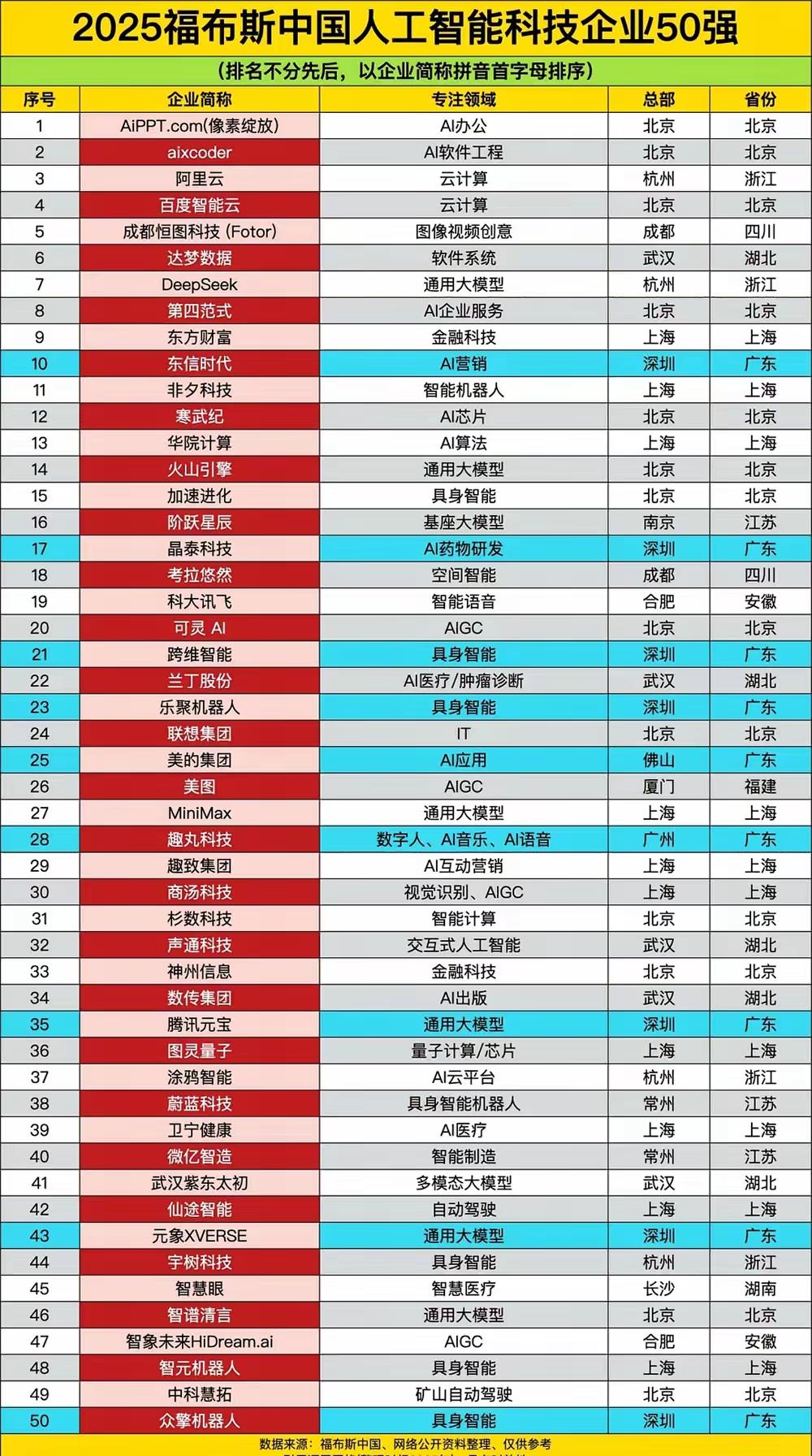
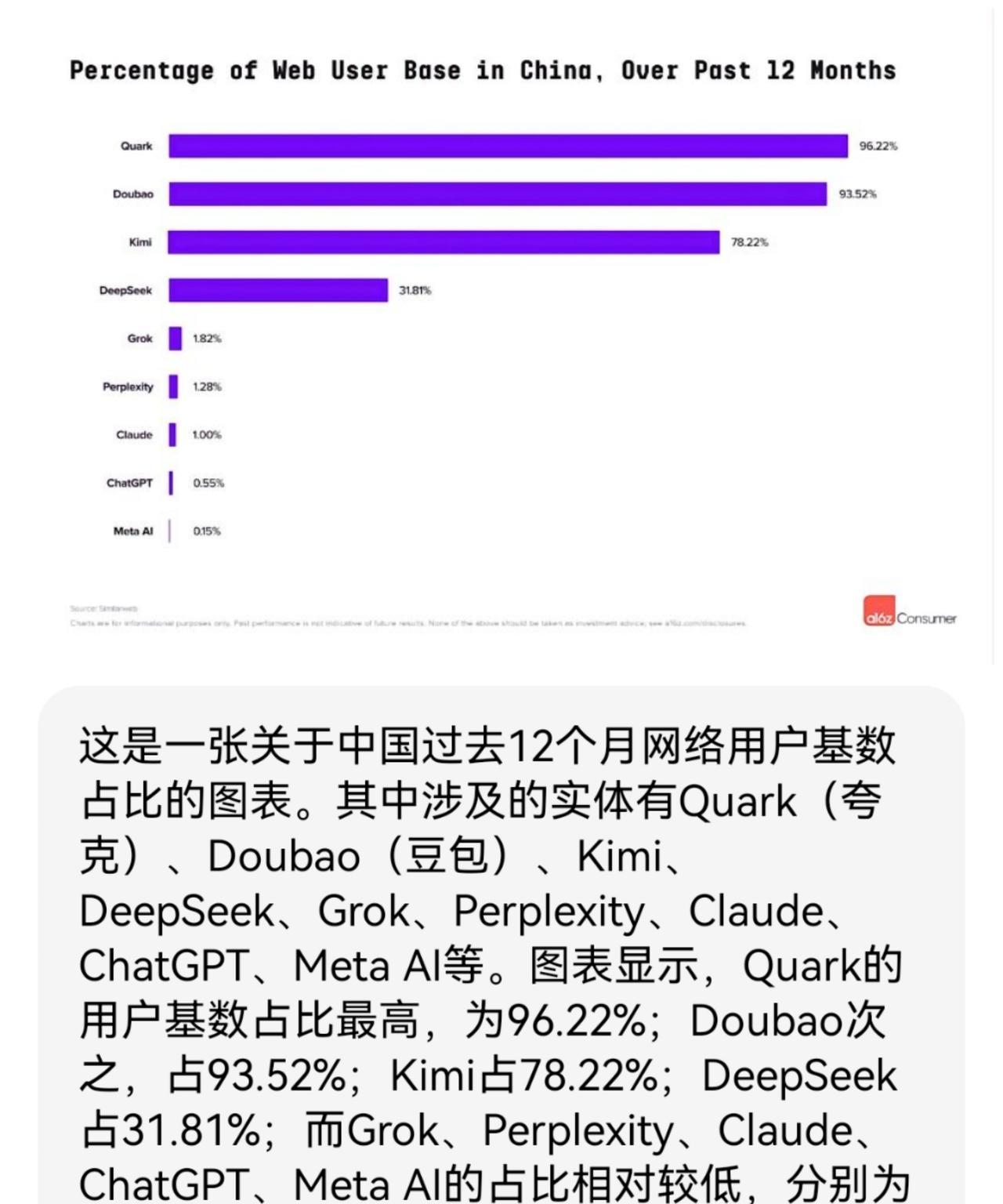
[熊猫]记者问:“中美 AI 差距到底有多大?” 梁文峰毫不避讳一针见血地回答:“表面上中国 AI 与美国可能仅有一两年的技术代差,但真实的差距是原创和模仿之差。如果这个不改变,中国永远只能是追随者,所以有些探索也是逃不掉的。” 这话直接点破了中国 AI 的核心痛点。 很多人觉得中美人工智能的差距就是算法、模型或者算力上的距离。 确实,美国在人工智能领域一直是大手笔,从十几年前的AlexNet到后来的Transformer,再到ChatGPT,每次技术浪潮几乎都是美国掀起来的。 这些突破不只是技术牛,还重新定义了人工智能的玩法。 相比之下,中国人工智能过去更多是在这些技术基础上做优化,搞应用,简单说就是模仿多,原创少。 这种模式让中国在早期追得很快,但到核心突破的时候,就有点后劲不足了。 DeepSeek的出现有点打破这个局面,他们的R1模型用了一种特别的训练方式,直接上强化学习,跳过了传统的监督微调,性能居然能跟OpenAI的o1掰手腕,成本却只有人家的十分之一。 这说明什么?创新不一定非得堆钱堆算力,巧妙的算法设计也能杀出一条血路。 