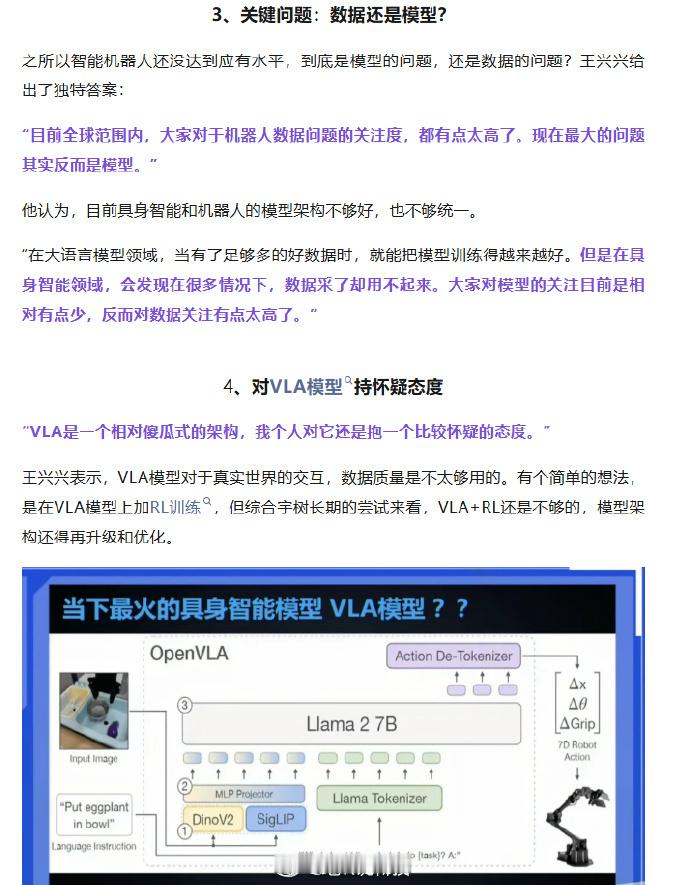
【VLA模型遭质疑:智驾的“终极答案”还是“傻瓜架构”?】
在车企集体押注VLA(视觉-语言-动作)模型的热潮中,宇树科技CEO王兴兴却泼了一盆冷水:他公开称VLA为“相对傻瓜式的架构”,直言对其应用前景“持怀疑态度”。
核心争议点:
VLA的“致命伤”:数据饥渴症
1.王兴兴指出,VLA依赖海量真实交互数据,但现实场景数据分布极不均衡(如人类驾驶中高速路占60%,乡间小路不足1%),导致模型训练偏科,长尾场景处理能力弱
2.宇树尝试用“VLA+强化学习(RL)”补救,仍杯水车薪。更棘手的是,机器人领域缺乏“RL缩放定律”,学新任务需“从零开始”,效率低下
替代方案:世界模型能否破局?
1.王兴兴力推“视频生成驱动”的世界模型:通过生成动作视频指导机器人执行任务(如“整理房间”指令→生成操作视频→机器人复现)。他认为该路线收敛更快,且对视频精度要求不高,GPU消耗可优化
2.车企早已暗中布局:理想用世界模型补足训练数据,蔚来强化其空间理解能力,但当前效果尚未惊艳
成本与能力的双重拷问
-国际机器人联合会主席Alexander Verl揭露VLA七大缺陷:无记忆、感知缺陷、动作缺失、物体混淆、低成功率等,且单模型训练成本超数千万美元
-相比之下,世界模型通过合成数据降本,但视频生成算力消耗仍是瓶颈
挺VLA派:理想、小鹏、华为等将VLA作为智驾核心
世界模型派:蔚来、宇树等探索视频生成路径,试图绕过数据荒
中立务实派:短期2-5年,端到端模型仍是主流;
所以你认同王兴兴的说法吗?你更看好VLA的“暴力美学”,还是世界模型的“生成式破局”?
智驾暗战智能驾驶VLA