[CL]《Reasoning-Intensive Regression》D Tchuindjo, O Khattab [MIT] (2025)
推理密集型回归(RiR)揭示了大语言模型(LLMs)在精确数值预测与深度序列推理之间的矛盾,提出了突破现有限制的创新方案。
• RiR任务区别于传统语言回归,要求模型对每条文本进行逐步推理,涉及数学错误检测、检索增强生成(RAG)对比及作文评分三大典型场景,体现了推理深度与数值精度的双重挑战。
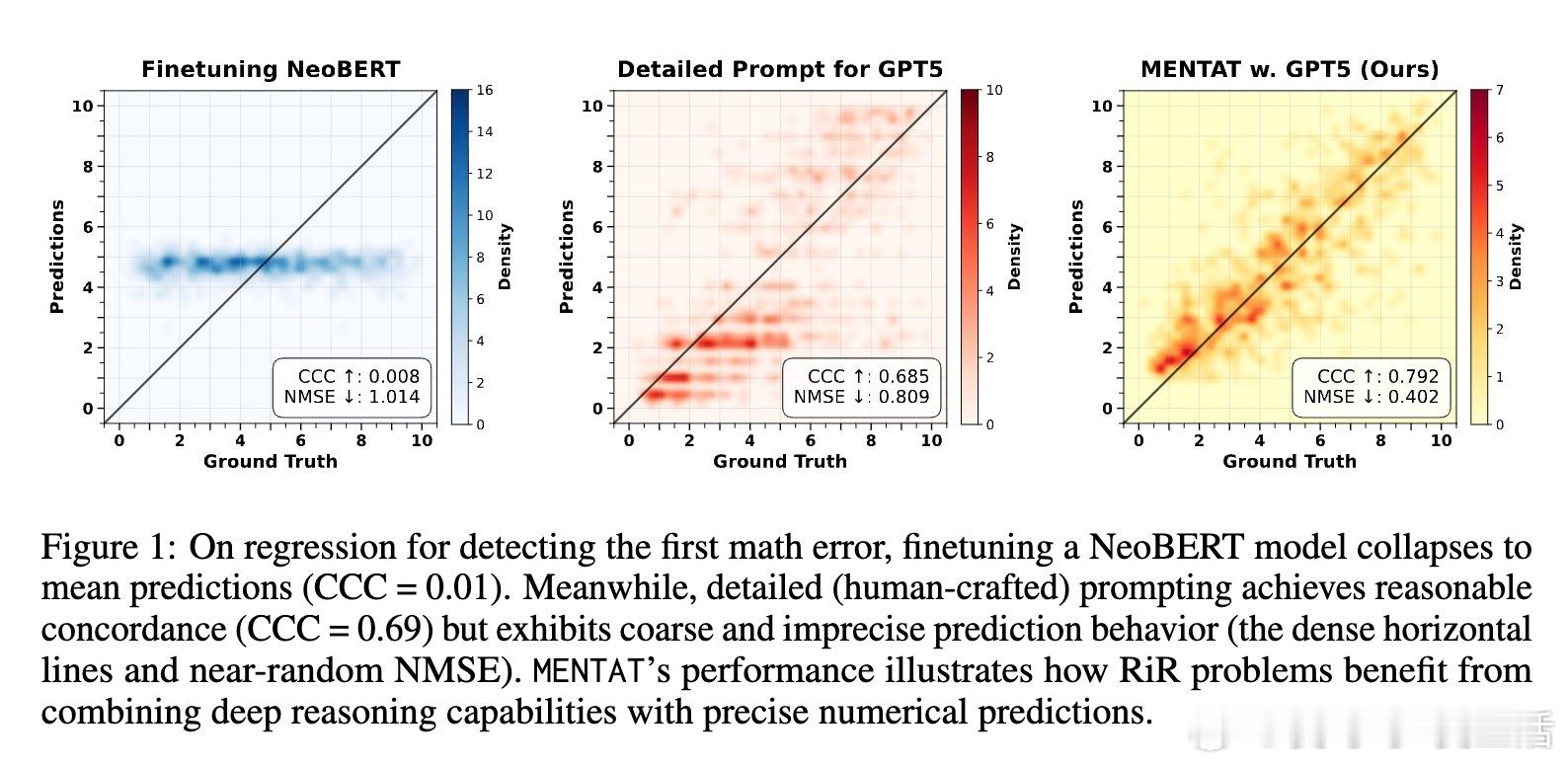
