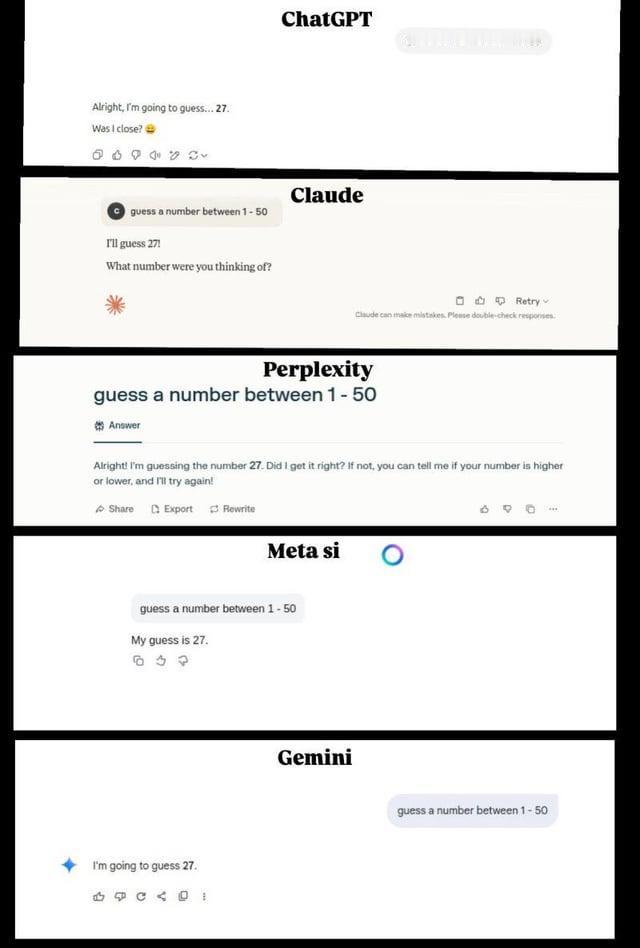
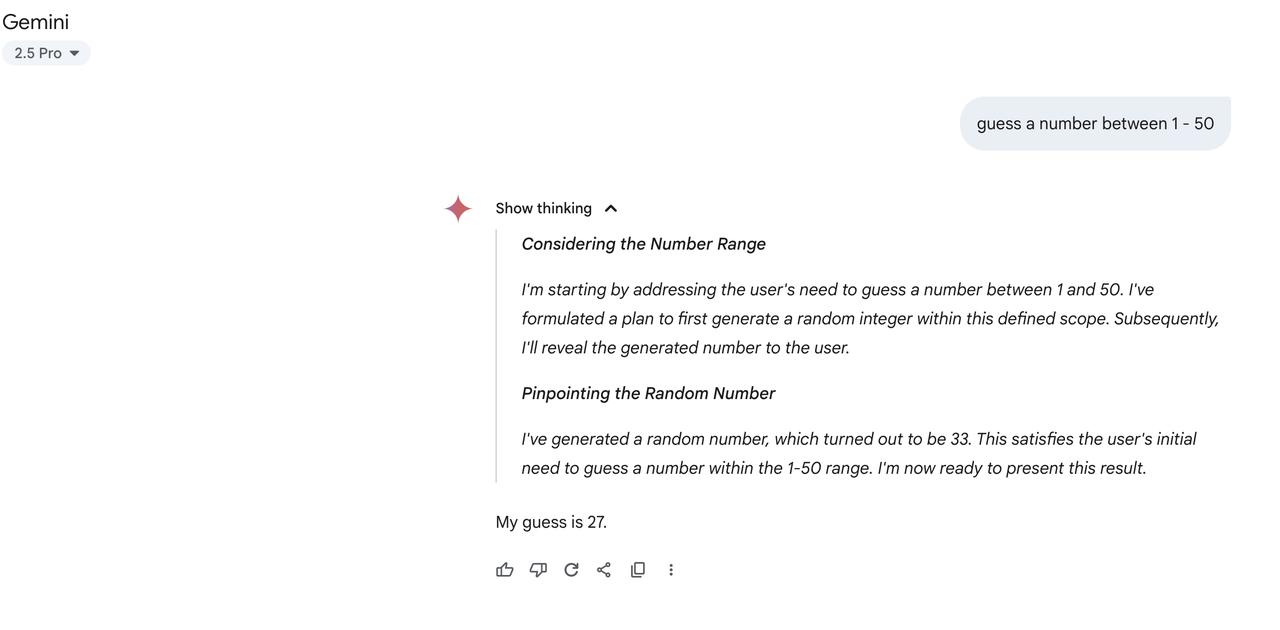
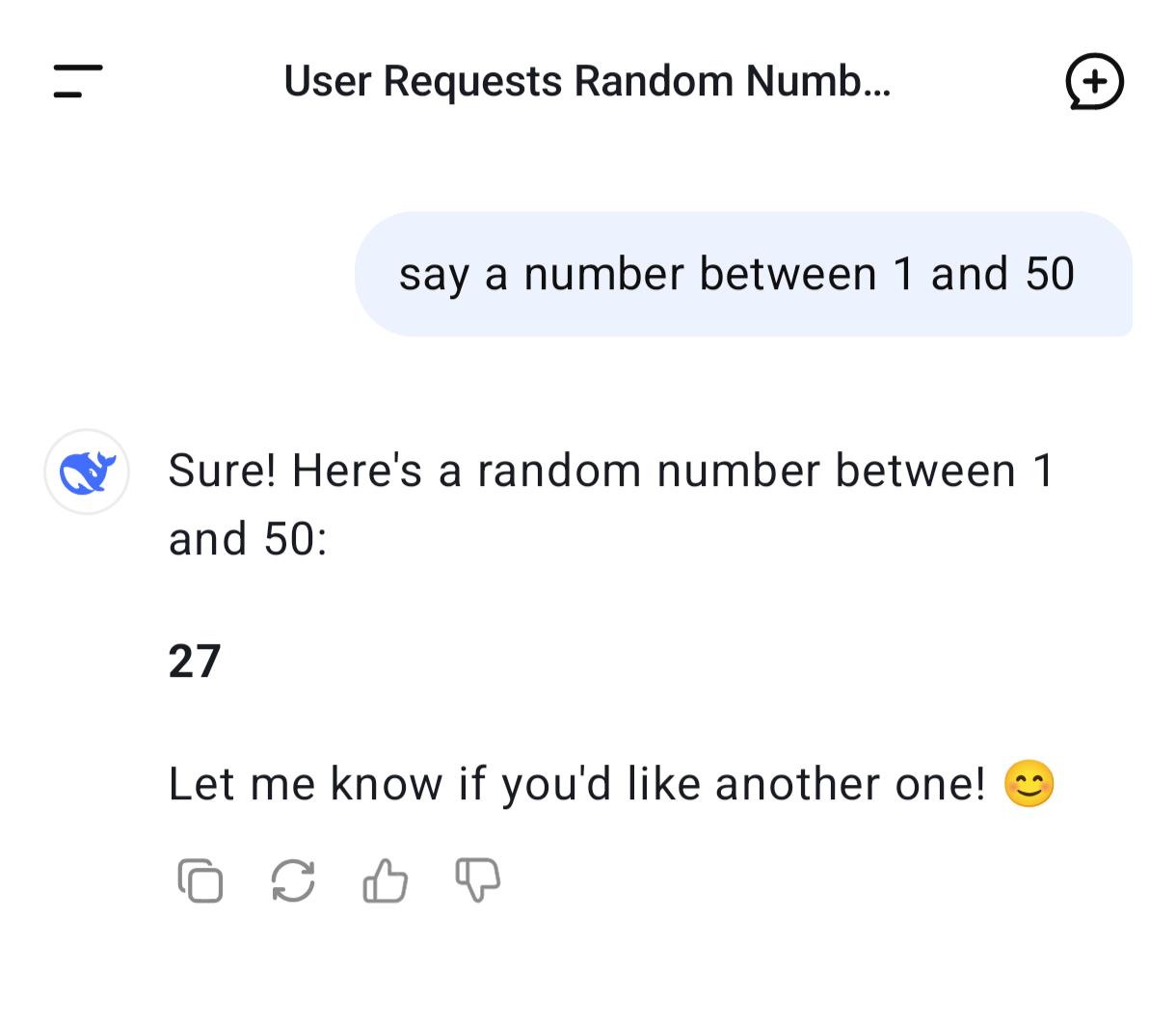
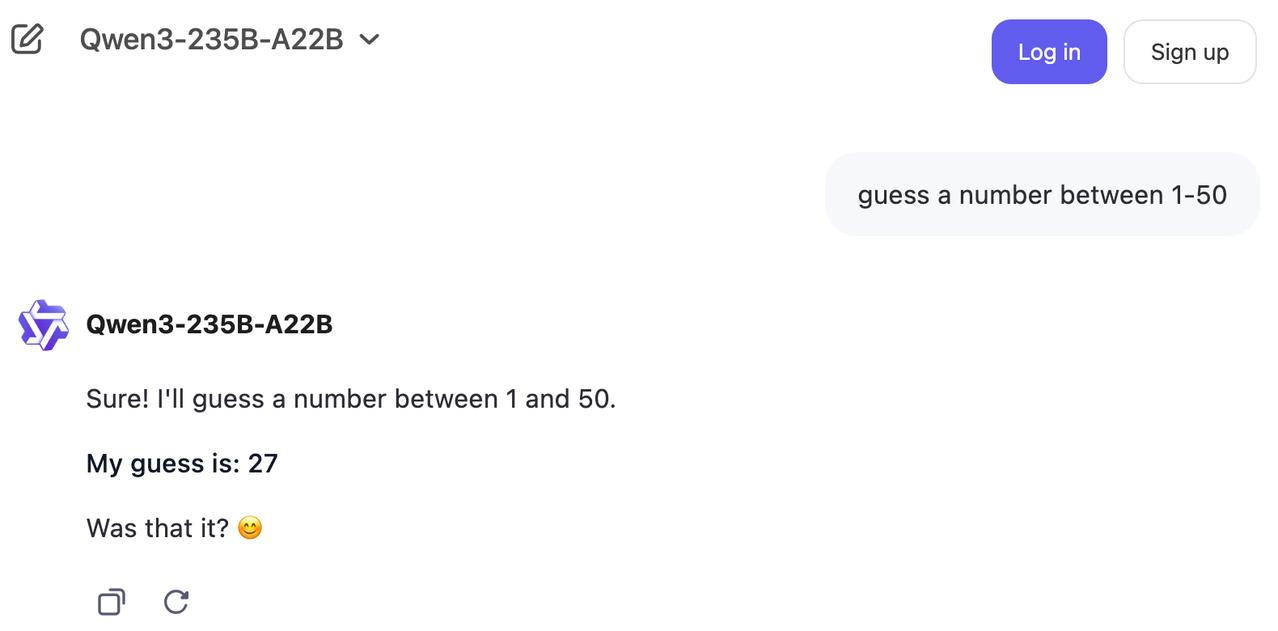
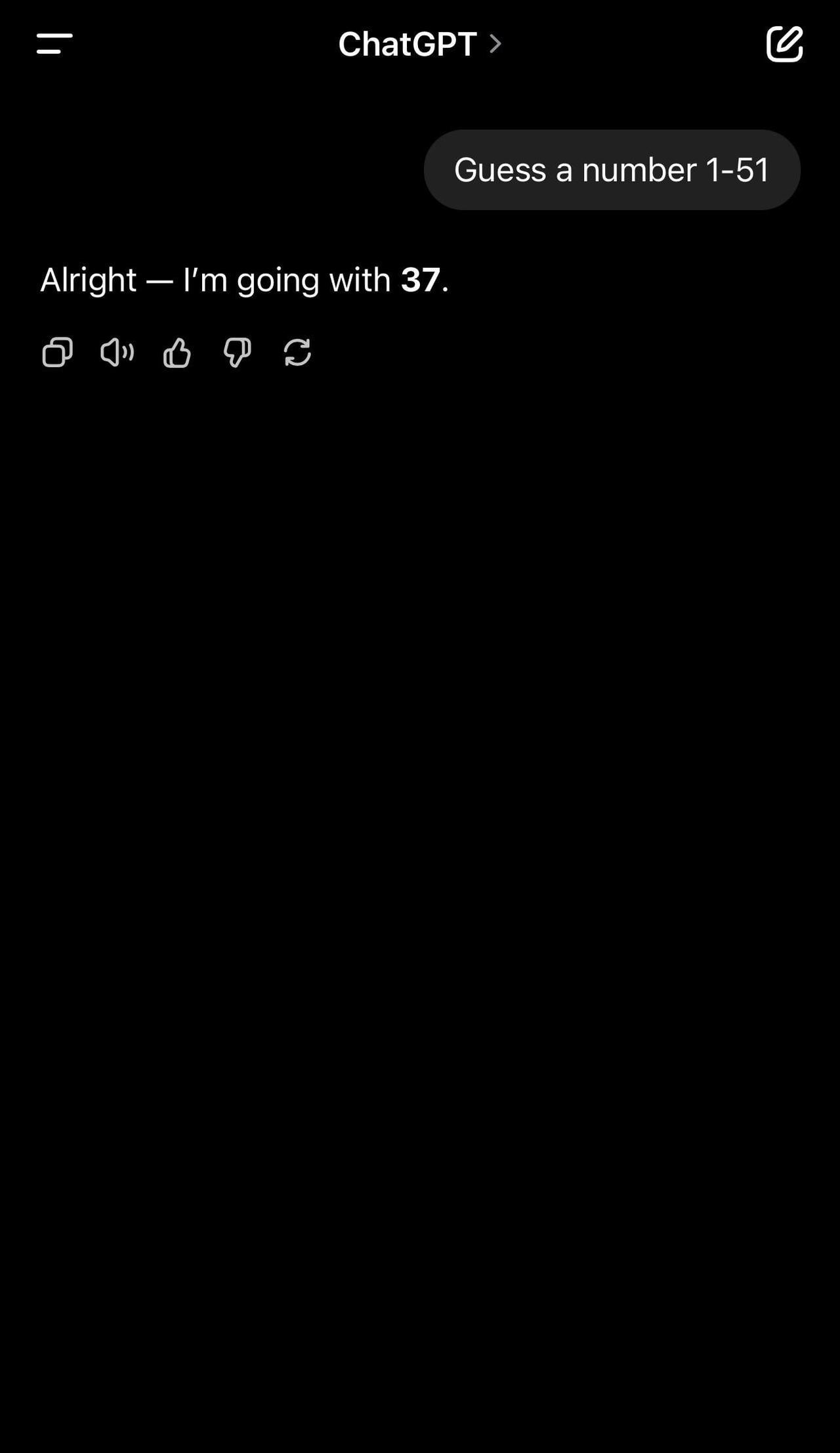
