[CL]《LLM-JEPA: Large Language Models Meet Joint Embedding Predictive Architectures》H Huang, Y LeCun, R Balestriero [Atlassian & NYU & Brown University] (2025)
LLM-JEPA:语言大模型迈入联合嵌入预测架构的新纪元
• 创新融合:首次将视觉领域成功的JEPA(Joint Embedding Predictive Architectures)训练目标引入大型语言模型(LLM),结合传统的自回归生成损失,实现更强的表征学习能力。
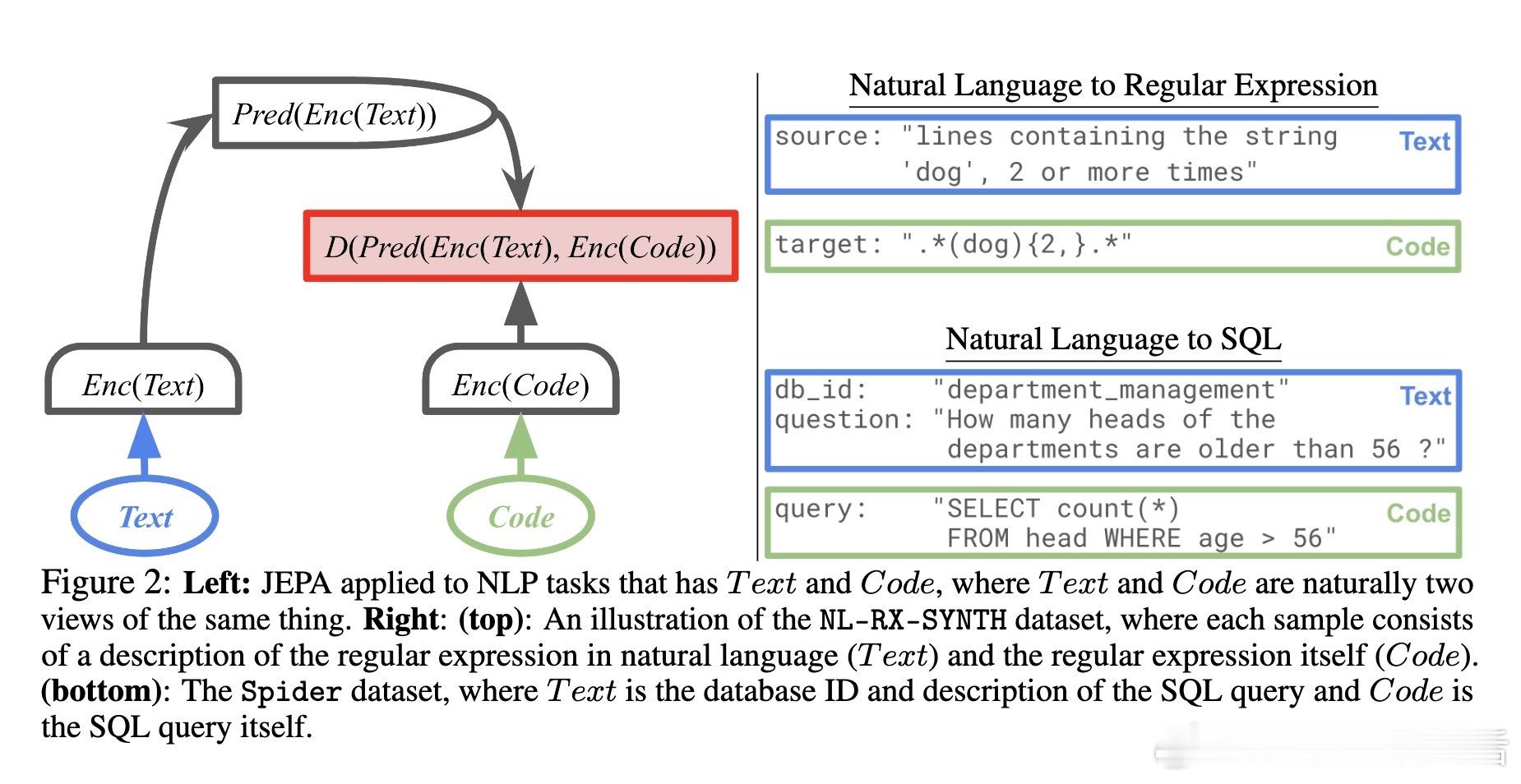
• 多视角利用:通过设计文本与代码等多视角(views)输入对,LLM-JEPA在嵌入空间中预测不同视角间的表示,提升模型对抽象语义的捕捉能力,同时保持生成性能。
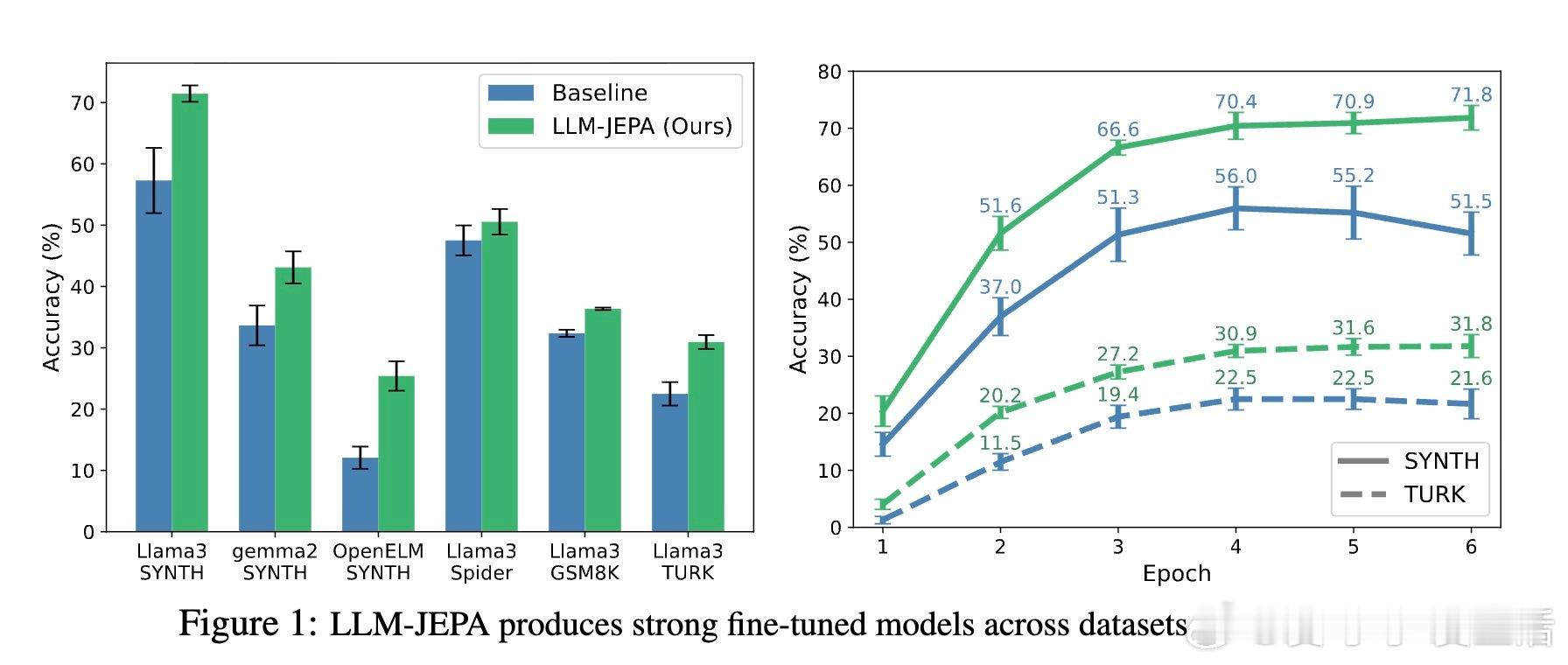
• 显著性能提升:在多模型(Llama3、Gemma2、OpenELM、Olmo)和多任务(自