🔥大模型(LLM,Large Language Model)的构建流程,特别是OpenAI所使用的大语言模型GPT构建流程,主要包含四个阶段:预训练、有监督微调、奖励建模和强化学习。
.
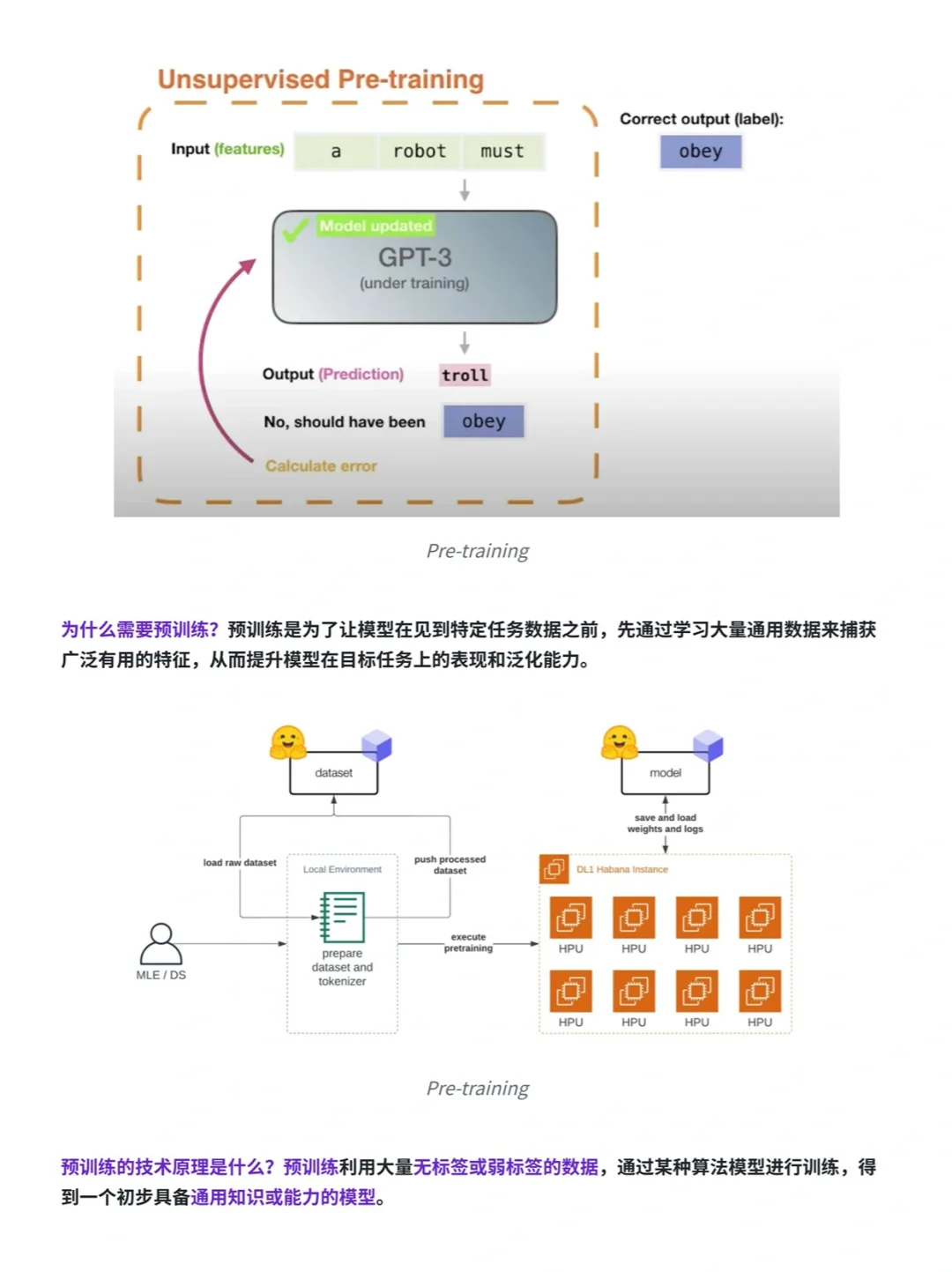
1️⃣ 预训练(Pre-training)
预训练技术通过从大规模未标记数据中学习通用特征和先验知识,减少对标记数据的依赖,加速并优化在有限数据集上的模型训练。
.
2️⃣ 有监督微调(Supervised Fine Tuning)
有监督微调(Supervised Fine-Tuning, SFT),也被称为指令微调(Instruction Tuning)。在已经预训练好的模型基础上,通过使用有标注的特定任务数据对模型进行进一步的训练和调整,以提高模型在特定任务或领域上的性能。
.
