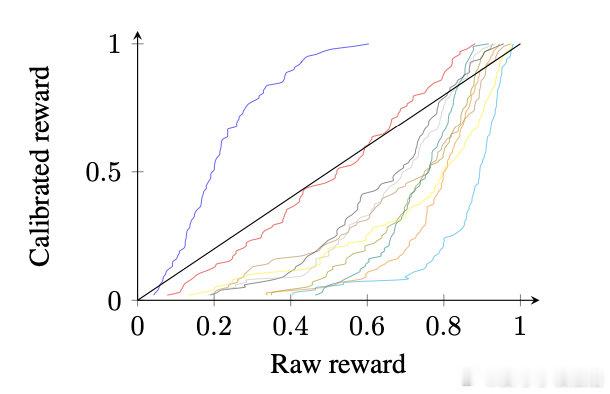
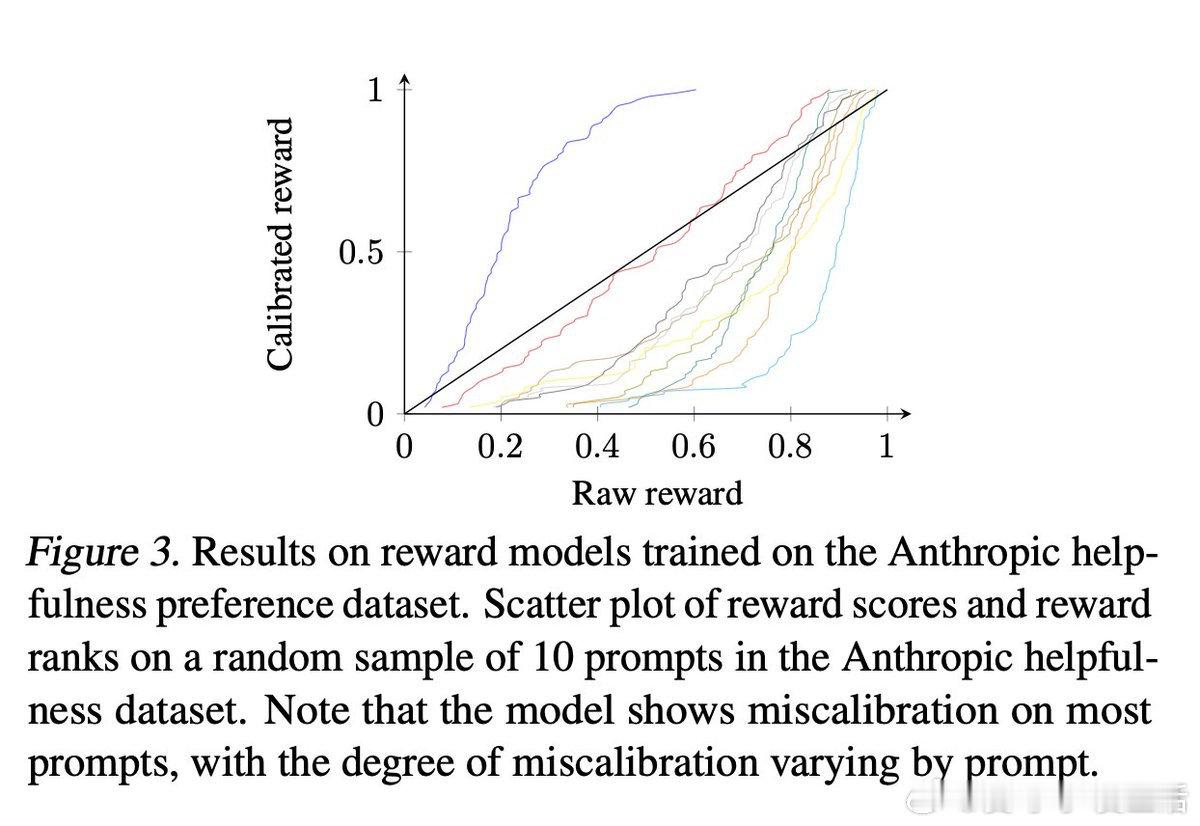
GRPO性能跃升的关键在于通过每个prompt进行多次rollout实现奖励/价值的校准,使得奖励值在不同任务和模型表现间具备可比性。
• 未校准的0/1二值奖励难以判断模型解决的是简单问题还是难题,导致策略更新模糊。
• 对于更细腻的BT奖励(连续标量0~1),同一分数在不同prompt下含义差异巨大,缺乏统一参考。
• GRPO多rollout将奖励分布校准成近似高斯分布,使奖励值在各prompt间具备一致语义,避免训练中随机提升或降低样本价值。
• 相关工作提出基于参考模型响应分布,将奖励校准为经验分布的逆CDF,简化为训练前离线多次采样,训练时仅需简单逆CDF变换。
• 该方法对现有RL算法仅需两行代码改动,rollouts离线完成,适用所有训练epoch和超参搜索,显著提升标准RL性能,创下多项SOTA纪录。
• 同时支持根据推理时的采样算法对奖励作进一步变换,增强测试时性能表现。
• 详见ICML 2025发表论文:arxiv.org/abs/2412.19792
• 相关理论分析和成功放大机制可参考Youssef Mroueh关于GRPO的深入研究:arxiv.org/abs/2503.06639
这一策略有效解决了奖励非均质性带来的训练偏差,是提升LLM推理质量和安全性的重要突破。
详细讨论🔗 x.com/abeirami/status/1954164566876684587
强化学习 奖励校准 语言模型 GRPO 机器学习 ICML2025