• 标准微调Transformer编码器往往陷入预测均值陷阱,表现出极低的CCC(如NeoBERT数学错误检测CCC仅0.01),难以捕捉推理逻辑。
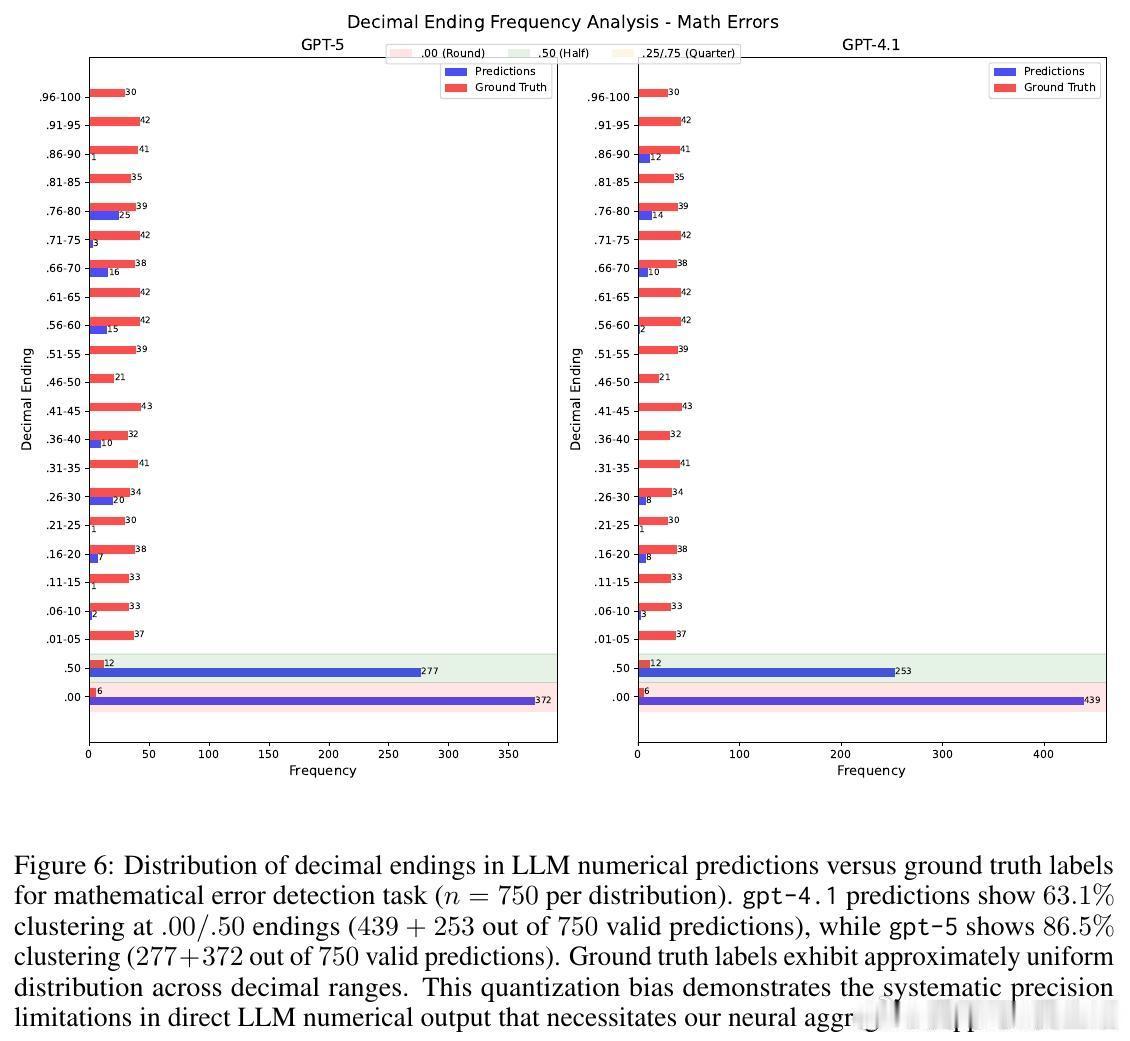
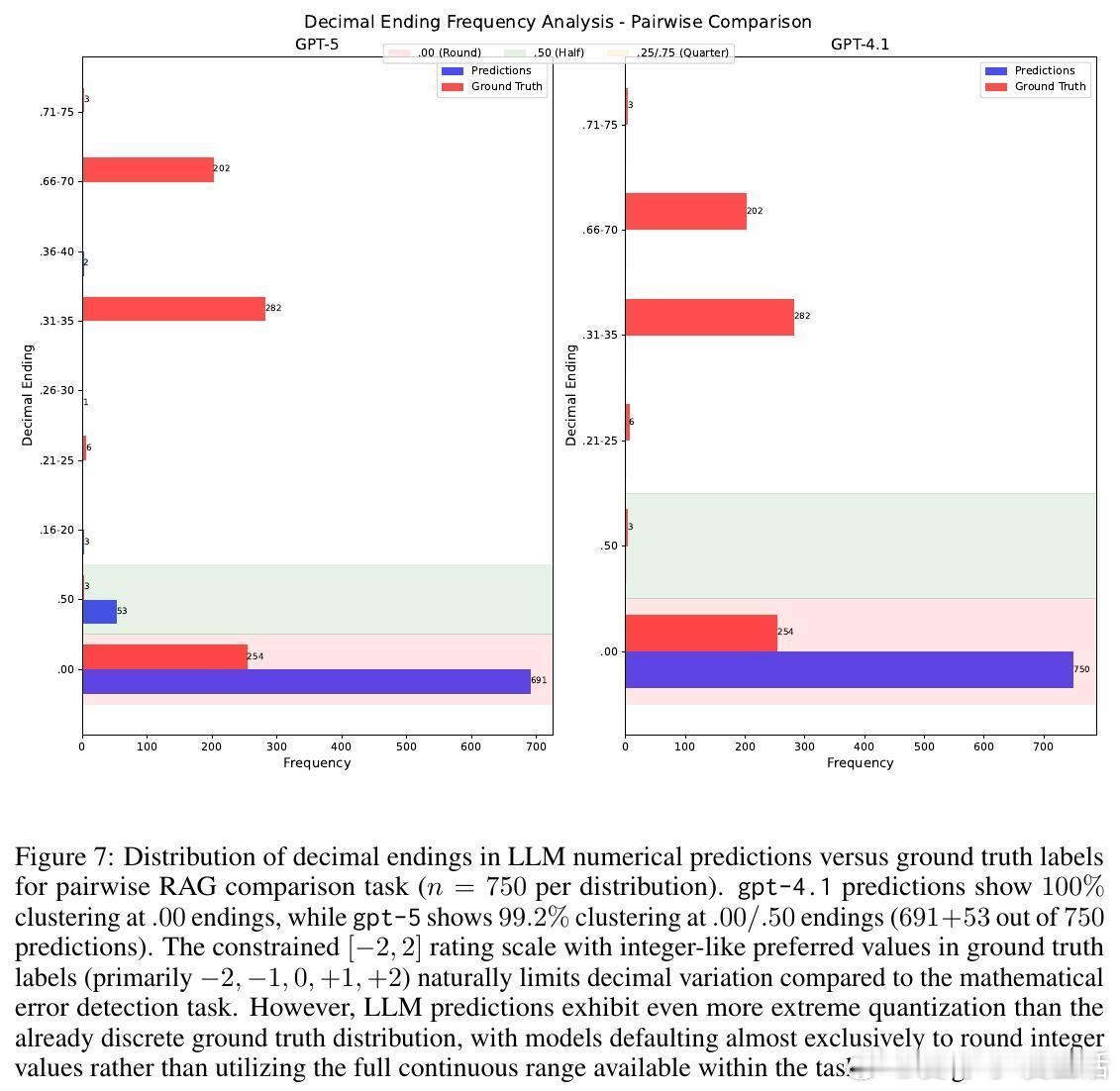
• 直接Prompting大语言模型虽能展现较好推理能力(如GPT-5详细提示数学错误检测CCC达0.69),却因输出数值量化严重(高达86.5%的预测结果集中于整数或0.5倍数)导致回归精度不足。
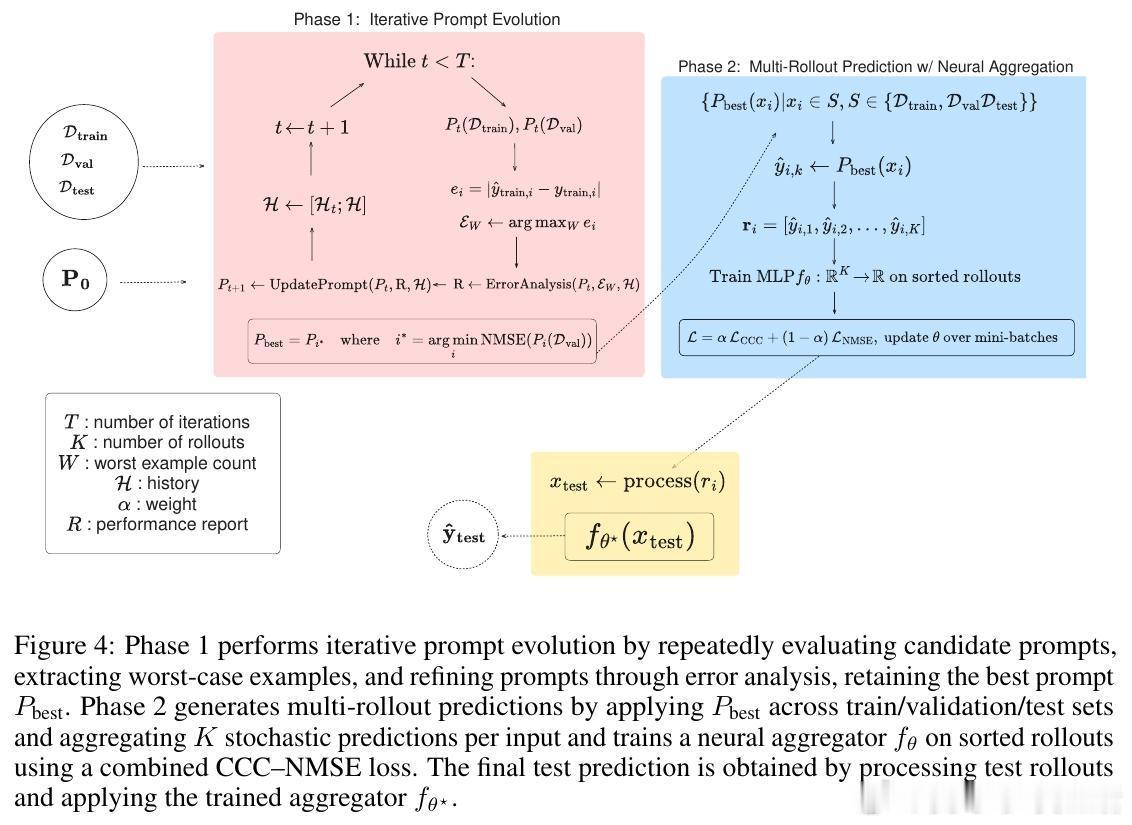