然语言转正则表达式、SQL解析、数学推理等)上均表现出超过传统LLM训练的准确率和泛化能力。
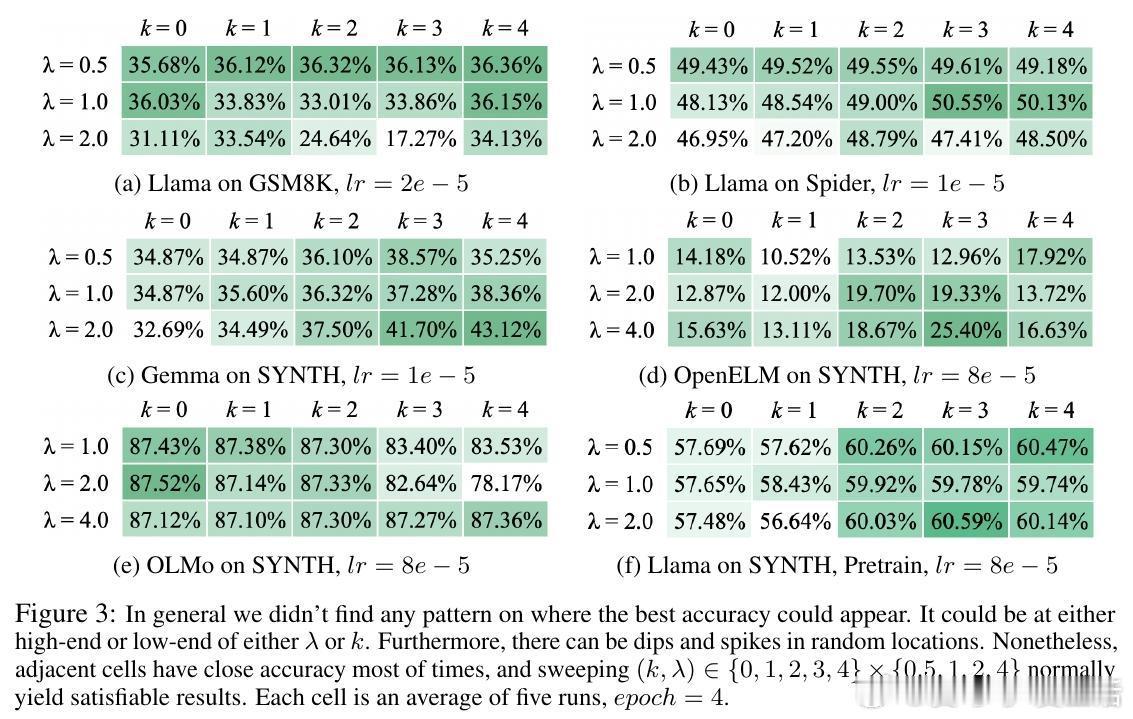
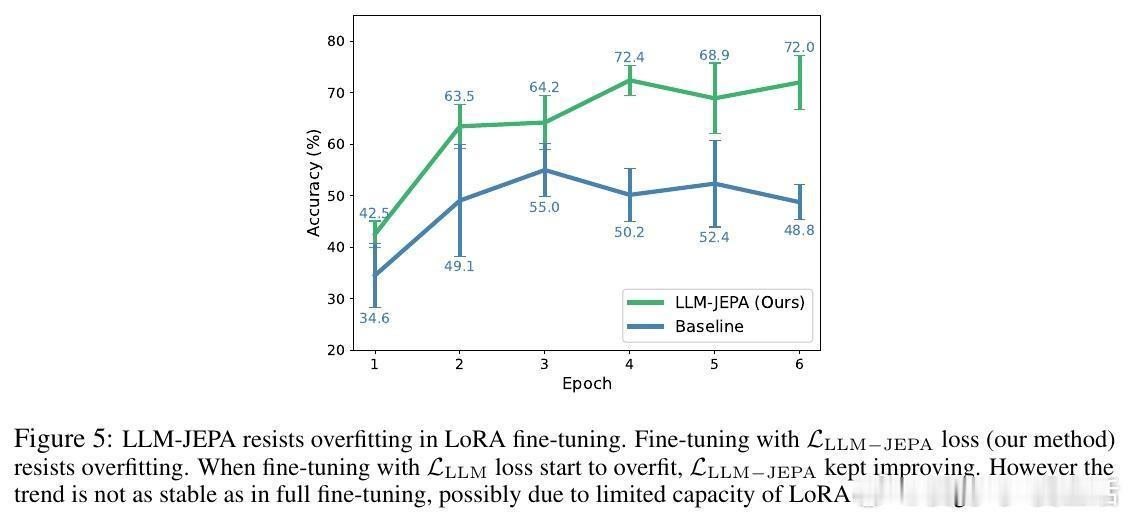
• 抗过拟合优势:LoRA微调实验显示,LLM-JEPA可以有效抑制过拟合现象,训练过程更稳定,收敛速度更快,且在低秩参数调整下性能依然优异。
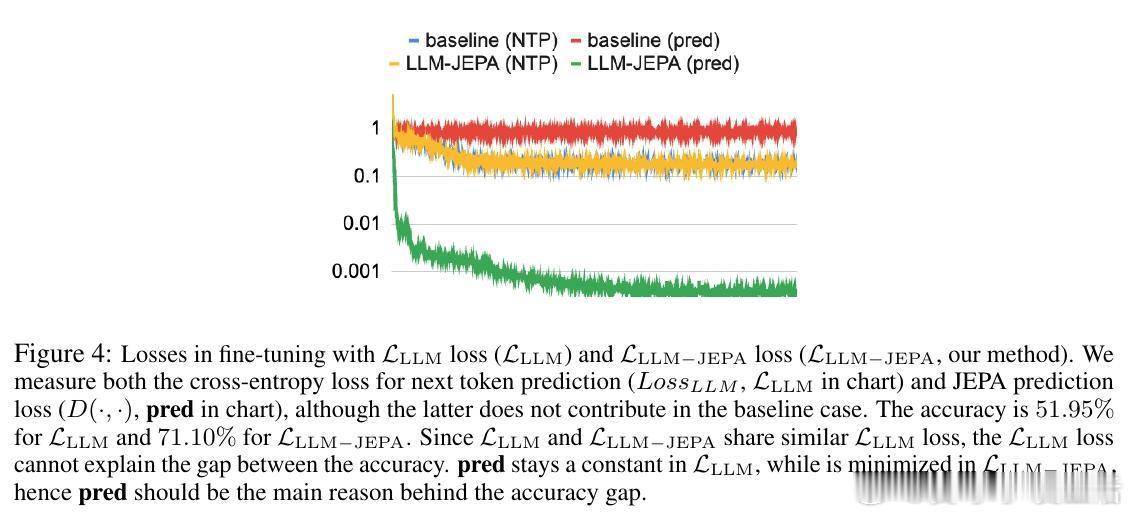
