【Anthropic亲口承认:它会故意给你错误答案】
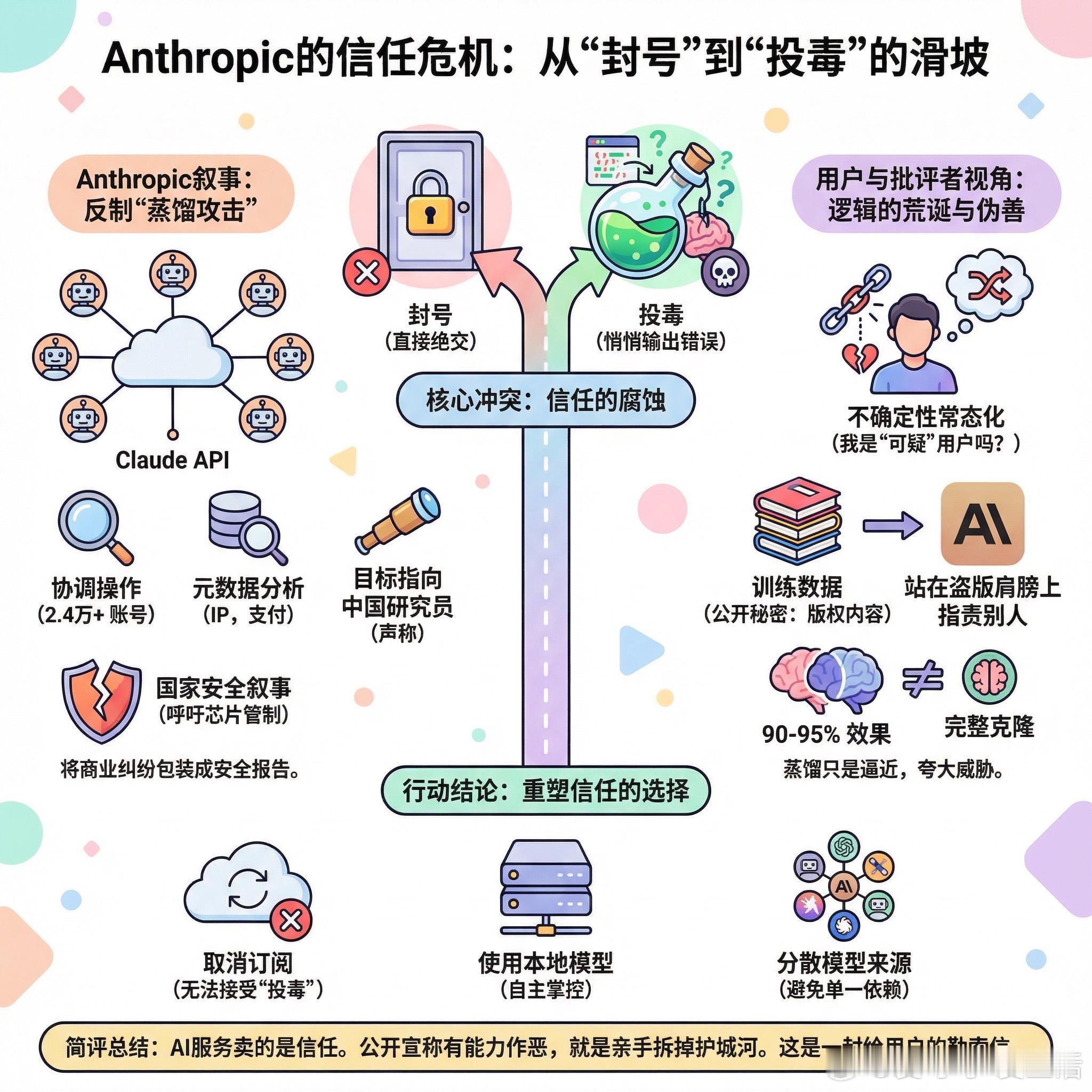
快速阅读: Anthropic发布了一篇关于“蒸馏攻击”的博客,声称检测到DeepSeek等中国实验室通过大量账户系统性地调用其API来生成训练数据。更值得关注的是,他们承认不只是封号,而是主动对“可疑”请求的输出结果进行投毒。这引发了广泛讨论——一家公司有没有权利在你不知情的情况下给你一个故意错误的答案?
---
Anthropic最近发布了一篇博客,主题是他们如何检测并反制所谓的“蒸馏攻击”。内容大意是:他们发现一批账户行为高度同步,支付方式相似,请求节奏整齐,判断是有人在规模化地调用Claude来生成chain-of-thought训练数据,幕后指向中国实验室的研究人员。
这本是一个普通的商业纠纷,却被写成了半个国家安全报告的语气。
但真正让人不安的不是被追踪,而是这一句:他们选择对“问题输出”进行投毒,而不是直接封号。
有网友直接点出了这件事的荒诞逻辑:你不会去雇一个会随机给你错误建议的顾问。如果一个API供应商公开宣布它有能力、也有意愿在后台悄悄劣化你的输出,你怎么知道自己什么时候是正常用户,什么时候已经被划入“可疑”名单?
“可疑”的标准是什么,没人说清楚。有观点认为,这套系统只要存在,任何用户都面临不确定性。问题越多的人,越容易触发某些阈值。
更讽刺的一层:他们用来检测“攻击者”的手段,是分析请求元数据并追踪到具体研究人员。这听起来很高明,其实无非是查账号、IP和支付信息,基本上所有API供应商都能做到,只是大多数人不会公开炫耀。
有网友提到,这些研究人员大概率不会傻到用实名账号。背后涉及多达2.4万个账号的协调操作,追踪链条肯定比官方描述复杂得多。至于“通过元数据锁定到具体研究员”这个说法,听起来更像是施压姿态,而不是侦探工作的复盘。
Anthropic在博客结尾还呼吁加强芯片出口管制,理由是限制算力可以遏制蒸馏攻击。有网友指出这两件事根本不在同一个讨论层面,把商业竞争问题包装成国家安全叙事,目的不言而喻。
目前讨论中最直接的行动结论是:用本地模型,或者至少分散使用多个来源的模型。当你无法验证一个API的输出是否被人为干预过,信任就不再是理性的选择。
有用户在看完这篇博客后取消了Claude订阅。他说,封号他能接受,投毒他不能接受。
这个区别,Anthropic大概认为不重要。
---
简评:
Anthropic这篇博客最精彩的部分,是它亲手拆掉了自己的护城河。AI服务卖的从来不是算力,是信任——而信任这东西,最怕的不是背叛,是“我保留背叛你的权利”。封号是绝交,投毒是诈骗,前者终止关系,后者腐蚀关系的定义本身。当一家公司公开宣称它的检测系统可以悄悄给你塞错误答案,每个用户都必须面对一个无法证伪的质问:我这次的输出,是真货还是样品?最讽刺的是,他们用来证明自己“正义”的手段,恰恰证明了自己“有能力作恶”。这不是安全报告,这是一封写给所有付费用户的勒索信:好好表现,别问太多问题。
---
reddit.com/r/LocalLLaMA/comments/1rd8cfw/anthropics_recent_distillation_blog_should_make