大模型的两种生成文本时常用的采样策略 TOP_P vs TOP_K
制图:Elliot Arledge (h/eng)
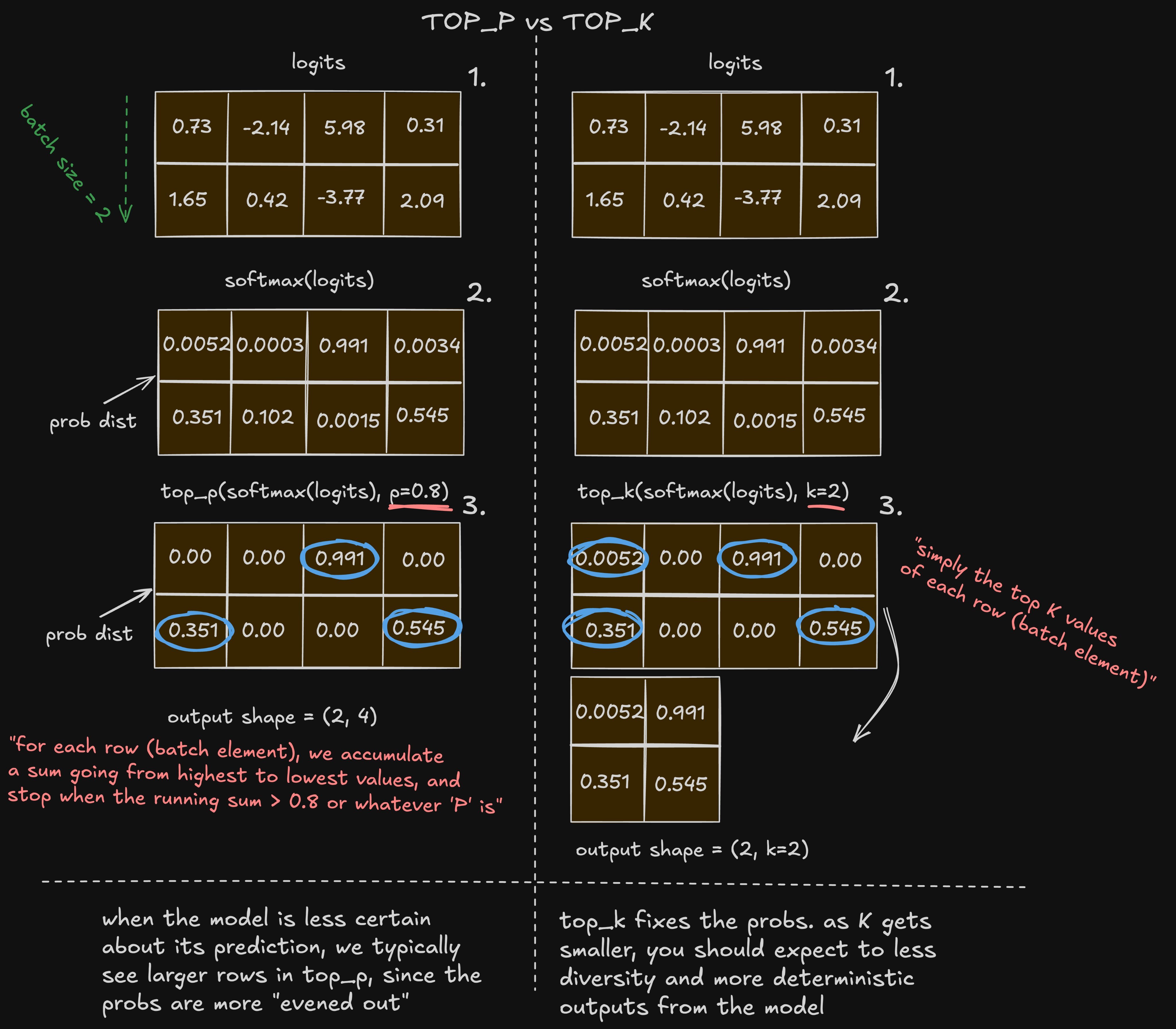
Top-P 这种方法的思想是动态地选择候选词的数量。
规则:设置一个概率阈值 p (图中为 p=0.8)。然后,将所有候选词按概率从高到低排序,并依次累加它们的概率,直到总和刚好超过 p。这个累加过程中包含的所有词,就构成了最终的候选集。
Top-P 是自适应的。当模型对预测结果非常自信时,候选集很小,生成结果更具确定性;当模型不确定时,候选集会变大,允许更多的多样性。
Top-K 这种方法的思想是固定选择候选词的数量。
规则:设置一个固定的整数 k (图中为 k=2)。无论概率分布如何,都只选择概率最高的 k 个词作为候选集。
Top-K 简单直接,但不够灵活。在模型非常自信的情况下,它仍然会强行选出 k 个词,可能会把一些概率极低(几乎是噪声)的词也纳入候选范围。