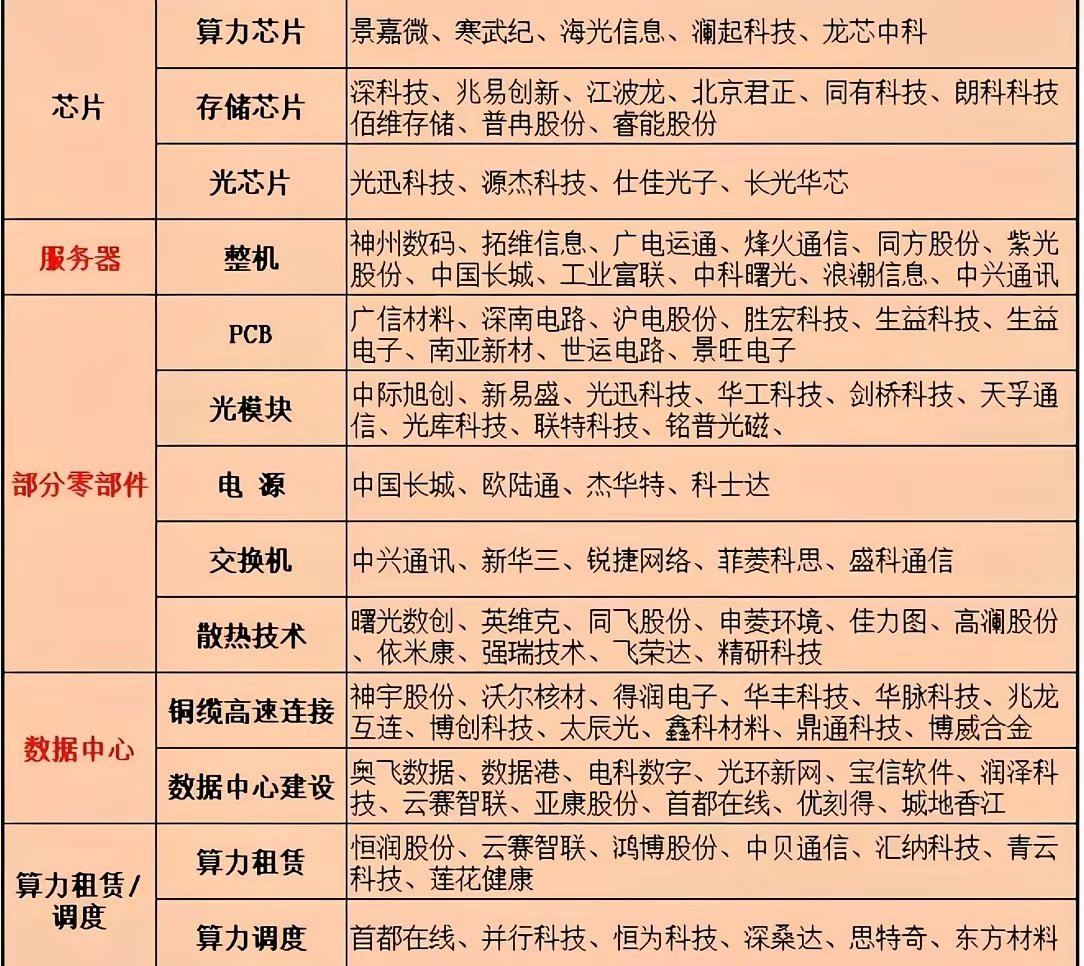
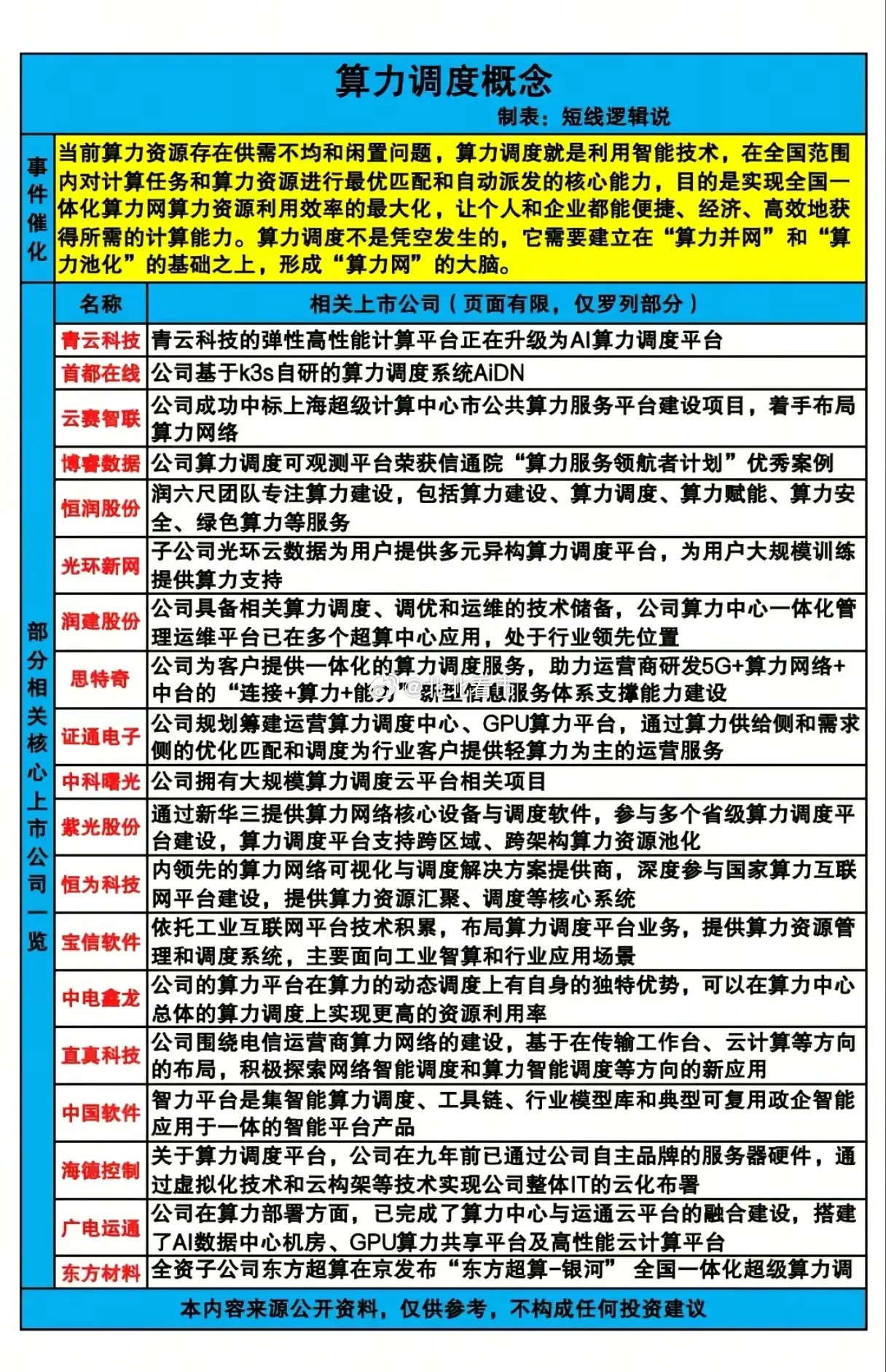
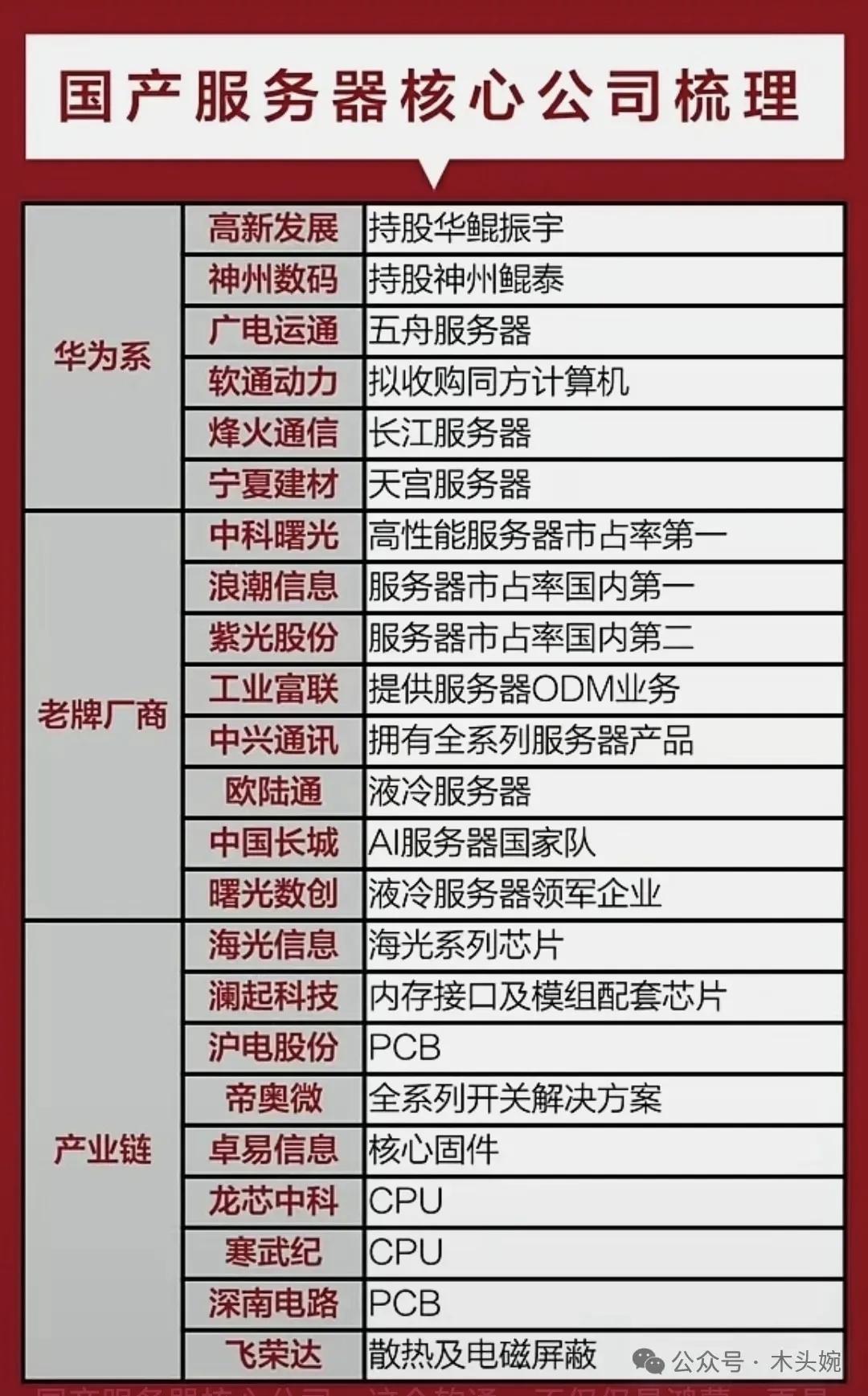
中科曙光刚发布的Scale Fabric高速网络,被业内叫做智算集群的“算力大动脉”——这可是国内首款全栈自研的400G原生RDMA高速网络,直接填上了国产超大规模AI计算系统里的关键空白。
以前高端高速网络基本被国外垄断,比如英伟达的InfiniBand技术占了全球高性能计算500强约6成,不仅贵还卡脖子。 现在Scale Fabric不一样,从最底层的112G SerDes IP、交换芯片、网卡,到交换机驱动和管理软件,全都是自己搞出来的,形成了完整的自主技术体系。
