今天,华为720亿参数大模型首次开源!而且一次就推出两个版本。
一个是7B参数的盘古Embedded稠密模型,另一个是72B参数的盘古Pro MoE混合专家模型。
两个模型都针对昇腾NPU进行了深度优化,两者有什么亮点和区别呢?
盘古Embedded 7B模型亮点
1,支持任务复杂度自适应切换推理模式(快思/慢想)
2,模型具备元认知能力,能自主判断切换方式
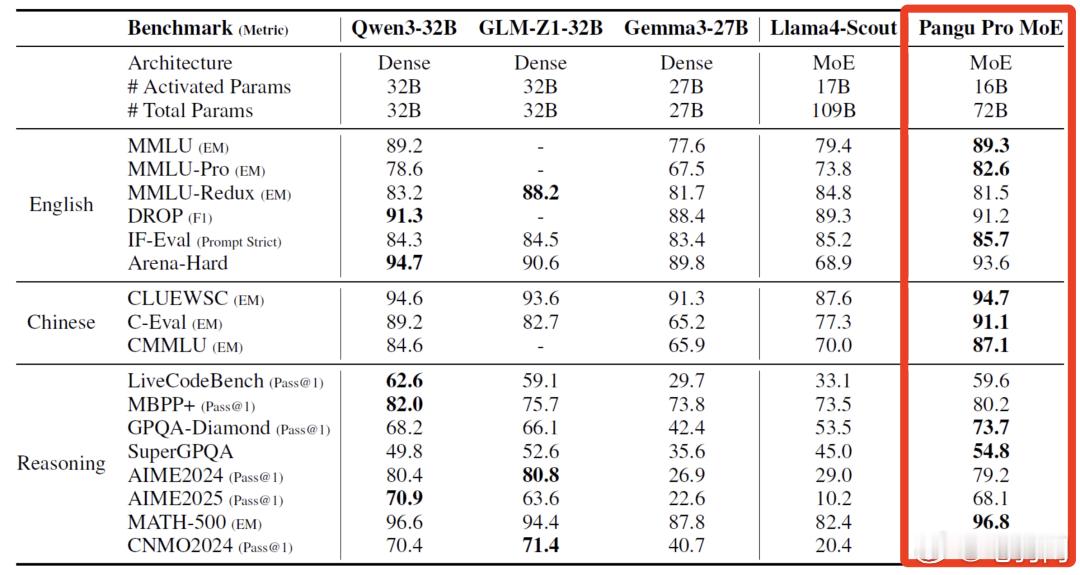
3,虽然是小体量70亿参数,但是能在AIME、GPQA等复杂任务中击败Qwen3-8B、GLM4-9B等同行模型
4,架构统一、部署更灵活!
盘古Pro MoE 72B模型则是基于自研MoGE(分组混合专家)架构,亮点有
1,激活参数量仅160亿,但是性能优于传统稠密72B
2,通过组内均衡激活解决专家负载不均问题
3,昇腾800I A2平台上推理速度最高可达1528 tokens/s
4,支持大规模并行训练,推理性价比高
目前,盘古Pro MoE的模型权重与推理代码已在开源平台上线了。
之前不是有人说用国产芯片没法训练大模型的吗,说只能做推理。现在华为直接出来证明了,四千卡昇腾集群同样能做大模型训练!