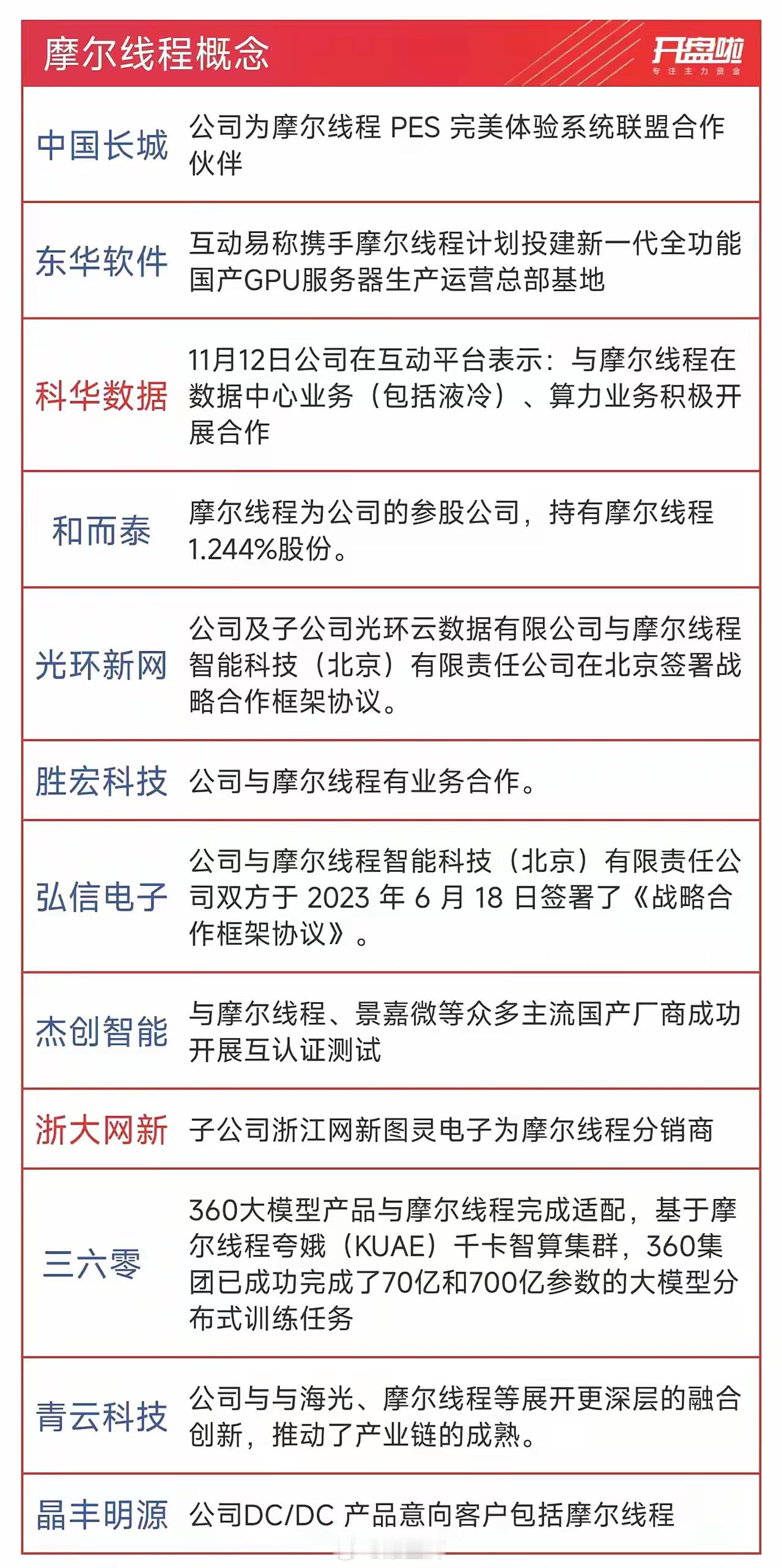
摩尔线程悄悄崛起!
摩尔线程:算力狂潮中的中国芯“核爆”
当全球算力竞技场被国际巨头垄断,摩尔线程以“中国速度”炸裂登场!这家成立仅4年的国产GPU新星,在创始人张建中(前英伟达全球副总裁)的率领下,硬生生撕开技术封锁的铁幕,用“全功能GPU+万卡集群”的组合拳,掀起一场颠覆性的算力革命。
算力怪兽,碾压国际巨头
摩尔线程自研的MUSA架构,不仅兼容CUDA生态实现“零成本代码迁移”,更以MTT S4000智算卡单挑英伟达旗舰——推理性能碾压RTX 3090,多batch场景下甚至力压RTX 4090!而其夸娥(KUAE)万卡智算集群更堪称“算力核弹”:总算力超万P,线性加速比突破91%,周均训练有效率高达99%,连续30天无中断运行的稳定性直接改写行业标准。更狂的是,其千卡集群训练700亿参数大模型时精度与英伟达A100误差仅1%,却以国产硬件成本实现“性能平替”!
从神话到现实:全栈算力帝国
从芯片、板卡到万卡集群,摩尔线程构建了全球首个全功能国产GPU算力版图。夸娥集群以“愚公移山”之志,支撑起LLaMA、GLM、DeepSeek等顶级大模型的千亿参数训练,77小时无故障完成700亿模型预训练,硬核表现让国际同行瞠目。更以MT-Link超高速互联技术(112GB/s带宽)和自研MCCL通讯库,将万卡集群的算力密度推至物理极限!
生态核爆:中国算力自立宣言
被美国列入实体清单后,摩尔线程反以降价策略横扫市场,MTT S80显卡价格腰斩仍性能炸场,甚至为《黑神话:悟空》定制优化驱动,玩家直呼“国产卡皇”。如今,其夸娥集群已赋能智谱AI、滴普科技等伙伴,打造完全自主的AI算力生态,更获政策力挺——北京直接对采购国产GPU企业发放补贴,誓将算力命脉握于掌中!
摩尔线程的崛起,不仅是技术的胜利,更是中国算力自主的史诗级突围——从此,全球算力版图必有东方巨龙的一席之地!

用户10xxx61
摩尔线程的崛起标志着国产GPU实现从技术追赶到生态突破的跨越。其自研MUSA架构兼容CUDA生态,MTTS4000智算卡推理性能超越RTX3090,夸娥万卡集群以91%线性加速比改写行业标准。通过高频驱动更新(2024年发布8个版本),《黑神话:悟空》帧率提升至55帧,《瘟疫传说》帧率暴涨120%,驱动国产GPU实现“可用”到“好用”的质变。生态层面,MT vGPU 2.7.0首次支持DirectX 12,兼容15%更多场景,联合中国移动打造云电脑方案,CPU负载降低75%,渲染性能提升10倍。资本层面获红杉中国、字节跳动注资,估值超240亿元并启动A股上市,政策端北京等地对国产GPU采购发放补贴,加速算力命脉自主化。这家“中国版英伟达”正以软硬件协同创新,书写全球算力版图的东方叙事。
赛尔江 回复 04-23 13:55
ig是中资控股
春之燕子 回复 05-07 15:55
真的假的?
psymerlin
一个体育号都开始推摩尔,看来钱没有少拿。
用户10xxx87
先把美国科技企业与技术墙在外,给国内企业十年成长时间
Hardness
过几年再换电脑我就准备用摩尔线程的显卡
serenity
早呢,