性能更是对标英伟达最新的NDR网络,甚至部分指标还超过——网卡端口带宽400Gbps,端到端时延低到0.9微秒;交换机单端口带宽800Gbps,整机交换容量双向64Tbps,单子网能支持11.4万张卡的集群,总成本还比市面方案低30%。
更厉害的是它已经落地了,在国家超算互联网郑州核心节点支撑着3套万卡级AI算力集群,稳定运行超10个月。部署也快,36小时就完成了三套万卡级集群的网络上线,现在服务着1万个客户,支撑超10项万作业运行。 中科曙光的李斌说得特实在:“计算决定算力上限,网络决定算力下限,网络拉胯,系统性能可能直接归零。”现在有了自己的“大动脉”,万卡、十万卡级的智算时代,终于不用怕网络拖后腿了。
这事儿的意义远不止一款产品——它意味着我们在AI算力的底层“高速公路”上,终于能自己建了。以前训练万亿参数大模型,成千上百张计算卡协同,但网络跟不上的话,卡再快也得空转。
研究显示,大规模分布式AI训练里,网络通信时间占总耗时30%到50%,现在有了Scale Fabric,这些问题都能解决。 更关键的是,它打破了海外垄断,让国产算力基础设施的安全有了保障。
对于想关注投资的人来说,国产算力替代是长期确定的主线。机会主要在三条路:核心突破的中科曙光自己,深度绑定的生态伙伴比如海康信息、安路科技,还有产业链受益者像高速光模块的中际旭创、液冷的曙光数创。 不过得提醒一句,技术落地需要时间,行业竞争也激烈,股价波动肯定大,得盯着产业逻辑理性布局,别盲目追高。 说到底,Scale Fabric的发布是国产算力的标志性突破——我们终于在“算力大动脉”上有了自己的话语权,接下来就看这条“高速公路”怎么支撑更多国产大模型、更多AI应用跑起来了。