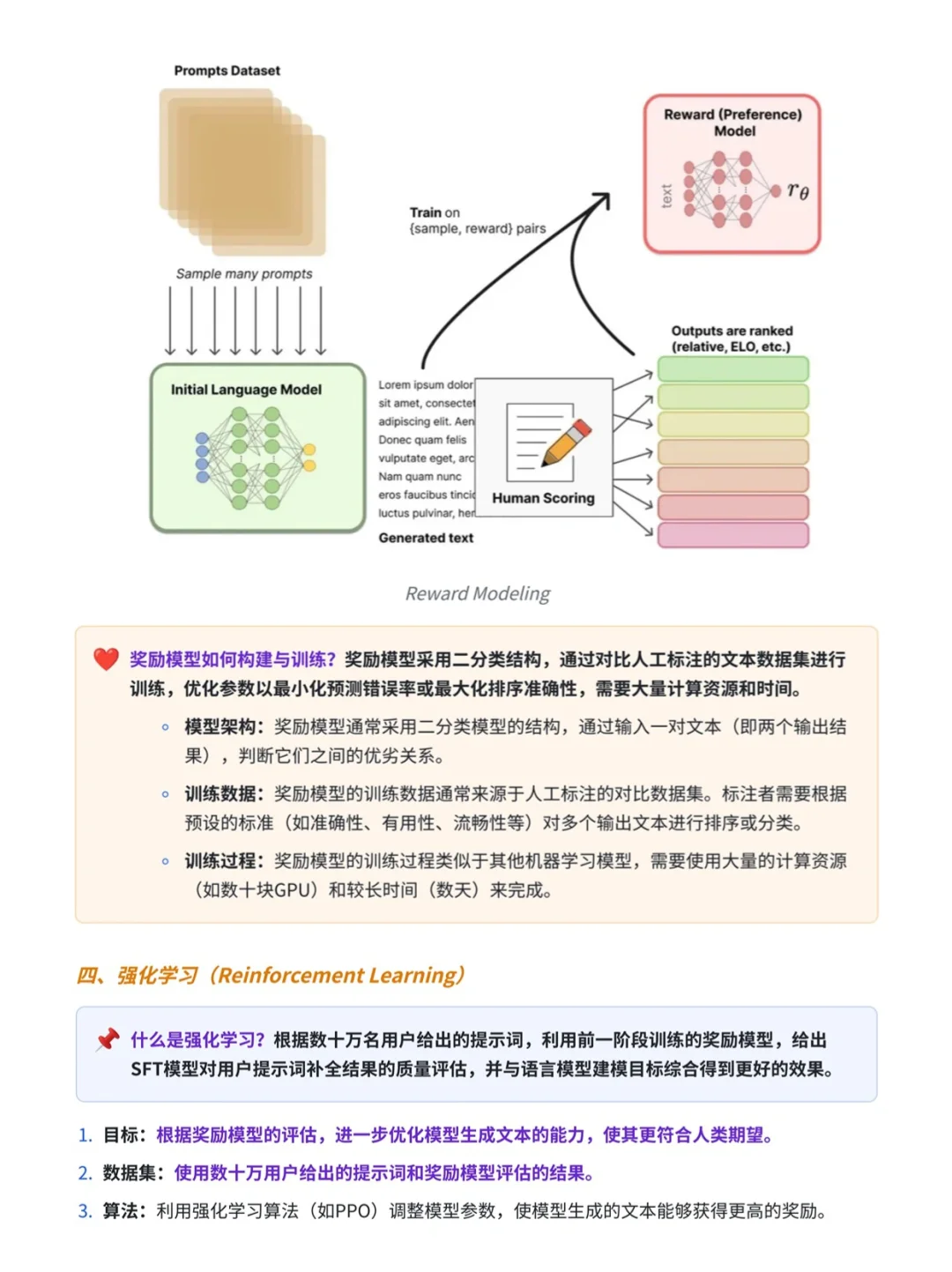
3️⃣ 奖励建模(Reward Modeling)
奖励模型是一个文本质量对比模型,它接受环境状态、生成的结果等信息作为输入,并输出一个奖励值作为反馈。
.
4️⃣强化学习(Reinforcement Learning)
根据数十万名用户给出的提示词,利用前一阶段训练的奖励模型,给出SFT模型对用户提示词补全结果的质量评估,并与语言模型建模目标综合得到更好的效果。
.
⌛这四个阶段各自需要不同规模的数据集、不同类型的算法,并会产出不同类型的模型,同时所需的资源也有显著差异。