DeepSeek的V3模型甚至用性能不算顶尖的芯片,硬是训出了能跟GPT-4o抗衡的效果。 这不只是技术突破,还证明了中国人工智能在原创上开始迈步子了。 不过,冷静想想,DeepSeek的影响在全球人工智能圈子里还只占一小块,原创能力跟美国比,还是有不小距离。 美国人工智能为什么强?不光是技术,还有一套开源的玩法,像Linux、Wikipedia这种项目,早就让美国习惯了全球协作的模式。 开源不仅让技术传播更快,还能靠全世界开发者的脑力加速迭代。 DeepSeek也学了这招,把R1和V3模型开源,全球开发者都能免费用,甚至拿去商用,这跟OpenAI的闭源路线完全不一样。 结果呢?DeepSeek的模型在国际社区火了,印尼、俄罗斯的企业都开始用它的技术搞本地化应用,这不仅让中国人工智能在国际上露了脸,也让全球人工智能生态更丰富了点。 但说实话,中国的开源文化还差口气,DeepSeek这种做法在国内算另类,大部分企业还是更喜欢闷头赚钱,而不是分享技术,文化上的差异让中国在建全球化的生态时有点吃力。 DeepSeek开了个好头,但能不能带动更多企业拥抱开源,还得打个问号。 美国的产学研结合很成熟,谷歌、Meta跟斯坦福、MIT这些学校合作紧密,人才和研究源源不断。 中国虽然论文数量已经超过美国,但论文的质量和转化成实实在在技术的效率,还得再加把劲。 