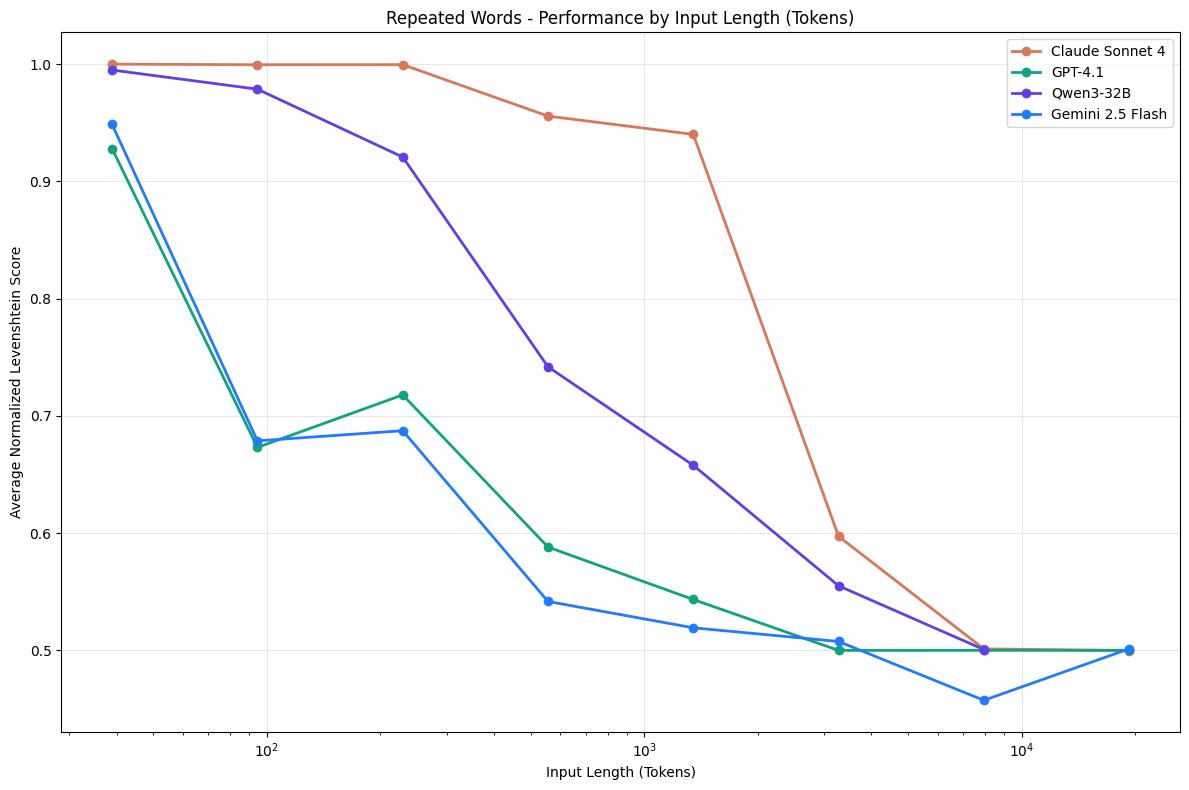
#模型读到一万tokens就失智##上下文太长大模型会降智# 上下文扩展至1万tokens,LLM集体“失智”! 且“智商”不是均匀下降,而是在一些节点突然断崖式下跌。 比如Claude Sonnet 4,就是在1000tokens后准确率一路下滑,从90%降到60%。 或者是下降后放缓再下降,比如GPT-4.1和Gemini 2.5 Flash。 最终,当上下文长度来到1万tokens,大家都只剩50%准确率。 这也就意味着,大模型在读同一本书第10页和第100页时的“智商”可能不一样。 并且不同大模型在“读这本书”时突然降智的页数也不同。 GPT-4.1可能读到第10页就“失智”了,Claude兴许能坚持到第100页。 这是Chroma团队的最新研究结论,他们用升级版“大海捞针”(NIAH)测试了包括GPT-4.1、Claude 4、Gemini 2.5和Qwen3等在内的18个开源和闭源的主流大模型。 结果显示,随着输入长度的增加,模型的性能越来越差。 实验还首次系统性地揭示了输入长度对模型性能并非均匀影响,不同模型性能可能在某一tokens长度上准确率发生骤降。 这项工作得到了网友的肯定: This effect is well known but not well documented so far, so great job here. 这种效应虽然广为人知,但至今尚未得到充分记录,因此你的工作非常出色 以往人们或许会遇到当输入长度增加时大模型会出现性能不佳的情况,但并没有人深入探究过这个问题。 目前代码已开源,感兴趣的小伙伴可点击:github.com/chroma-core/context-rot