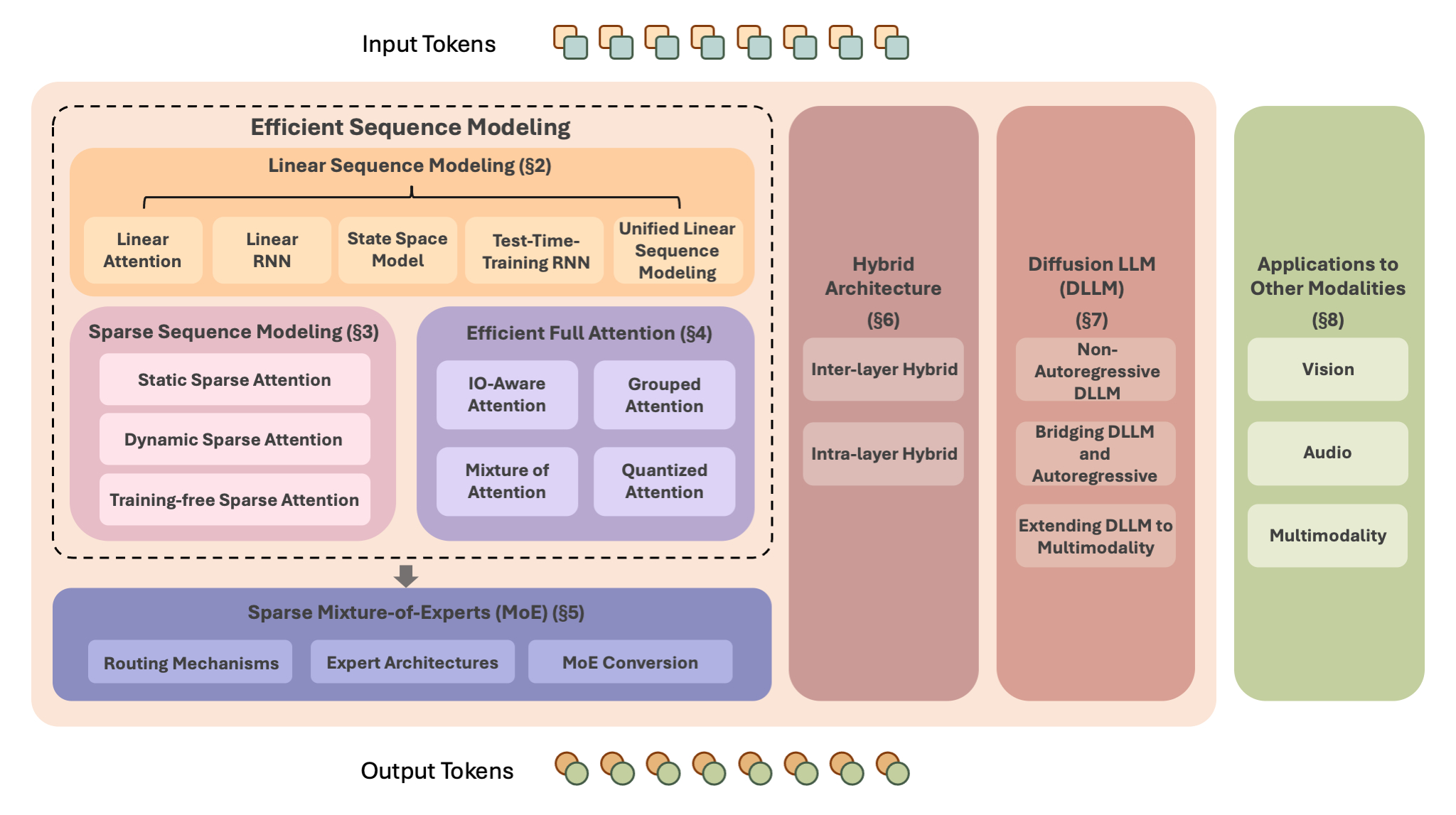
一篇《速度为王:大语言模型高效架构综述》的论文,系统地梳理了当前为了克服传统Transformer架构计算成本高昂、部署困难等问题而涌现的各类创新模型架构 。
论文:arxiv.org/abs/2508.09834
另外还有一个配套的github库,记录了里面研究过的449 篇论文的地址和发表时间等信息:github.com/weigao266/Awesome-Efficient-Arch
论文的核心内容围绕几大关键技术方向展开:
🌟序列建模的效率优化:探讨了旨在将注意力机制的计算复杂度从二次方降低到线性的线性序列建模(如线性注意力、线性RNN、状态空间模型SSM等),以及通过让信息选择性交互来减少计算量的稀疏序列建模 。
🌟注意力机制自身的改进:介绍了在保留完整注意力机制的同时,通过IO感知(如FlashAttention)、分组查询(如GQA/MQA)等技术提升其运行效率的方法 。
🌟模型结构的革新:分析了稀疏混合专家模型(MoE)如何通过仅激活部分“专家”参数来扩大模型规模而不增加计算量 ,讨论了融合多种高效组件的
🌟混合架构 ,并介绍了新兴的、具备并行生成能力的
🌟扩散大语言模型(Diffusion LLM) 。