chatgpt如何对AI进行“微调”?
罗永浩AI团队又开始招人了,里面有个算法工程师岗位,要对大模型进行微调。我来解释一下什么叫微调:
什么是“微调”?
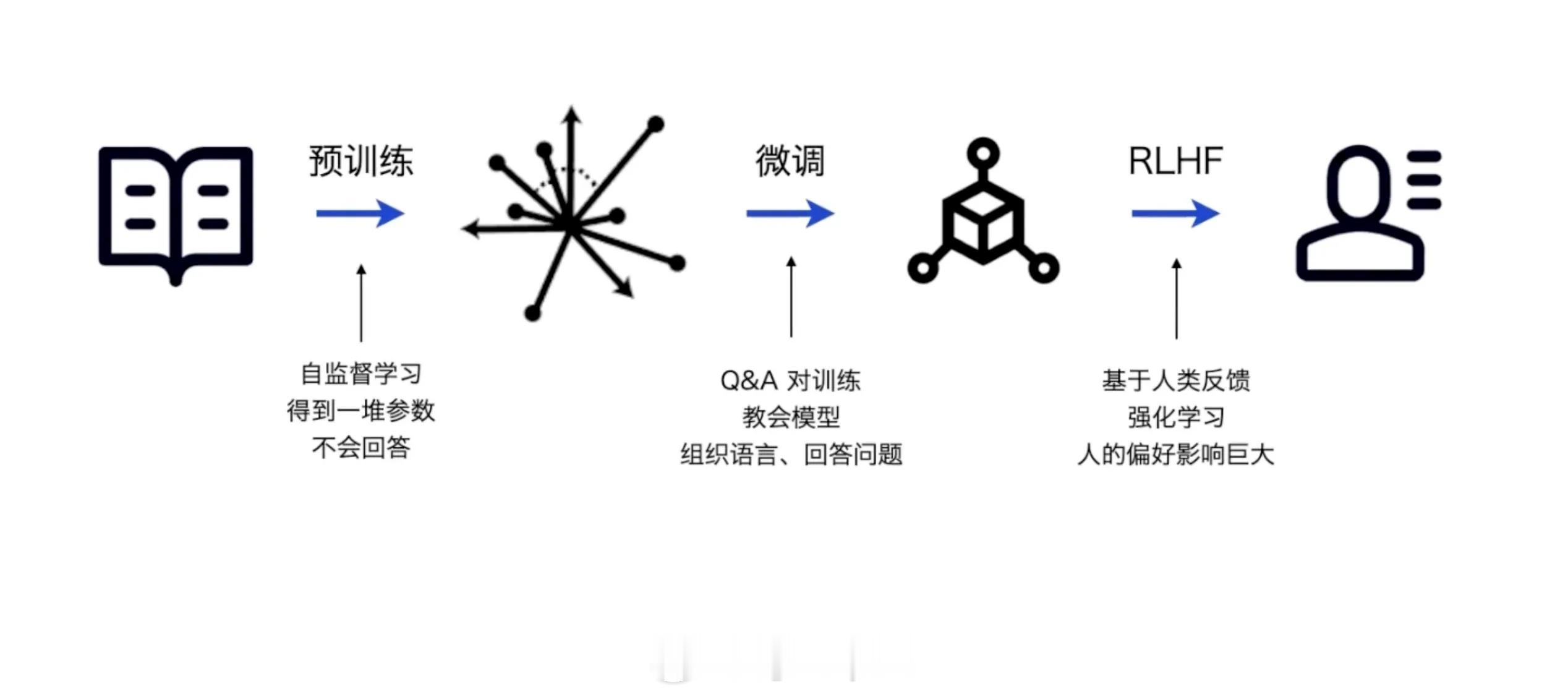
首先,我们先大致了解一下,什么是微调?常规大模型语言模型的训练路径分为以下几个阶段:简单的说,以我们养娃来打个比方:
1. 预训练(通识教育)
模型:通过自监督学习(如阅读海量文本),掌握基础语言规则,但还不会针对具体问题回答。
比喻:就像孩子上学前大量听大人说话、读绘本,积累了词汇和常识,但还不会完整表达观点。
2. 微调(专项训练)
模型:用Q&A对训练,教会它如何组织语言、精准回答问题。
比喻:类似家长或老师通过“问答练习”教孩子:
问:“天空为什么是蓝色的?”
教:“因为阳光散射…”。
→ 孩子会使用专业的术语,清晰高效的表达。
3. RLHF(品德教育)
模型:根据人类反馈调整回答,符合社会偏好(如更友善、更严谨)。
比喻:当孩子说“因为天空喜欢蓝色!”,家长纠正:
“答案要有科学依据哦!”
→ 孩子学会“不仅回答,还要回答得靠谱”。
那么,聪明的你,一定会明白了,大模型什么时候需要微调呢?一般会在输出要求严格的垂直场景,或者希望更效率的任务,快速输出结果。在企业的 Ai 落地过程中,非常需要这一项任务。


![这ai太逼真吗?[赞][赞]ai](http://image.uczzd.cn/422974456033376523.jpg?id=0)