• 创新方法MENTAT结合了批量错误驱动的提示演化与多次生成结果的神经网络聚合,显著提升了数值预测的准确度和排序一致性,在有限数据(100-500样本)下对所有RiR任务均实现最高CCC和最低NMSE。
• MENTAT第一阶段通过LLM自我反思批量错误,迭代优化提示语,第二阶段利用多次独立生成的预测结果训练MLP进行集成,兼具推理深度和数值精度。
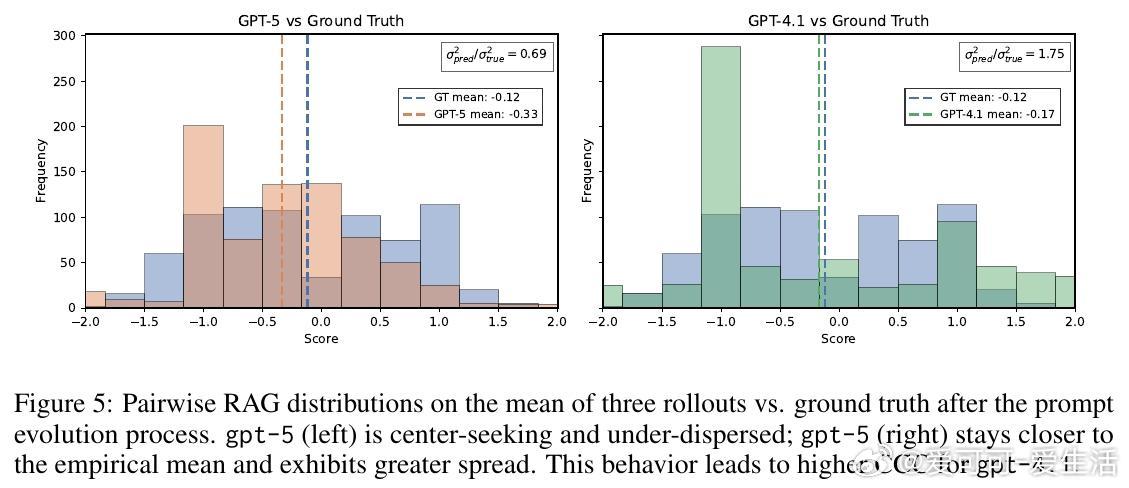
• 研究揭示高级推理模型在简单任务(如RAG对比、作文评分)中可能因“过度思考”反而表现逊色,提示任务复杂度与模型推理能力应匹配。
• RiR评估指标强调CCC以兼顾预测的相关性与一致性,弥补传统NMSE对极端值预测回避的偏差。
• 该工作为轻量级、低样本、可扩展的推理密集型回归提供了实践基线与方法框架,强调融合推理能力与数值回归的必要性,指明未来研究方向。
心得:
1. 纯提示工程与传统微调各自存在局限,融合两者优势是解决推理与精度矛盾的关键。
2. 批量错误分析与多次输出聚合提升了模型对复杂推理任务的适应性和稳定性。
3. 不同任务的推理深度需求差异显著,模型设计需针对具体任务灵活调整推理策略。
详情🔗arxiv.org/abs/2508.21762
大语言模型推理密集型回归机器学习自然语言处理模型优化