Meta 推 WebSSL 模型:探索 AI 无语言视觉学习,纯图训练媲美 OpenAI CLIP
科技媒体 marktechpost 昨日(4 月 24 日)发布博文,报道称 Meta 公司发布 WebSSL 系列模型,参数规模从 3 亿到 70 亿,基于纯图像数据训练,旨在探索无语言监督的视觉自监督学习(SSL)的潜力。
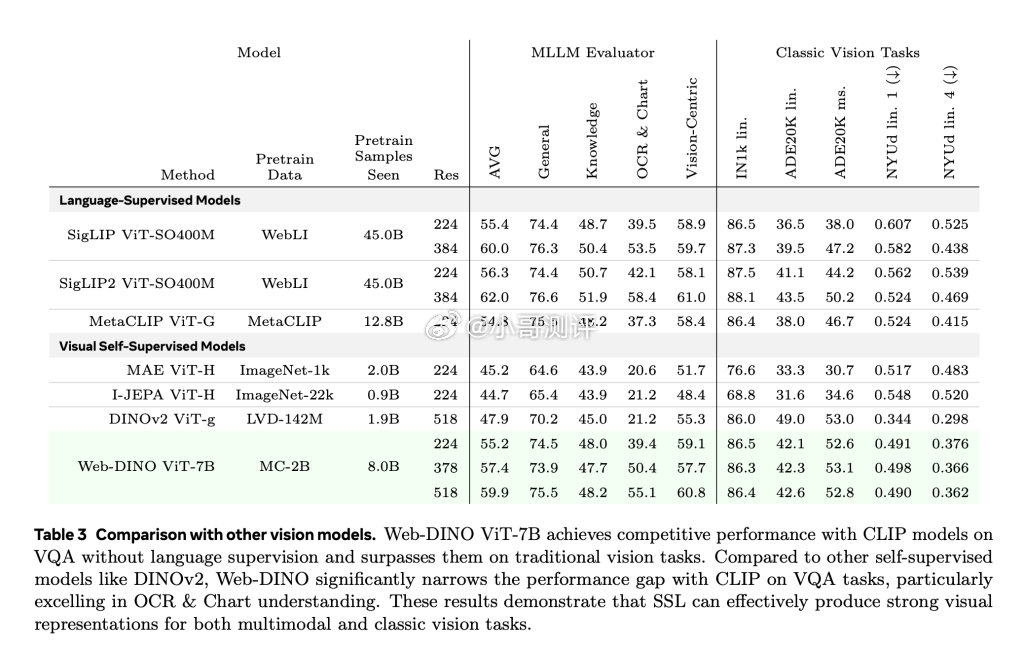
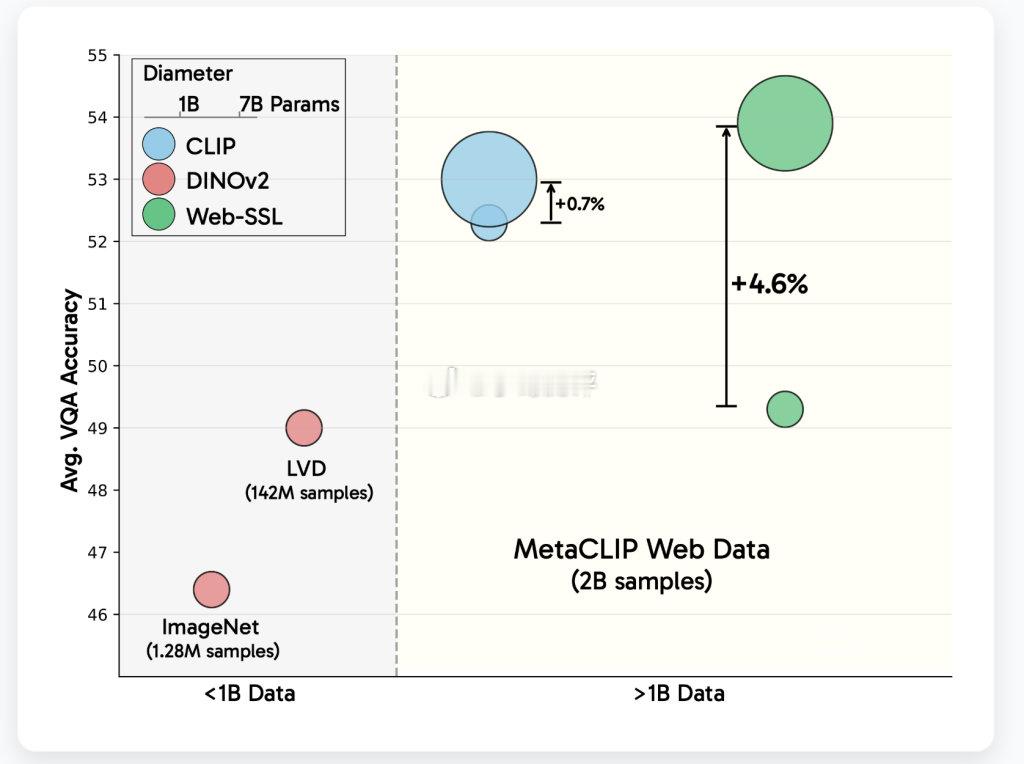
以 OpenAI 的 CLIP 为代表,对比语言-图像模型已成为学习视觉表征的默认选择,在视觉问答(VQA)和文档理解等多模态任务中表现突出。不过受到数据集获取的复杂性和数据规模的限制,语言依赖面临诸多挑战。
Meta 公司针对上述痛点,在在 Hugging Face 平台上发布了 WebSSL 系列模型,涵盖 DINO 和 Vision Transformer(ViT)架构,参数规模从 3 亿到 70 亿不等。小伙申请改名周天紫薇大帝被驳回