为什么《Designing Data-Intensive Applications》是每位系统设计者必读的经典?
Milan Milanović 读了两遍,深刻体会到它不仅传授技术细节,更彻底改变了他对数据系统设计的认知框架。以下是他认为这本书的核心价值与详细解析:
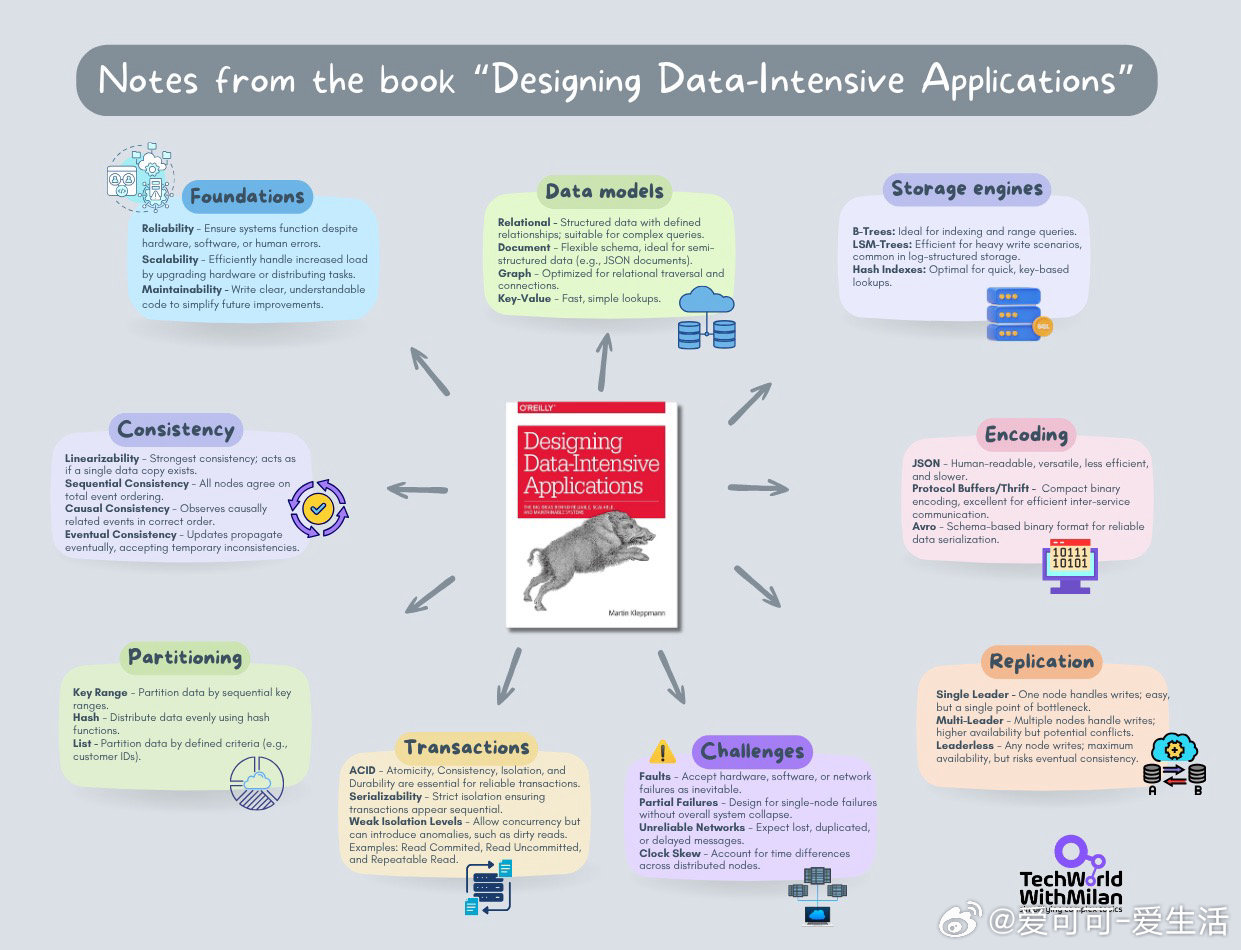
一、重新理解数据系统背后的设计动因与权衡
• 存储引擎差异:
- B-tree(如 PostgreSQL、MySQL)优化读取,支持快速查找与范围查询,采用原地更新数据页,写入延迟较高但读性能优越。
- LSM-tree(如 Cassandra、RocksDB)优化写入,通过顺序写入和后台合并实现超高写入吞吐,但读取时需查找多个数据文件,读性能折中。
这看似简单的设计权衡,决定了数据库在不同场景下的表现差异。
• 复制策略差异:
- 单主复制(MongoDB、PostgreSQL常用)简化写冲突处理,保证写入顺序一致,易于故障恢复。
- 多主复制虽然提供多点写入能力,但带来复杂的写冲突和合并难题,适用场景有限。
- 无主复制(Dynamo、Cassandra)通过仲裁机制实现高可用,但必须接受最终一致性和复杂的冲突解决。
• 数据模型选择:
- 关系型数据库适合复杂关联查询和事务保证。
- 文档型数据库适合灵活模式和自包含数据。
- 图数据库适合复杂多对多关系。
选择数据库应基于应用场景的数据访问模式,而非盲目跟风。
二、系统设计的三大核心原则
• 可靠性(Reliability):系统在硬件故障、软件缺陷和人为错误情况下依然保持正确运行。
• 可扩展性(Scalability):系统能高效应对负载增长,通过扩容硬件或任务分布确保性能。
• 可维护性(Maintainability):代码清晰、易管理,便于长期演进和快速故障排查。
对这三点的权衡贯穿全书,强调“设计即为权衡”,没有绝对完美的方案。
三、分布式系统的复杂性和设计挑战
• 部分失败(Partial Failures)是分布式系统的常态,必须设计无单点故障的容错机制。
• 网络不可靠,消息可能丢失、重复或乱序,系统需设计相应补偿策略。
• 时钟同步难题,不同节点时钟漂移导致事件排序不一致,需结合逻辑时钟或特定协议(如Google TrueTime)解决。
• 领导者选举与分裂脑(Split-Brain)问题,引入 fencing token 等方案保障一致性。
