模型蒸馏的本质与深层洞察:如何让学生模型超越教师模型
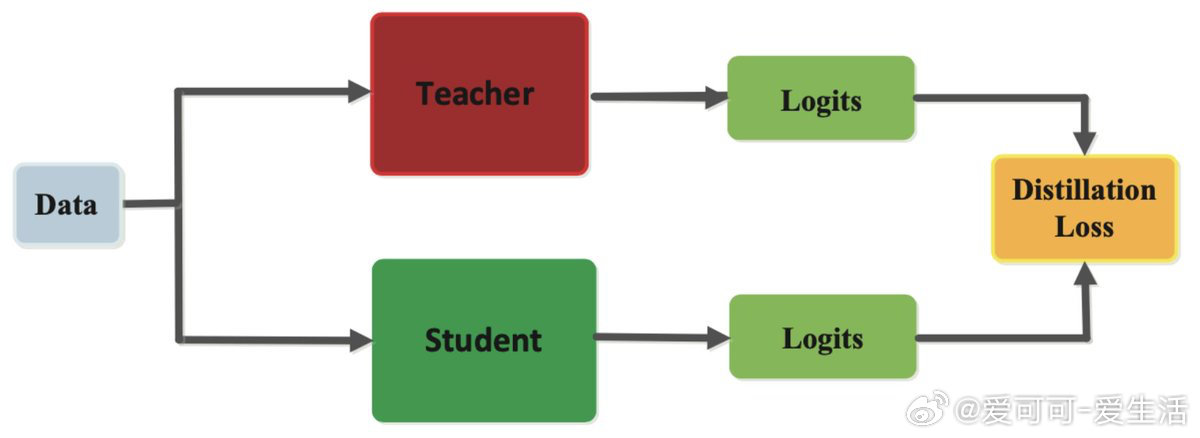
• 原理简述:通过教师模型 T 产生的 logits 监督学生模型 S,使 S 学习复刻 T 输出的概率分布,而非单一标签,训练目标更丰富,L2 损失常用
• 信息丰富性:蒸馏信号包含多类别软标签(如图中“原声吉他”图像同时隐含“电吉他”“舞台”等信息),学生模型能识别未标注类别,实现泛化能力提升
• 数据需求降低:学生模型仅需教师数据的少量(如 Hinton 仅用 3% 数据),因其学习的是类别概率分布而非硬标签,信息密度更高,收敛更快
• 超越教师的原因:教师模型可能因噪声和错误标签受限,学生模型仅复制教师输出的概率分布,避免了原始标签的噪声影响,性能反而优于教师
• 训练数据本质:学生模型实际学习的是教师模型生成的 logits 而非原始输入标签,标签仅是输入数据的一部分,蒸馏等同于从教师知识中“提炼”训练数据
深刻认识蒸馏过程,理解学生模型如何借助教师模型的丰富知识实现数据高效利用与性能提升,是设计高效模型压缩与迁移学习方案的关键。
详情🔗 x.com/gabriberton/status/1948724593407000699
参考论文🔗 arxiv.org/abs/1503.02531
相关研究🔗 arxiv.org/abs/2106.05237
机器学习 模型蒸馏 知识迁移 深度学习 人工智能