美国的市场开放,监管宽松,吸引了全球的人才和资金,2024年,美国人工智能的私人投资高达上千亿美元,中国才不到一百亿。 这差距让美国企业有更多试错空间,能搞高风险高回报的项目。 中国这边,政府支持力度不小,国家数据局、人工智能基础设施这些都在推,但美国对中国的芯片制裁是个硬伤。 从2022年开始,高端芯片像H100被卡脖子,DeepSeek只能用性能差一点的H800。 但有意思的是,制裁反而逼出了中国人工智能的创造力,DeepSeek硬是用算法优化和模型压缩,靠2048颗H800芯片,花不到600万美元,训出了性能不输GPT-4o的V3模型。 这招“以软补硬”不仅绕过了硬件限制,还挑战了美国“算力为王”的逻辑。 不过,长期看,芯片瓶颈不突破,模型训练和推理的效率还是会受限,而且美国最近还指责DeepSeek通过接口违规拿数据,这种地缘政治的干扰,给中国人工智能的国际化添了不少麻烦。 DeepSeek的意义在哪?它不只是技术牛,更像是中国人工智能从模仿到原创的一个信号。 低成本的策略让中小企业也能玩得起人工智能,开源的模式还给发展中国家带来了技术平权的机会。 DeepSeek点燃了一盏灯,但要照亮中国人工智能的未来,还得更多企业、更多创新一起发力。 信息来源:台海时刻