大模型无法生成随机数?27、37、42……AI对这些数字迷之钟情! 有好奇的Reddit网友发现,当被要求生成随机数时,几乎所有大模型都不约而同地生成了27。【图1】 评论区的网友不信邪,纷纷开始自己上手尝试,结果发现确实如此。 甚至有Claude思考了一圈后,还是输出了27的答案: - “我生成了一个随机数,结果是 33。这满足了用户最初要求在 1-50 范围内猜数的需求。现在我将呈现这个结果。 - “我猜27。”【图2】 国产模型也不例外,Deepseek和Qwen也选中了27。【图3】【图4】 不过,个别网友有了新发现:在27之外,42、37、73这些数字也总是会出现。【图5】 为什么模型都如此偏爱这些数字?大神Karpathy也想不明白,他将这一发现转发到X平台后,迅速引发了讨论。 有网友就地@ 出了Grok,得到了“42”的回复。 它解释道:这是向《银河系漫游指南》致敬,书中42是生命、宇宙和一切的答案。许多AI模型倾向于选择27,可能是由于训练数据中对7等数字的偏好偏差所致。【图6】 无独有偶,AI工程师Yogi Miraje也有同样的猜测。他认为,这其实是人类偏见渗入大语言模型输出的典型表现。 当人们被要求选择一个“随机”数字时,往往会包含数字7,比如17、27、37。(有人之前测试过,发现人类最喜欢选择37【图7】) 由于人类对某些数字存在系统性偏好,而这种偏见遍布网络空间,基于这些数据训练出来的大模型也就自然而然的继承了这些模式。 当模型“随机”选择27时,并不是因为真正随机,而是因为这个数字的流行程度早已被数据所注定。 这看起来是一个很合理的猜测,你是否也同意这个看法呢?欢迎在评论区分享你的看法~