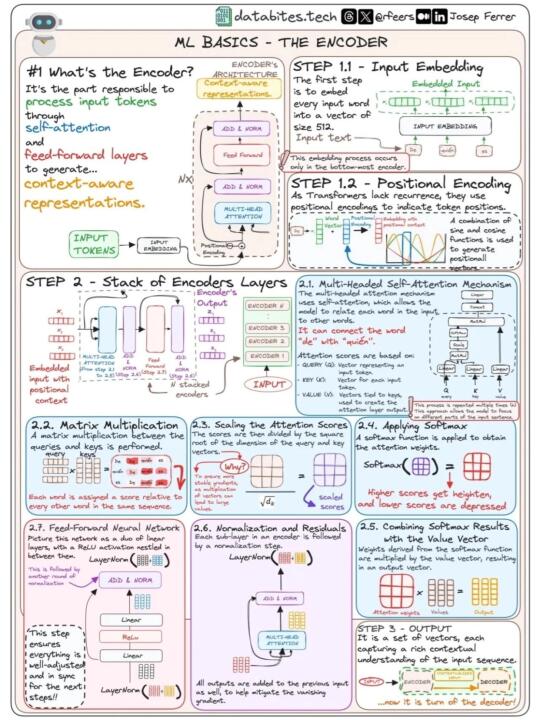
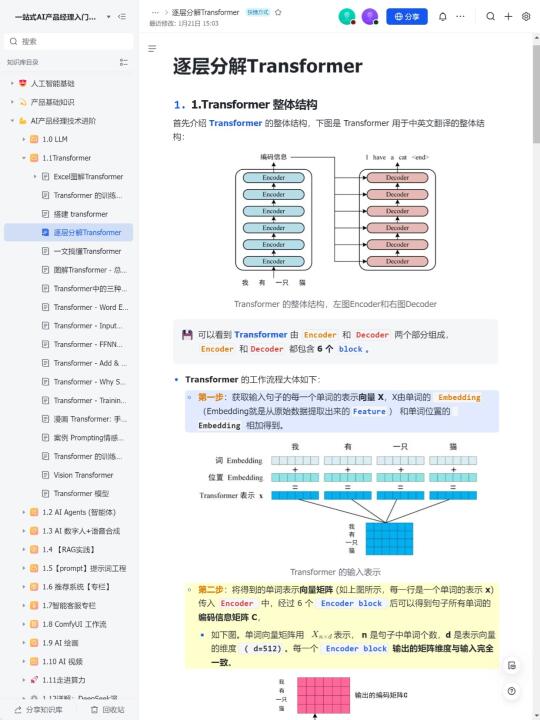
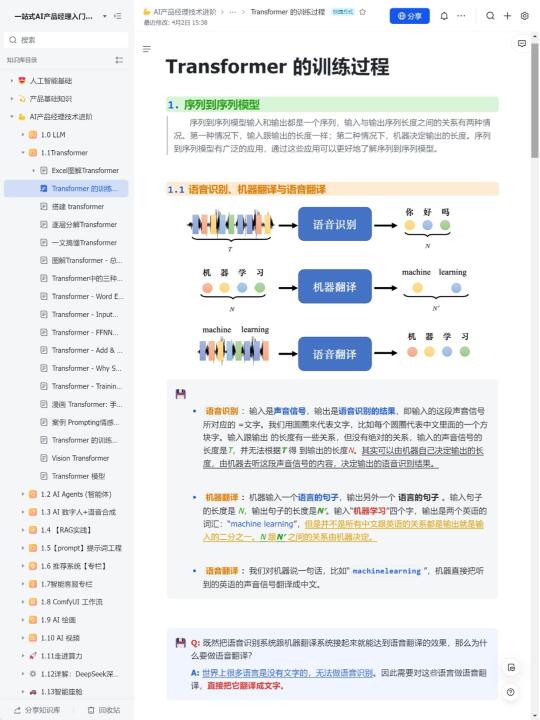
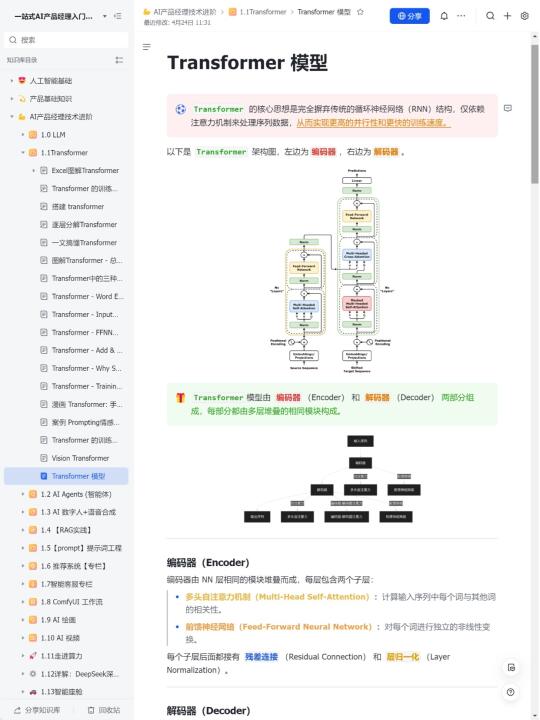
💡Transformer模型原理:
Transformer模型首次引入了自注意力机制,它可以在输入序列中的不同位置建立关联,使其在自然语言处理任务中表现出色。该模型由编码器和解码器组成,通过多层注意力机制实现信息传递和特征提取。
.
💡优点:
并行计算:Transformer模型支持高效的并行计算,适用于大规模数据和分布式训练
迁移学习:模型可以轻松用于不同的任务,通过微调预训练模型
自注意力:自注意力机制使其能够捕捉长距离依赖关系,适用于各种序列数据
⚠️缺点:
大规模数据和计算资源需求:需要大量训练数据和高性能硬件
对序列数据的局限性:在处理时间序列或音频数据时性能相对较差
.
完整的 Transformer 架构:
📚导入必要的库
🔗前馈网络
🧠多头注意力
📍位置编码和嵌入
🏗Transformer 层
📡参数设置和设备检育
📝数据生成函数
🧪数据加载器和训练准备
💪模型训练和测试
.
📍适应场景:自然语言处理、机器翻译、文本生成等序列数据任务