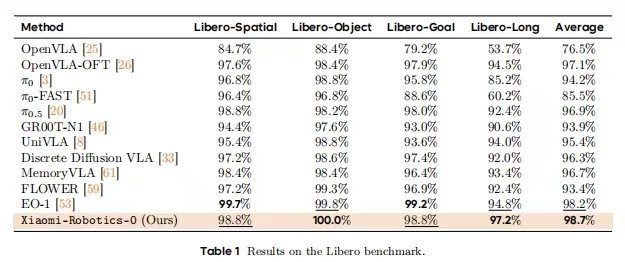
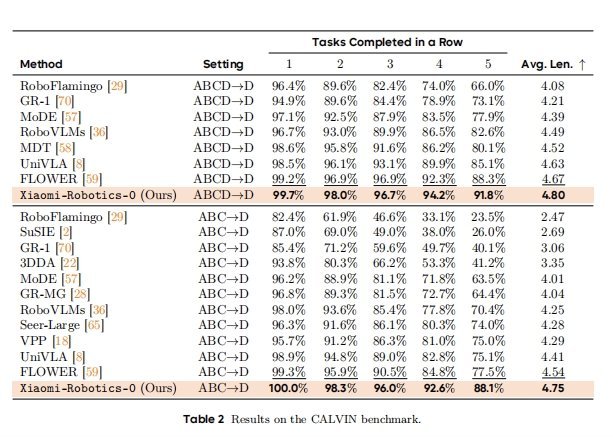
先说关键词,你米这次开源了自家最新的机器人Vla大模型,该模型能力行业第一梯队,小米这次Benchmark全面超越OpenVLA和Pi。
比起某些友商,小米从su7ultra到玄戒到mimo到Robotics-0,小米不语,只是一味技术突破,持续突破
接下来聊聊小米的Robotics-0大模型:
今天小米发布了一篇文章,《小米开源首代机器人 VLA 大模型,刷新多项 SOTA!》,这是小米技术团队关于其具身智能(Embodied AI)领域重大突破的官方技术博客。非常值得关注
文章详细介绍了小米首款开源的机器人VLA(Vision-Language-Action)大模型——Xiaomi-Robotics-0。雷军公布小米机器人最新进展
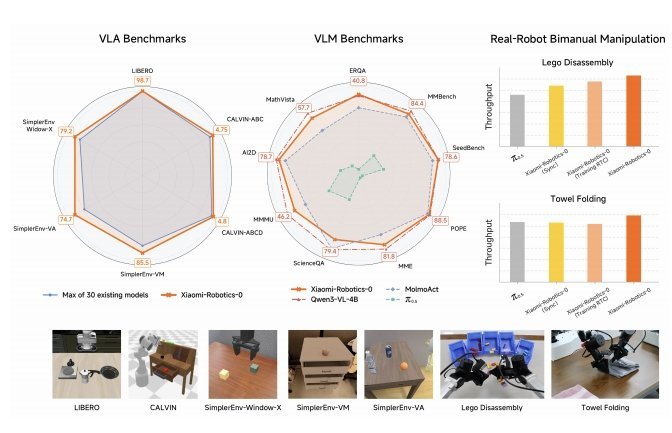
Xiaomi-Robotics-0,是一个拥有47亿参数的开源VLA的模型,它兼具视觉语言理解与高性能实时执行能力,能在消费级显卡上运行,解决了传统大模型在物理世界中“反应迟钝”的问题。
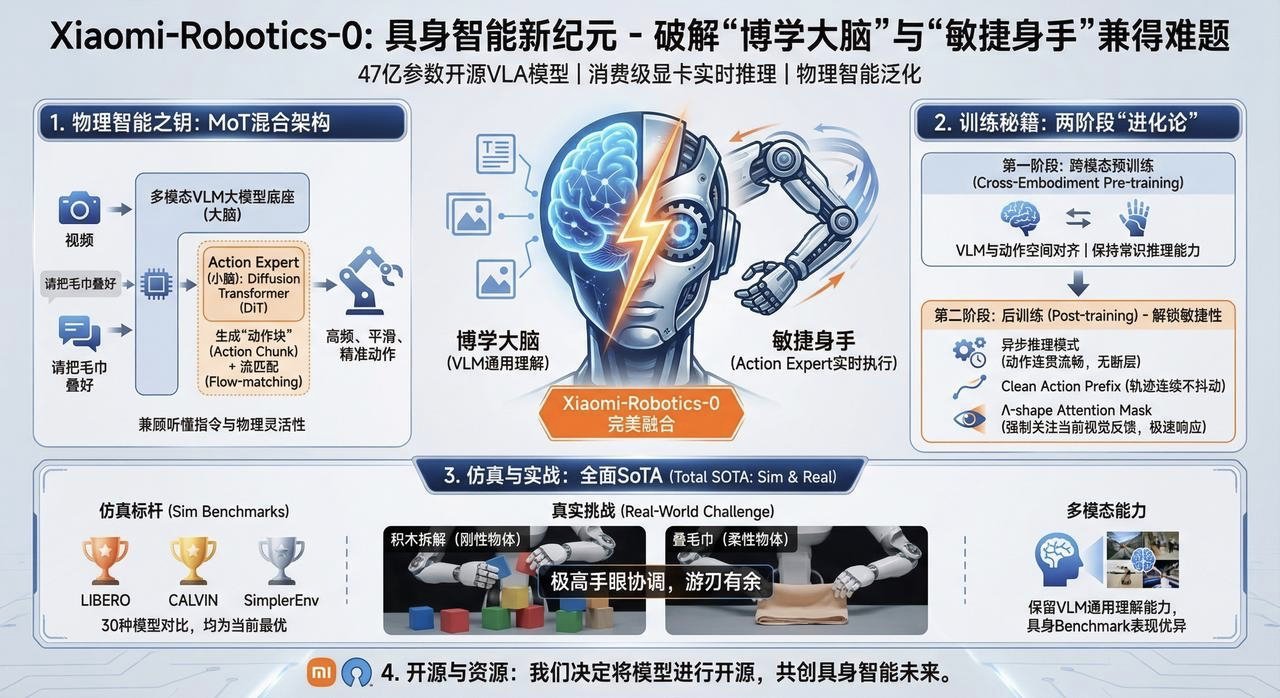
Robotics-0采用了 MoT(Mixture-of-Transformers)混合架构,包含“视觉语言大脑(VLM)”和“动作执行小脑(Action Expert)”。
训练方面,Robotics-0采用了两阶段训练法,包括跨模态预训练(Cross-Embodiment Pre-training)和后训练(Post-training),引入了异步推理和特殊注意力掩码机制。
最后说一下文章本身,这篇文章提出的MoT架构非常有见地。它没有强行将视觉和动作塞进一个模型,而是通过VLM处理语义理解(“做什么”),通过DiT(Diffusion Transformer)处理动作生成(“怎么做”)。这种分工模拟了人类的生理机制,有效平衡了通用认知与精细控制的矛盾。连门外汉也能轻松读懂
它不仅展示了小米在AI领域的深度布局,更标志着具身智能技术从“云端实验室”向“端侧实时应用”的关键跨越。通过开源这一模型,小米不仅提升了其技术品牌形象,也为整个机器人行业提供了宝贵的基础设施,具有重要的里程碑意义。
小米发布机器人基座模型