• 拜占庭容错虽复杂但对某些关键领域至关重要,书中介绍基本思路。
四、事务与一致性模型的深度讲解
• 事务的四大ACID特性及其分布式实现难点。
• 弱隔离级别和强隔离级别的区别,及其对并发控制的影响。
• 线性一致性(Linearizability)与串行化隔离(Serializability)的区别,澄清常见误区。
• CAP定理的权衡与系统实际应用,理解何时优先可用性或一致性。
• 共识算法(Raft、Paxos)简明介绍,帮助理解分布式协议设计。
五、数据流与流处理的现代视角
• 批处理与流处理的核心差异:吞吐优先 vs 低延迟优先。
• 利用日志(Log)作为数据变更的统一抽象,推动事件驱动架构。
• 事件溯源(Event Sourcing)模式,状态由事件序列驱动,便于审计和回溯。
• 实时数据管道设计,CDC(Change Data Capture)技术及其应用。
• 介绍流处理框架与消息系统(Kafka、RabbitMQ等),虽略显简略但打下基础。
六、读者建议与适用范围
• 理想读者:具备3-8年经验的工程师、架构师和技术负责人,尤其是涉及分布式系统、大数据管道设计者。
• 适用场景:系统设计面试准备、架构方案决策、技术路线规划。
• 不适合:初学者、缺乏分布式基础知识者、希望快速实操教程的人。
七、书中不足与补充建议
• 例子较为陈旧,缺少近年云原生、Serverless、Flink等最新技术覆盖。
• 理论偏重,缺少代码示例与实操指导。
• 部分章节信息密集,阅读门槛较高,需要反复研读。
• 缺少迁移策略、生产环境运维监控、备份恢复等实务内容。
• 推荐结合其他资源(如 Alex Petrov 的《Database Internals》)深挖细节。
总结
这本书是构建可靠、可扩展且易维护数据系统的理论基石,帮助你从“知道是什么”跃升到“理解为什么”。每一个架构决策都能基于清晰的权衡和原则,不再盲目跟风或迷失于技术流行趋势。它既验证了我多年经验,也带来了全新的思考视角,成为我设计系统时不可或缺的参考书。
想深度掌握分布式数据系统的设计精髓,理解背后的权衡与原理,这本书绝对值得投入时间。
完整详解👉 newsletter.techworld-with-milan.com/p/what-i-learned-from-the-book-designing
分布式系统 数据库 系统设计 大数据 架构师必读 软件工程