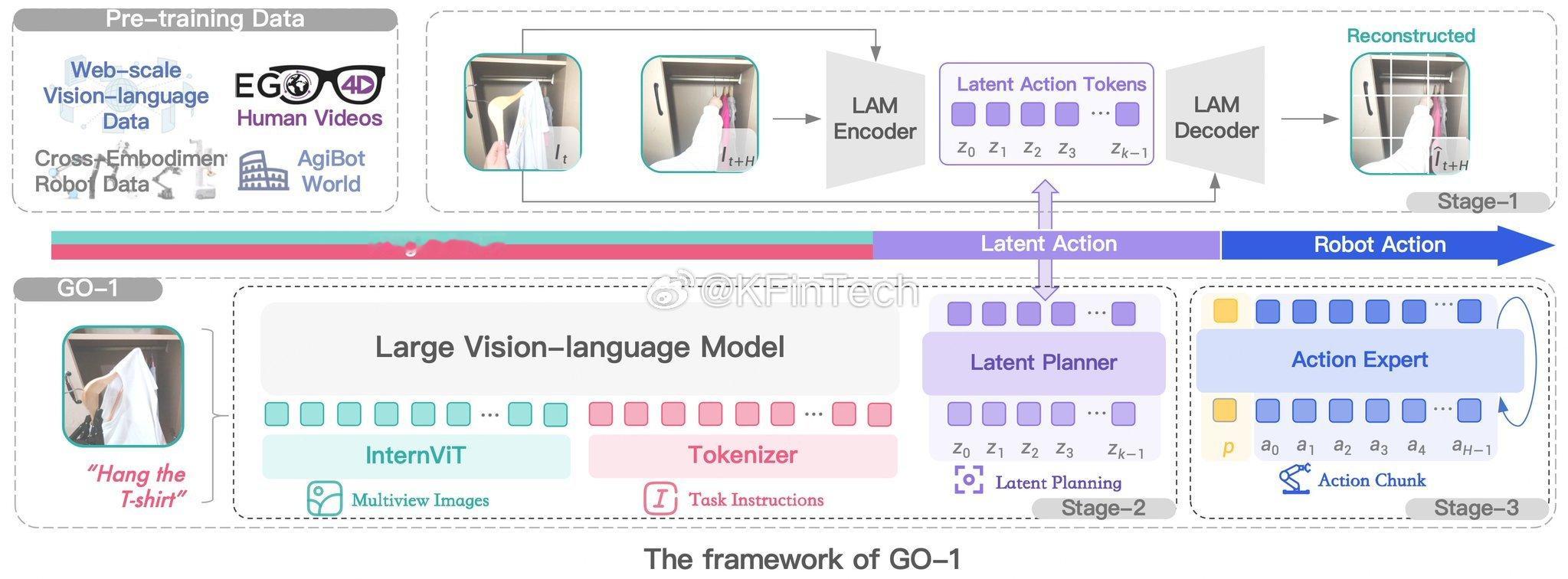
GO-1 框架,一个基于视觉-语言模型和**潜在动作建模(LAM)**的机器人学习系统。以下是其关键组成部分:
⸻
1. 预训练数据(Pre-training Data)
• 大规模视觉-语言数据(Web-scale Vision-language Data):包含大量的图像和文本数据。
• EGO4D 人类视频(Human Videos):来自 EGO4D 数据集,捕捉人类日常活动的第一人称视角视频。
• 跨载体机器人数据(Cross-Embodiment Robot Data):从多个不同的机器人平台收集的数据,以增强模型的泛化能力。
• AgiBot World:用于训练机器人的仿真环境。
⸻
2. 第一阶段(Stage-1):潜在动作建模(LAM)
• LAM 编码器(LAM Encoder):
• 处理连续帧图像,提取潜在动作标记(Latent Action Tokens)(Z₀, Z₁, …, Zₖ₋₁)。
• LAM 解码器(LAM Decoder):
• 通过这些潜在动作重建未来状态,帮助模型理解动作的演变。
⸻
3. 第二阶段(Stage-2):潜在规划(Latent Planner)
• 采用第一阶段生成的潜在动作标记进行规划。
• 结合视觉-语言指令和多视角图像,制定任务执行方案。
⸻
4. 第三阶段(Stage-3):动作专家(Action Expert)
• 将潜在动作转换为具体的机器人执行动作(a₀, a₁, …, aₕ₋₁)。
• 生成动作块(Action Chunk),以便机器人执行。
⸻
GO-1 执行流程示例
1. 机器人接收到指令:“挂起T恤”(Hang the T-shirt)。
2. 大型视觉-语言模型(InternViT) 处理 多视角图像 和 文本指令。
3. 潜在规划器(Latent Planner) 生成潜在动作。
4. 动作专家(Action Expert) 将潜在动作转换为具体的机器人执行动作。
⸻
关键特点
• 层次化学习(Hierarchical Learning):将规划(Stage-2)与执行(Stage-3)分开,提高泛化能力。
• 潜在动作表示(Latent Action Representation):使用潜在动作标记而非直接动作,使得机器人更加灵活和稳健。
• 多模态处理(Multimodal Processing):结合图像和文本来理解和执行任务。
这个框架使机器人能够执行复杂任务,并具备类人推理和规划能力。