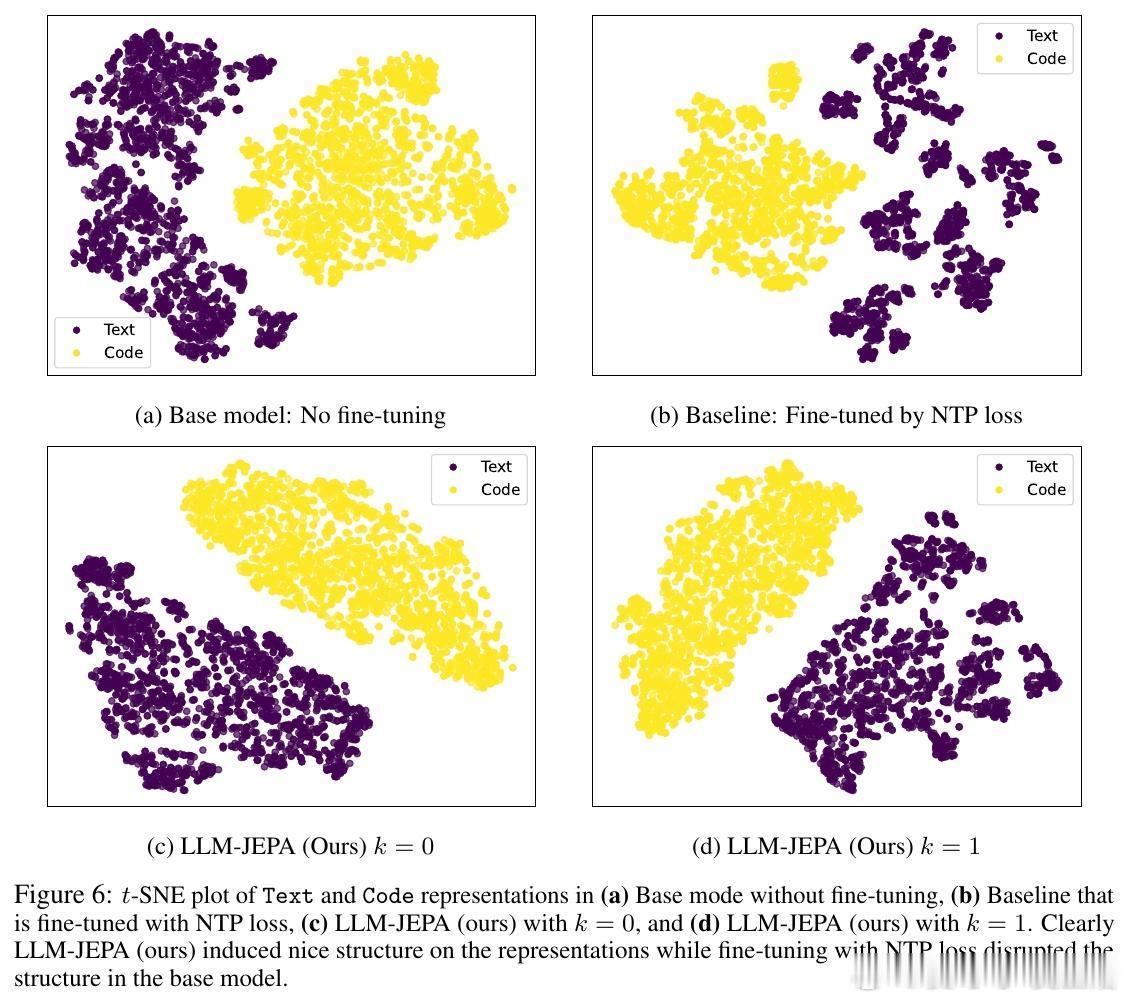
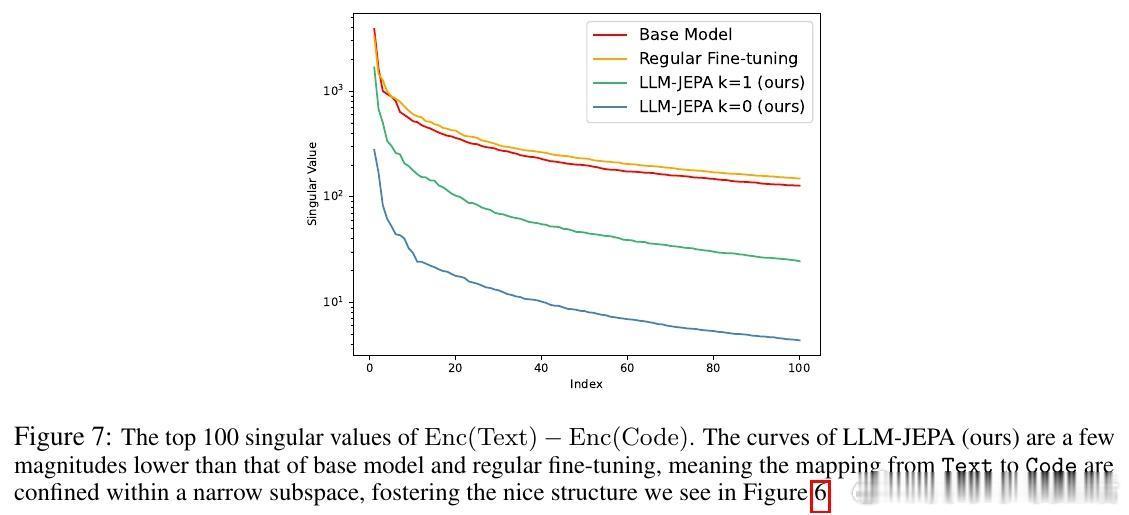
• 表征空间结构化:LLM-JEPA促使文本与代码视角的嵌入间呈现近似线性变换,嵌入空间更加紧凑且结构化,有助于模型理解和推理能力提升。
• 计算成本挑战:训练阶段需要多次前向传播获得不同视角嵌入,带来约三倍计算开销,未来工作计划探索基于自注意力掩码的单次前向传播方案以提升效率。
心得:
1. 重新定义训练目标:语言模型不必仅拘泥于输入空间的生成损失,转向嵌入空间的多视角对比学习可显著丰富语义理解。
2. 多视角数据的价值:自然语言与对应代码、正则表达式等多模态视角为模型提供了更深层次的知识视窗,是提升抽象推理的关键。
3. 结构化表征促进泛化:通过强制模型学习视角间线性映射,LLM-JEPA帮助模型获得更稳定且泛化能力更强的内部表示,突破传统生成模型的瓶颈。
探索语言理解与生成的新范式,LLM-JEPA为未来大模型训练提供了富有前瞻性的思路。
详情🔗 arxiv.org/abs/2509.14252
大型语言模型联合嵌入预测自监督学习模型微调表征学习人工智能