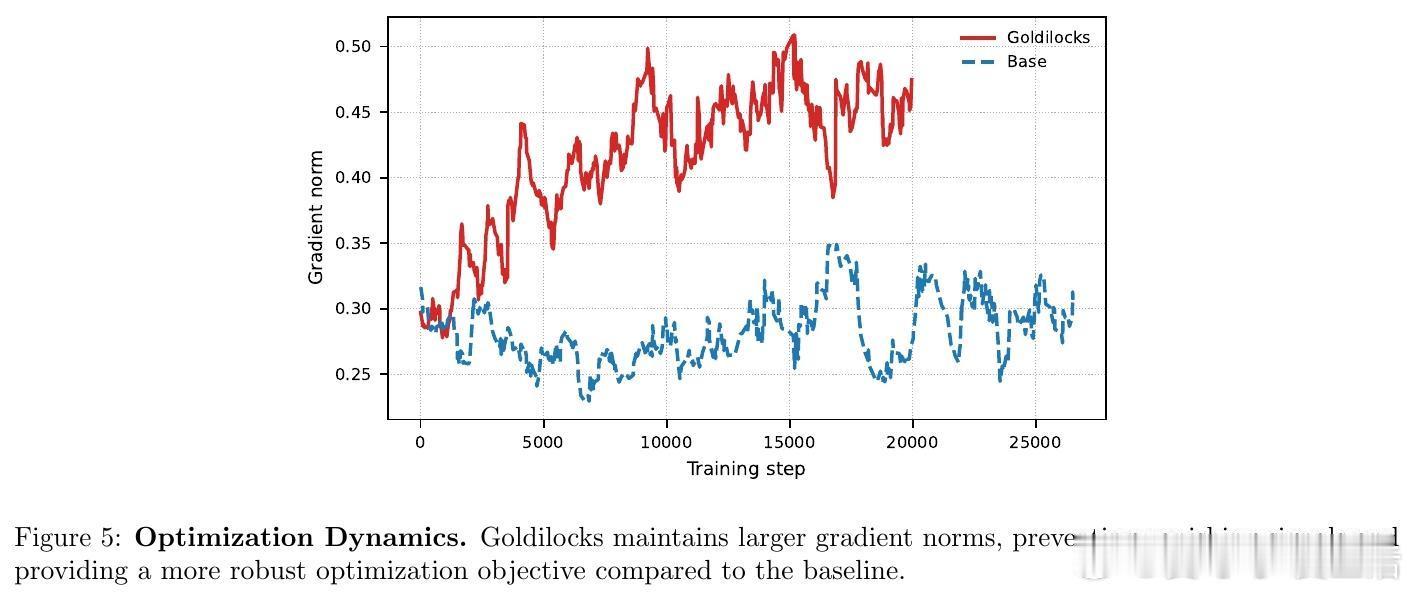
从数学上看,GRPO 等算法的梯度幅值与结果的方差成正比。当模型解决某类问题的成功率在 0.5 左右时,学习信号最强,梯度最为稳健。Goldilocks 框架通过引入一个教师模型(Teacher),实时预测每个问题对当前学生模型(Student)的潜在效用,从而精准筛选出处于模型能力边界的问题。
3. 教师与学生的共生进化
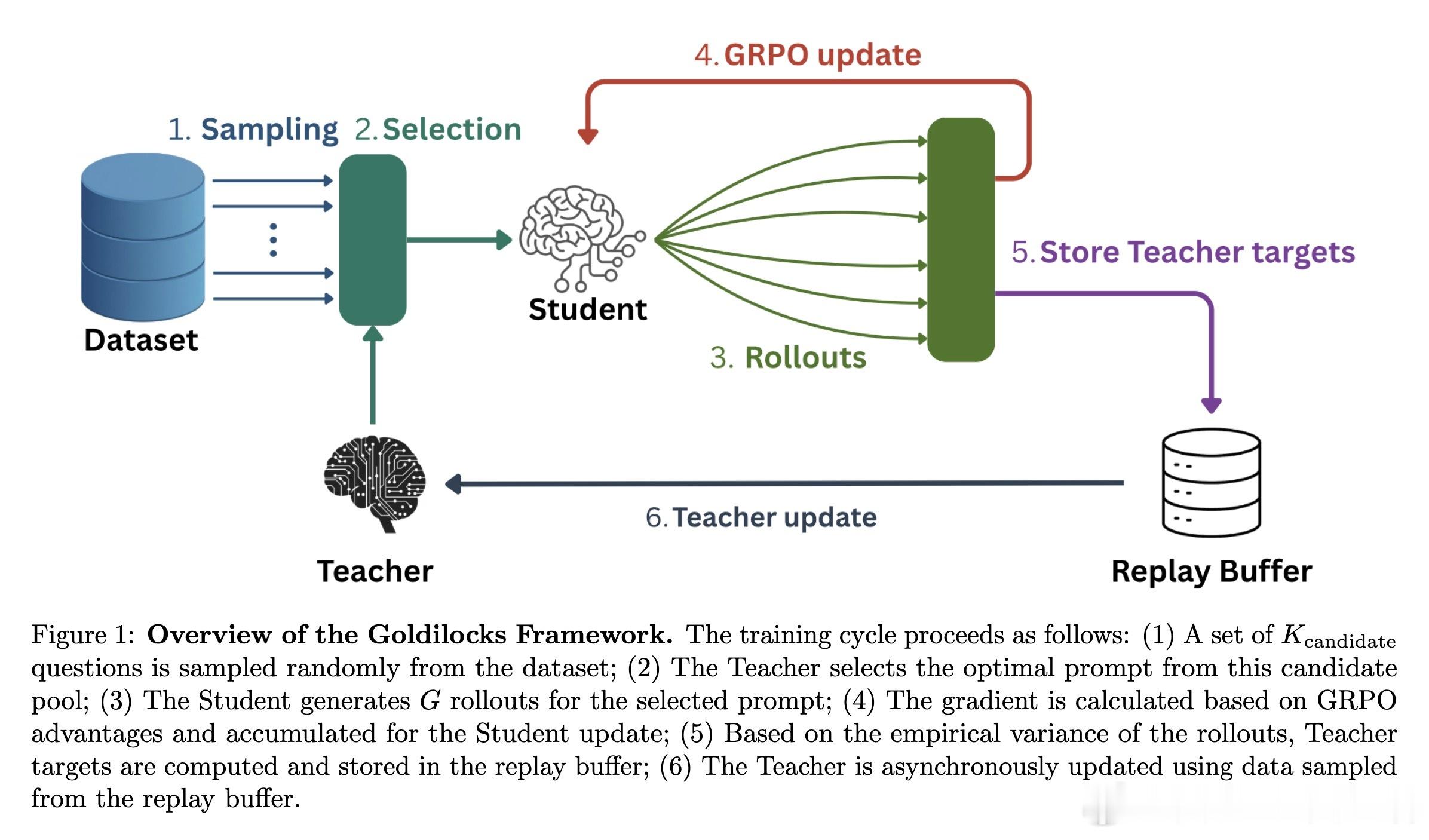
Goldilocks 并不是一个静态的筛选器,而是一个动态的闭环系统:
