📍一、为什么大模型B端商业化瞄准了知识库
对于中大企业,特别是万人以上的,部门繁多,知识散落,知识散乱人员流动较大,知识资产无法沉淀,无形降低企业的运行效率,增加企业的教育成本,企业各种知识文档叠加大模型无疑在商业化层面是相对容易实现的,这种提效很明显
😭但是....还是想泼一盆冷水,也是昨天和一位AIGC产品讨论的一个话题,主要有几点
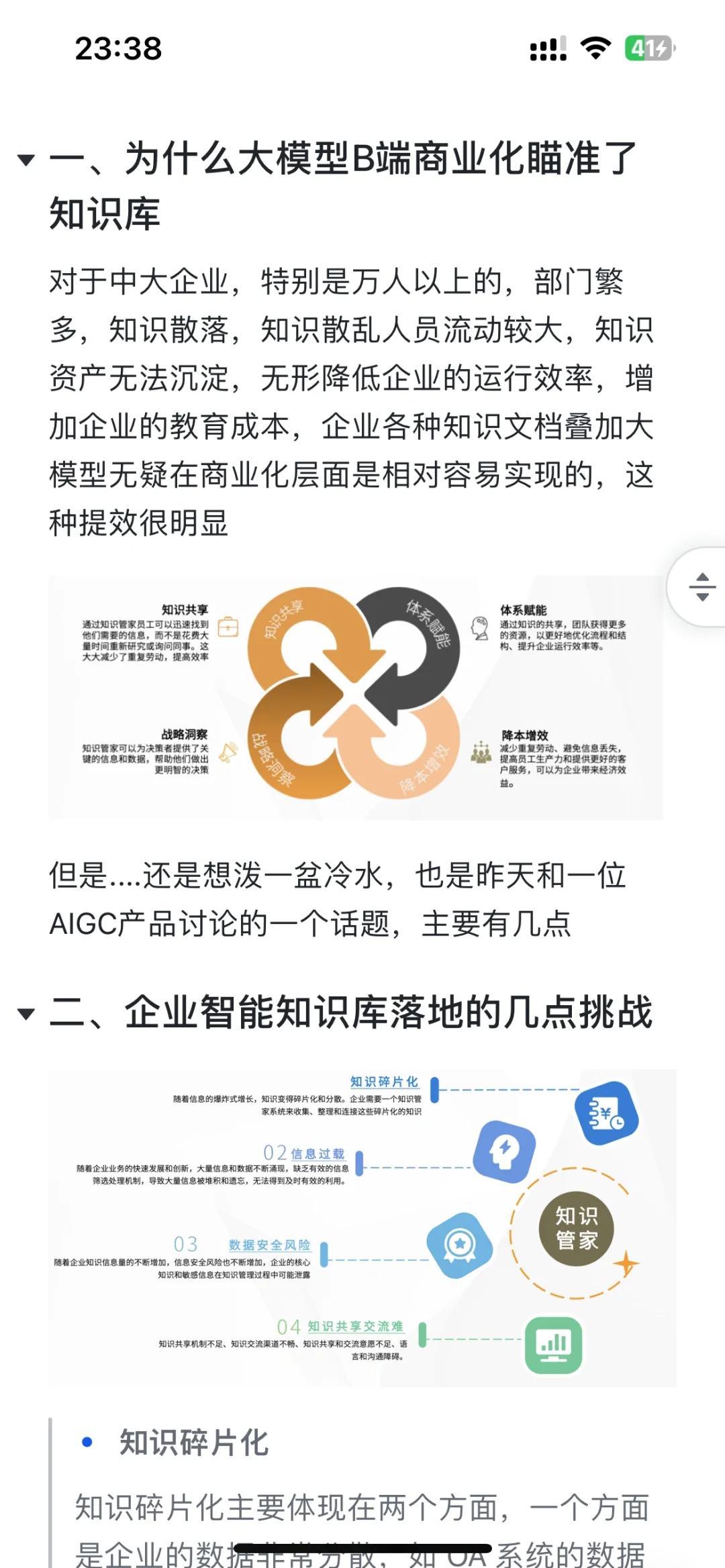
📍二、企业智能知识库落地的几点挑战
1⃣️知识碎片化
知识碎片化主要体现在两个方面,一个方面是企业的数据非常分散,如 OA 系统的数据有不同部门的、不同团队的。另一方面,这些数据基本上都是以非结构化形式去提供的,比如 Word、PDF、图片、视频等。在知识管家建设的过程中,如何把这些知识碎片化的信息快速集中,是面临的第一个挑战。
2⃣️信息过载
3⃣️数据安全风险
4⃣️知识共享交流难
📍三、构建的流程如何?
1⃣️数据收集层
2⃣️数据处理层
3⃣️逻辑交互层
智能问答交互的过程:在用户提出问题后,首先借助智能助手把问题向量化,再去数据库做语义的检索,得到关联这个语义相近的文章上下文,通过上下文结合提示词,经过大模型的推理,最终得到答案的返回。整体过程是一个不断迭代和反馈优化的过程,只有这样才能得到基于企业私域数据上的专属智能专家角色。
📍四、更多细节
1⃣️ 数据ETL处理pipeline
2⃣️向量化存储
3⃣️对话流程的pipeline
4⃣️模型微调
5⃣️迭代与反馈