强化学习算法GRPO与GSPO对比解析,揭示相对奖励与序列优化的核心差异:
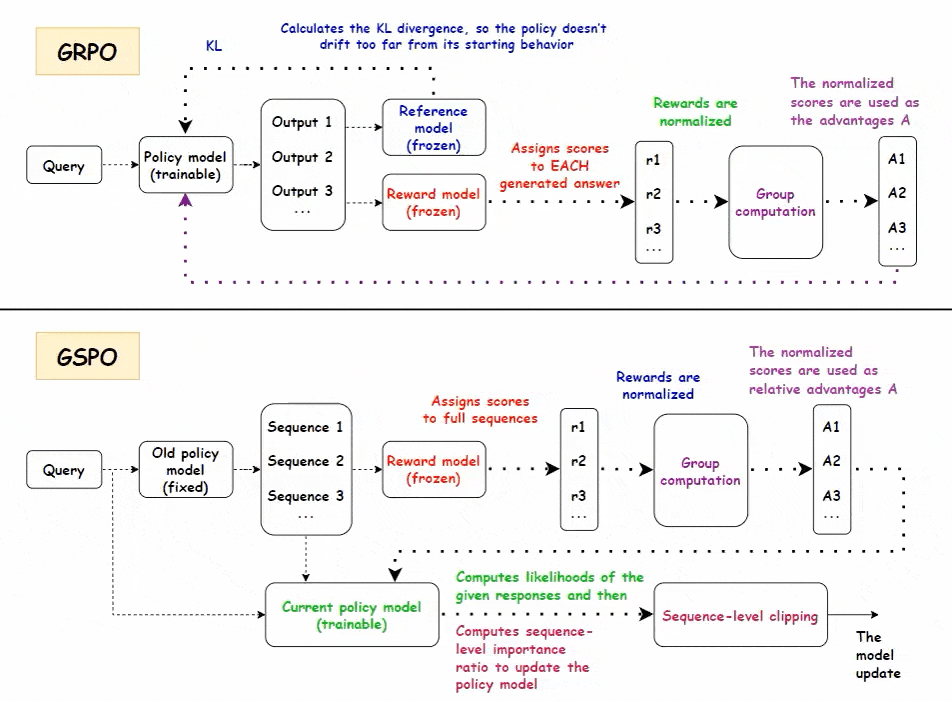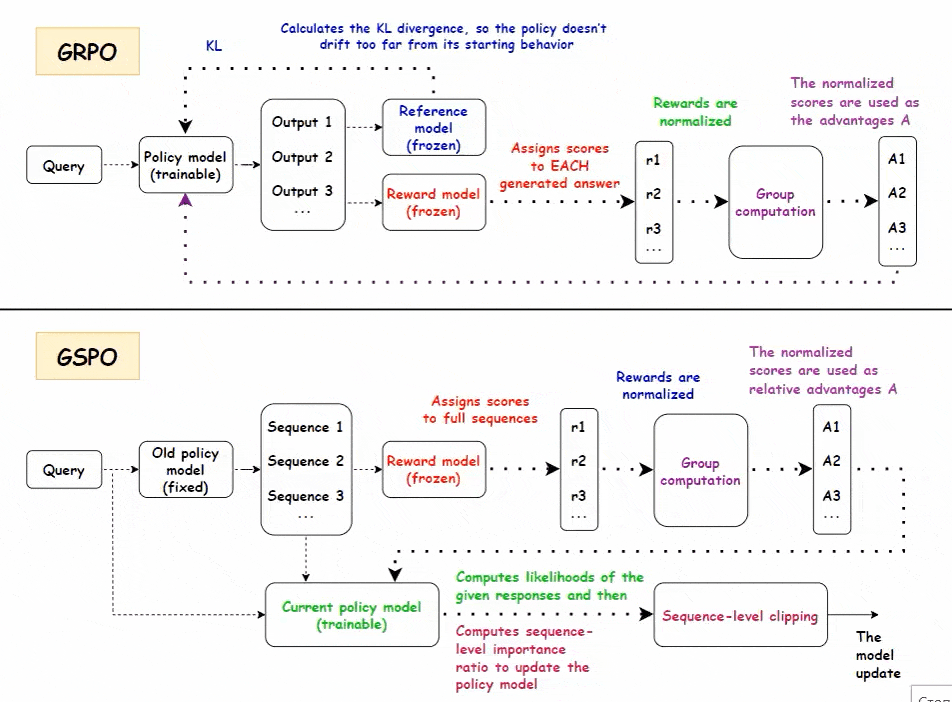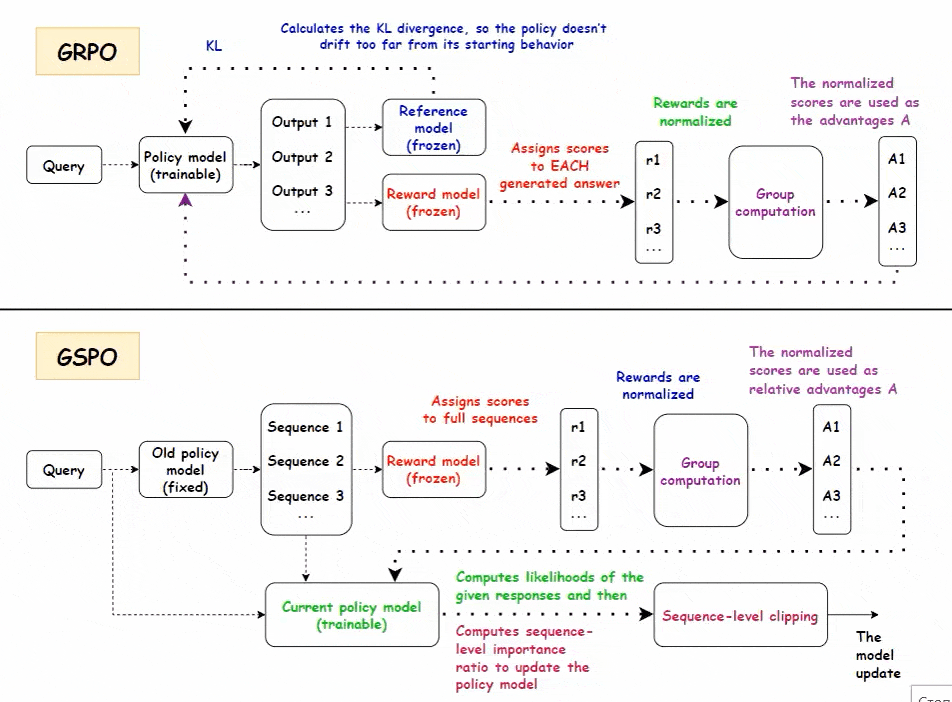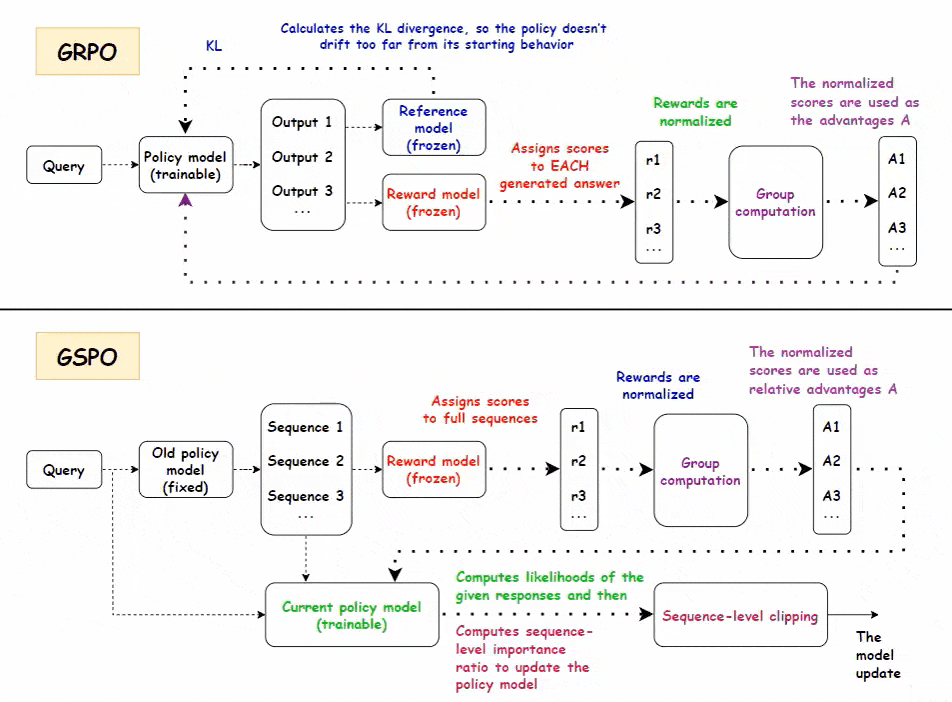
• GRPO(Group Relative Policy Optimization)聚焦“比较学习”,适合多步骤推理任务
- 策略模型生成一组答案,奖励模型对每个答案评分,基于组内均值和标准差归一化,形成相对优势信号
- 无需价值模型,节省计算资源
- 通过链式思考中的关键步骤奖励传播,强化早期有贡献的token,提升推理效率
- 迭代训练中使用10%旧数据稳定模型,防止遗忘
• GSPO(Group Sequence Policy Optimization)以序列级优化提升稳定性,适合长序列与大规模模型
- 以整条序列为单位评分和归一化,计算当前与旧策略的序列重要性比率
- 采用序列级裁剪降低梯度噪声,提升训练稳定性
- 无价值模型设计,降低内存和计算负担,适应MoE专家路由动态变化
- 支持GSPO-token变体,实现多轮对话或细粒度推理的token级优势应用
两者本质区别在于相对奖励的粒度与稳定性权衡:
GRPO强调组内相对质量,适合复杂推理路径挖掘;GSPO通过序列整体把控,解决长序列训练不稳定难题。
选择依据:多步推理与长序列生成的平衡取舍,决定了策略优化的最佳路径。
详细讨论🔗x.com/TheTuringPost/status/1953976551424634930
强化学习深度学习人工智能机器学习序列优化