- 教师模型:基于小型 LLM 架构,预测问题的学习价值。它不看标准答案,而是学习预测学生的成功概率。- 动态采样:采用 epsilon-greedy 策略,在探索新题和榨取高价值题目之间取得平衡。- 实时反馈:学生在训练中产生的真实表现会立即反馈给教师,教师据此不断更新对学生能力的认知。
这种架构确保了教材始终随着学生能力的增长而自动升级。
4. 算力分配的艺术
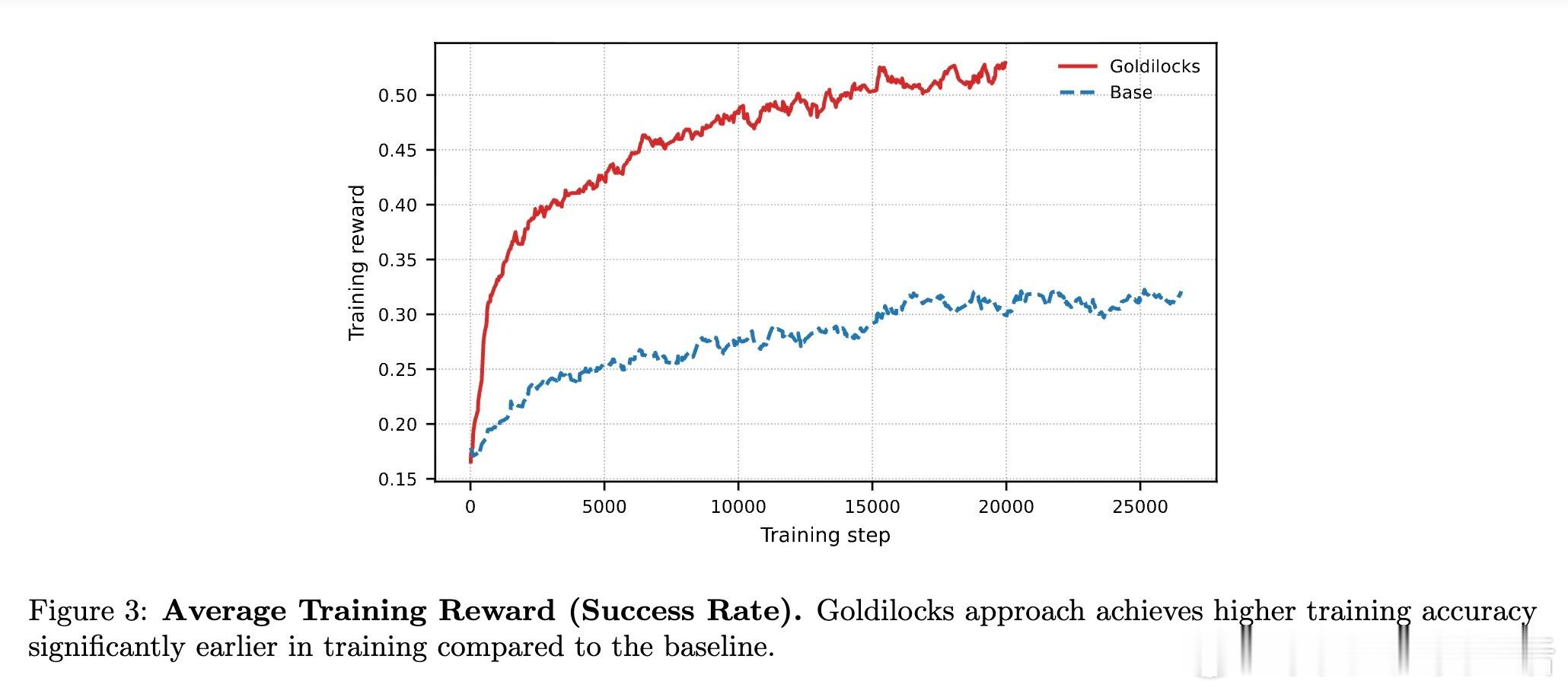
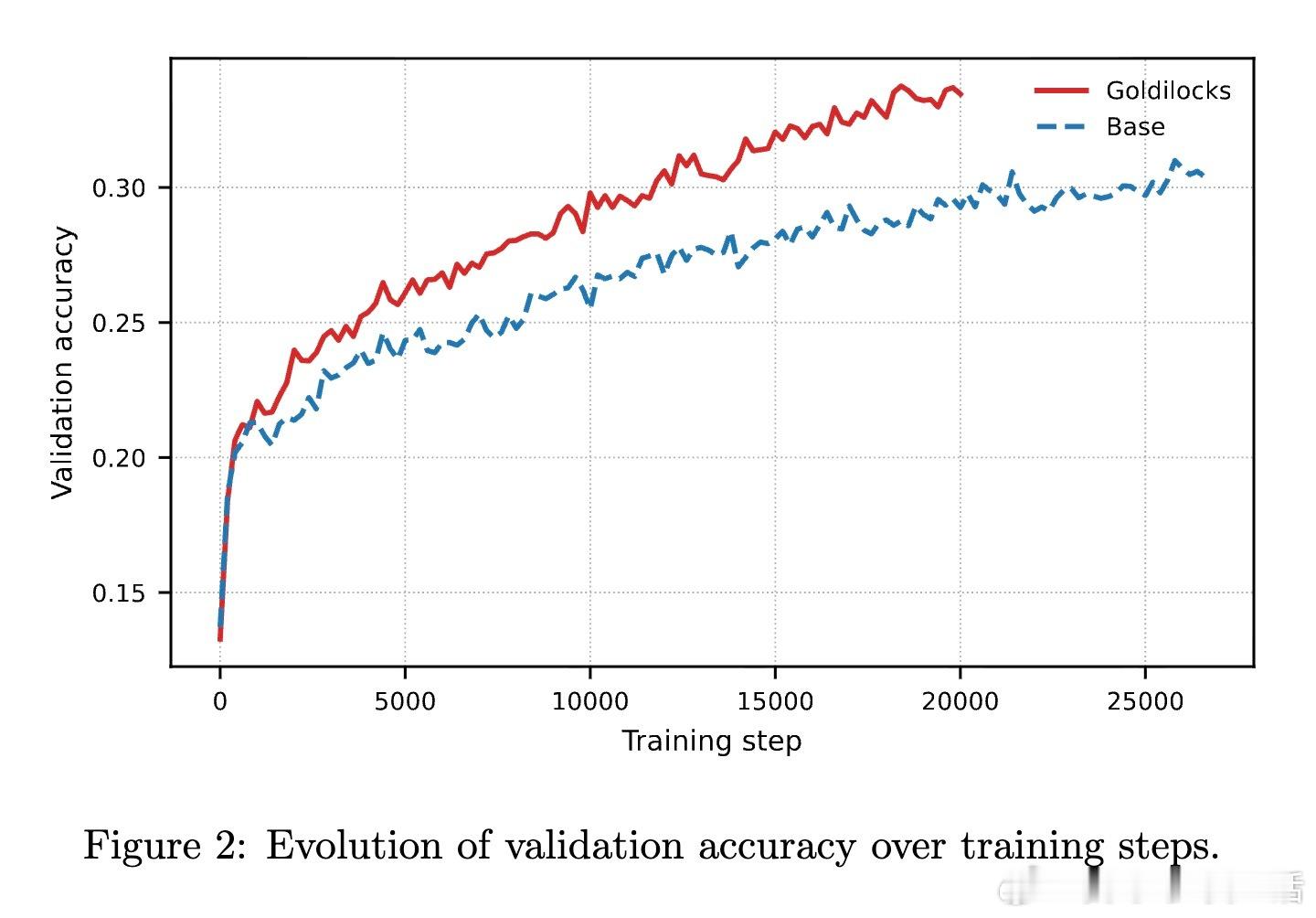
在实验中,研究者做了一个严苛的对比:在相同的 8 张 GPU 算力预算下,基线方法全部用于训练,而 Goldilocks 分出 2 张 GPU 专门运行教师模型。
