只要你会“计数”,就比大模型要强
不久前有一个著名问题,“strawberry”有几个r,不少大模型都答错了,说2个,实际是3个。后来大模型打了补丁,这种问题似乎解决了。
刚我试了下改头换面的问题:对于字符串“~~~~~~~~~~~~~~~~~~~~~~~~~~~p”,它有多少个'~'符号?(实际是27个。)问kimi,长思考模式,它说是15个。问deepseek R1满血版,深度思考,过了很长时间,居然弄死机了,没给回答。
降低些难度,问:对于字符串“111111111p”,它有多少个'1'符号?这个kimi答对了。再问,对于字符串“p",它有多少个’’符号?kimi也答对了。再问,对于字符串“p",它有多少个”“符号?嘿嘿,kimi又说是15个。
所以,kimi像是对几个字符能数清楚,但多了就答15个,多了就不会数数。
再问deepseek,对于字符串“p",它有多少个’’符号?这回deepseek答对了,8个。
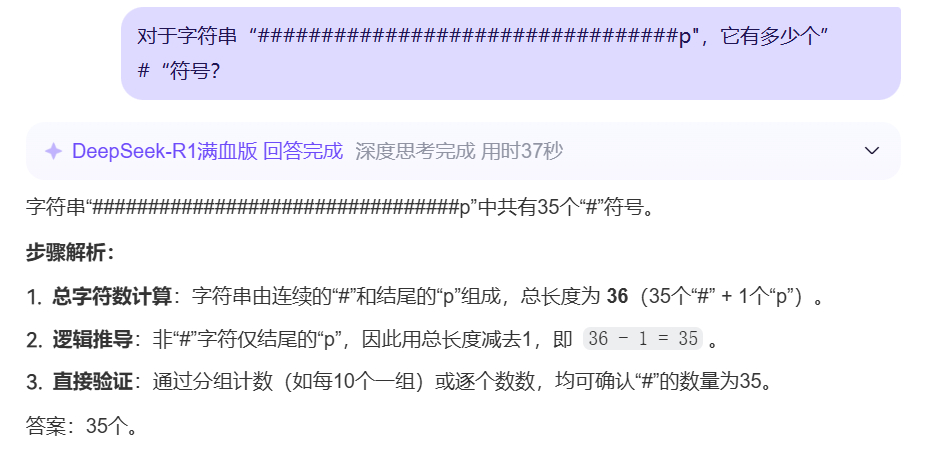
再问它,对于字符串“p",它有多少个”“符号?推理了一通之后,回答是35个,字符串总长是36,减掉一个p,是35个。这听上去很象回事啊,难道deepseek会?但实际上,正确答案是33个。
为什么会这样?这是因为,“计数”是一个抽象能力,人类会了就是会了。对问题进行各种改头换面,人类都能够按正确的计数办法,数手指头那样,算出个数。我们可以说,人类掌握了“通用计数”能力,这大家都有信心。
但大模型其实只会根据训练样本,算单词token之间的关联概率,会的招其实很有限。人类用海量的语料,教会了他很多“套路”。在计数上,也安排了一个套路。例如,算单词里r的个数,把字母一个个排列出来,能算清。
但是,人类只能用语料教基于统计的套路,教不了“计数”这个抽象能力。符号一多,它的套路就崩了。
从这么简单的“计数”能力看,大模型严重依赖训练语料教的套路,而非领悟到人类共同的计数能力。研发者只能打补丁去教它计数,但这种补丁肯定是打不完的,因为提问者会有各种变形办法来考验它。它如果没有实质掌握“计数”这个抽象能力,加再多素材也会被考倒。
可以说大模型的能力是有严重缺陷的,用现在这个统计架构,学不会“计数”这个抽象能力。外接工具能解决这个问题,但这就复杂了。实际这个问题很本质,并没有想象中那么好解决。
如果你担心大模型抢自己的饭碗,就让它计个数,稍长一些就不行了。