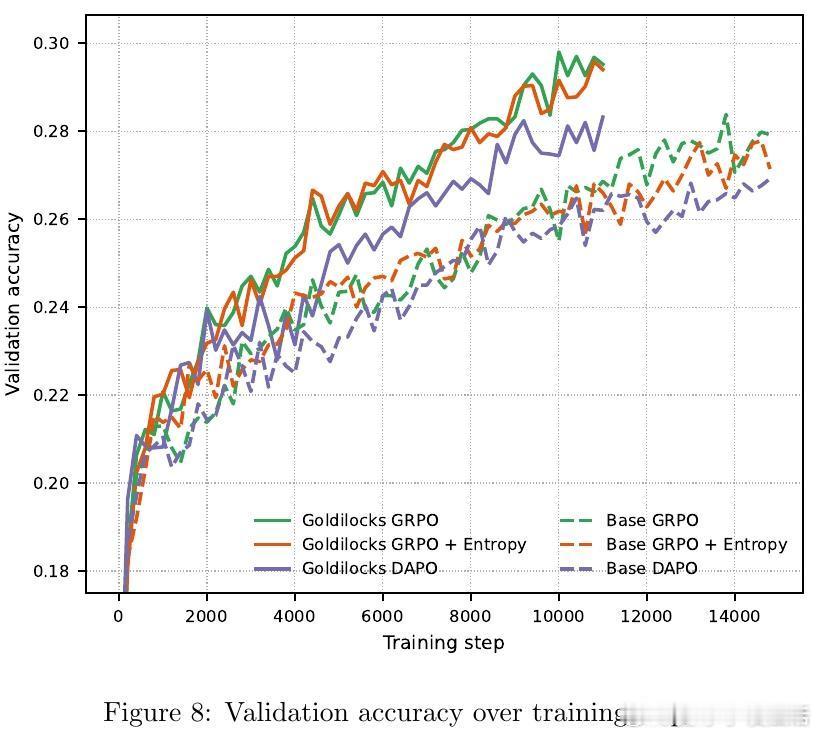
结果令人振奋:尽管学生模型可用的算力减少了,但由于每一条数据都精准击中了学习痛点,最终在 OpenMathReasoning 等复杂推理任务上的表现显著优于全量算力的基线模型。这证明了在 RL 时代,数据的质远比量更重要。
5. 深度思考:效率是另一种形式的规模
过去我们迷信 Scaling Law,认为只要算力足够,模型终会进化。但 Goldilocks 告诉我们,盲目的规模扩张是对资源的极大消耗。真正的智能进化,应当是模型在确定性与不确定性之间的精准舞蹈。
正如最好的老师不是教你最难的题,而是教你那些跳一跳就能碰到的题。Goldilocks RL 本质上是在为 AI 构建一种人工的直觉,让它学会在挑战中寻找最优的成长路径。
6. 总结
Goldilocks RL 的成功为我们提供了几点深刻启发:
- 梯度消失往往不是因为模型不行,而是因为题目不对。- 0.5 的成功率是学习的黄金分割点,那是确定性瓦解、新知识萌芽的地方。- 效率不是对规模的妥协,而是对规模的升华。
在通往 AGI 的道路上,我们不仅需要更强大的算力,更需要像 Goldilocks 这样优雅的调度者,让每一瓦特电力都能转化为真正的智能。
论文链接:arxiv.org/abs/2602.14868