[LG]《How Reinforcement Learning After Next-Token Prediction Facilitates Learning》N Tsilivis, E Malach, K Ullrich, J Kempe [New York University & Harvard University & Meta] (2025)
强化学习如何助力大语言模型超越逐词预测,实现高效学习
🔍 研究背景
当前神经网络推理能力的提升,多归功于先用“逐词预测”预训练大型语言模型(LLMs),再用强化学习(RL)微调,极大提升模型在复杂任务中的表现。本文系统理论分析了这一训练范式为何高效,并揭示了RL如何突破仅靠逐词预测的局限。
⚙️ 研究方法
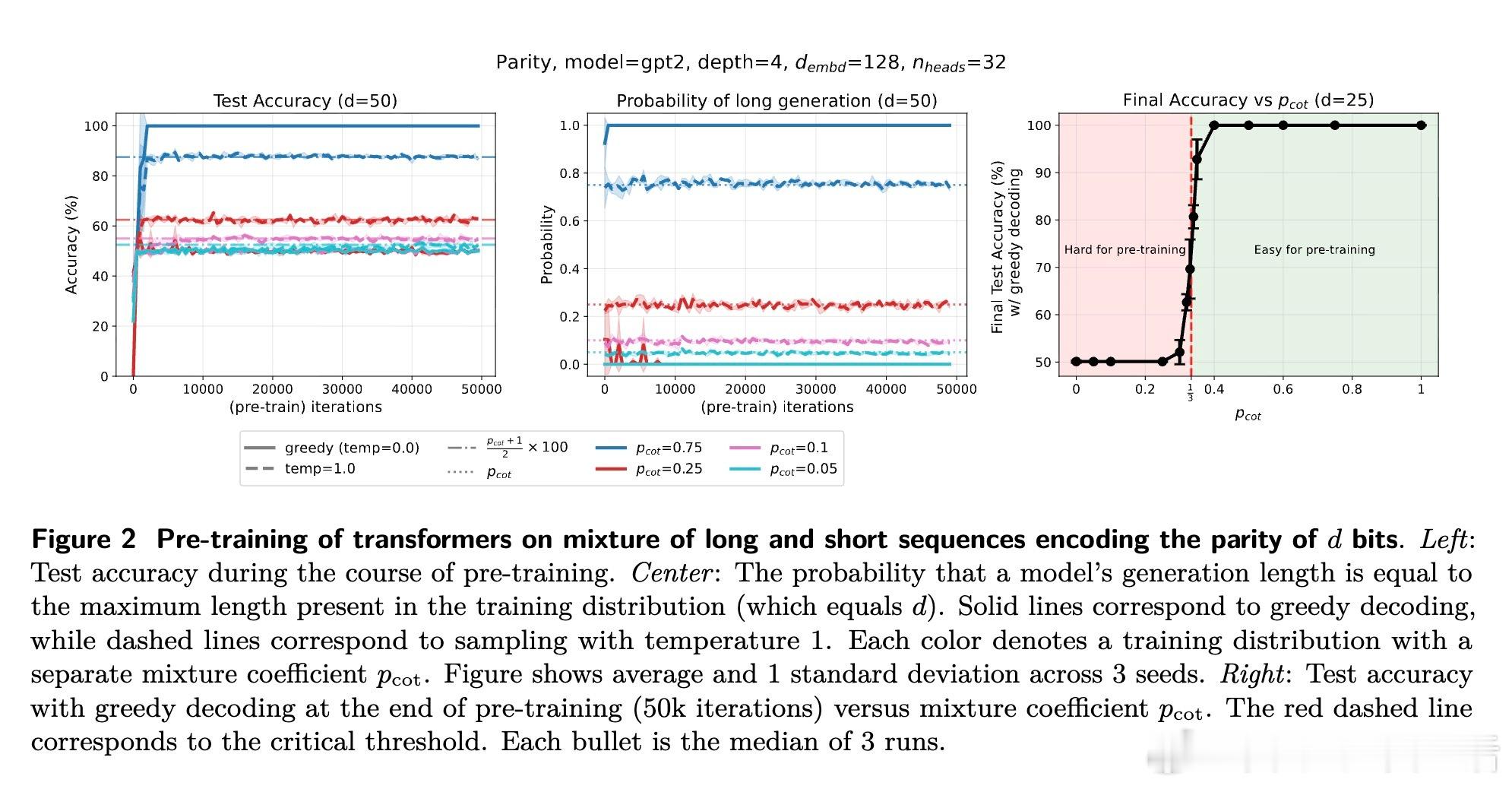
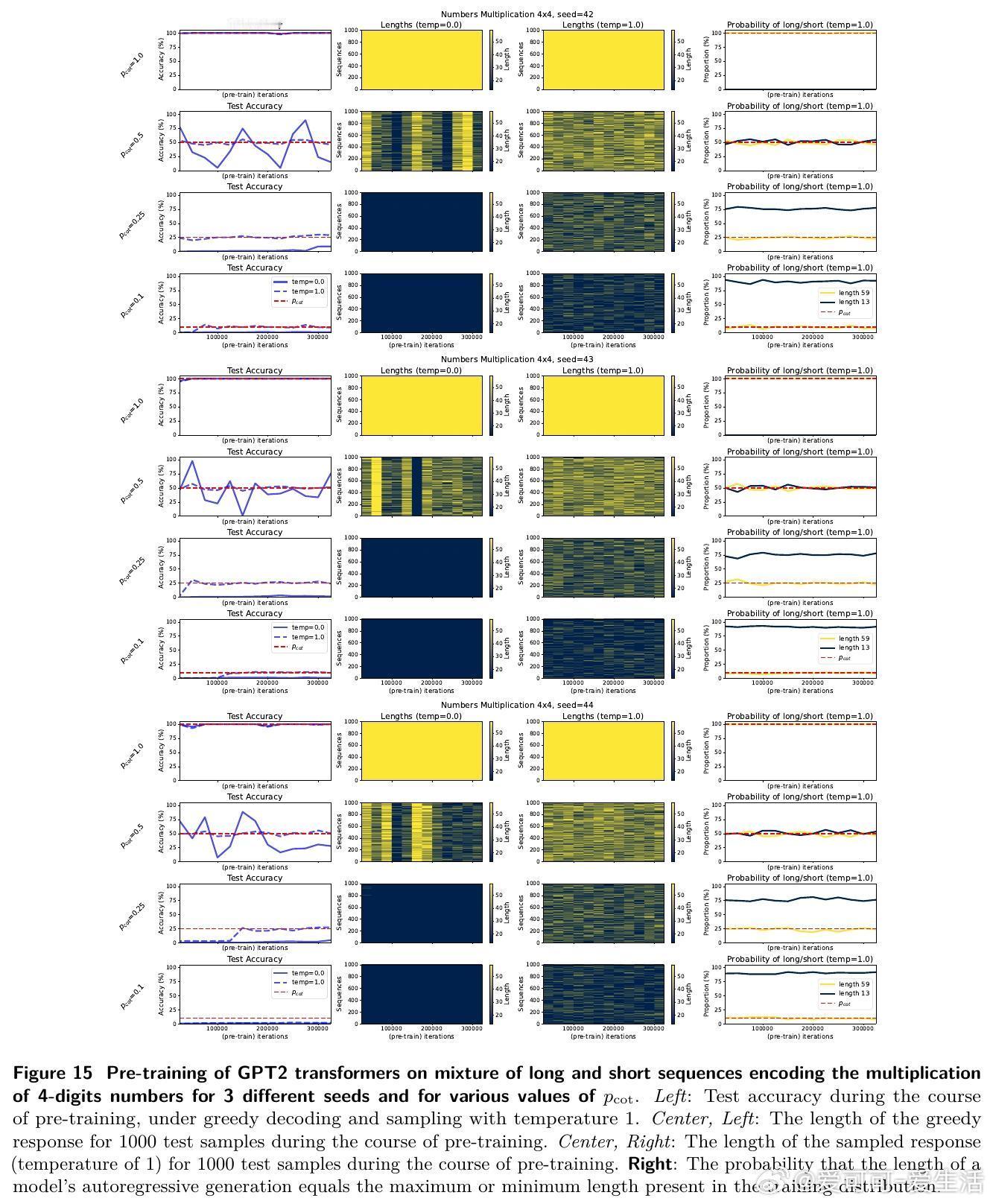
- 以“奇偶校验”任务为核心,设计混合分布数据:短序列(直接输出结果)与长序列(包含“思维链”推理过程)。
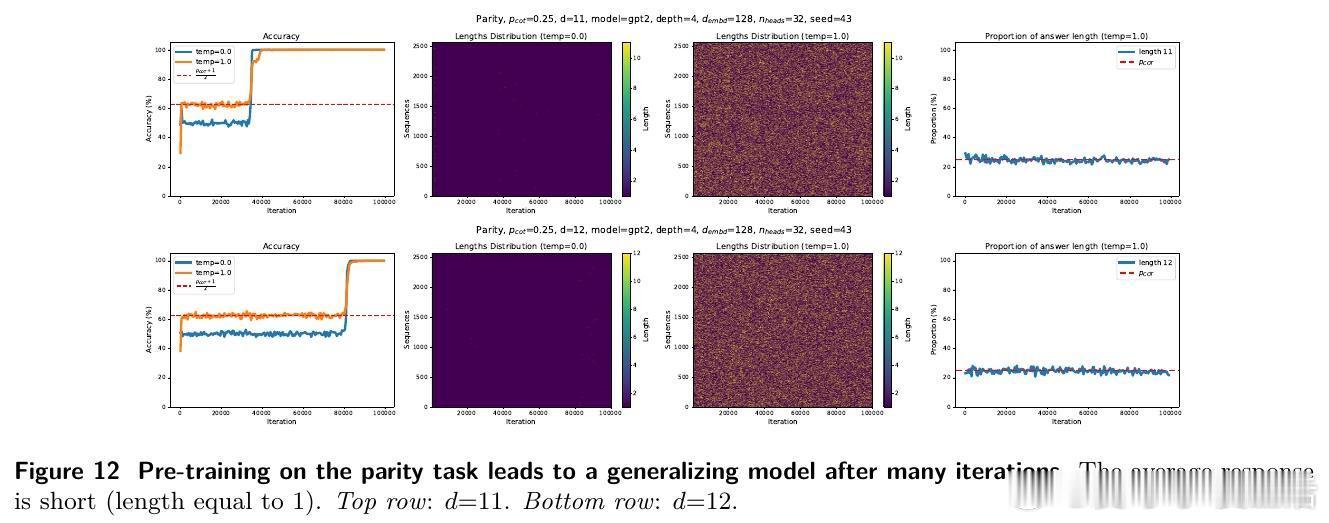
- 预训练阶段:仅用逐词预测训练模型。
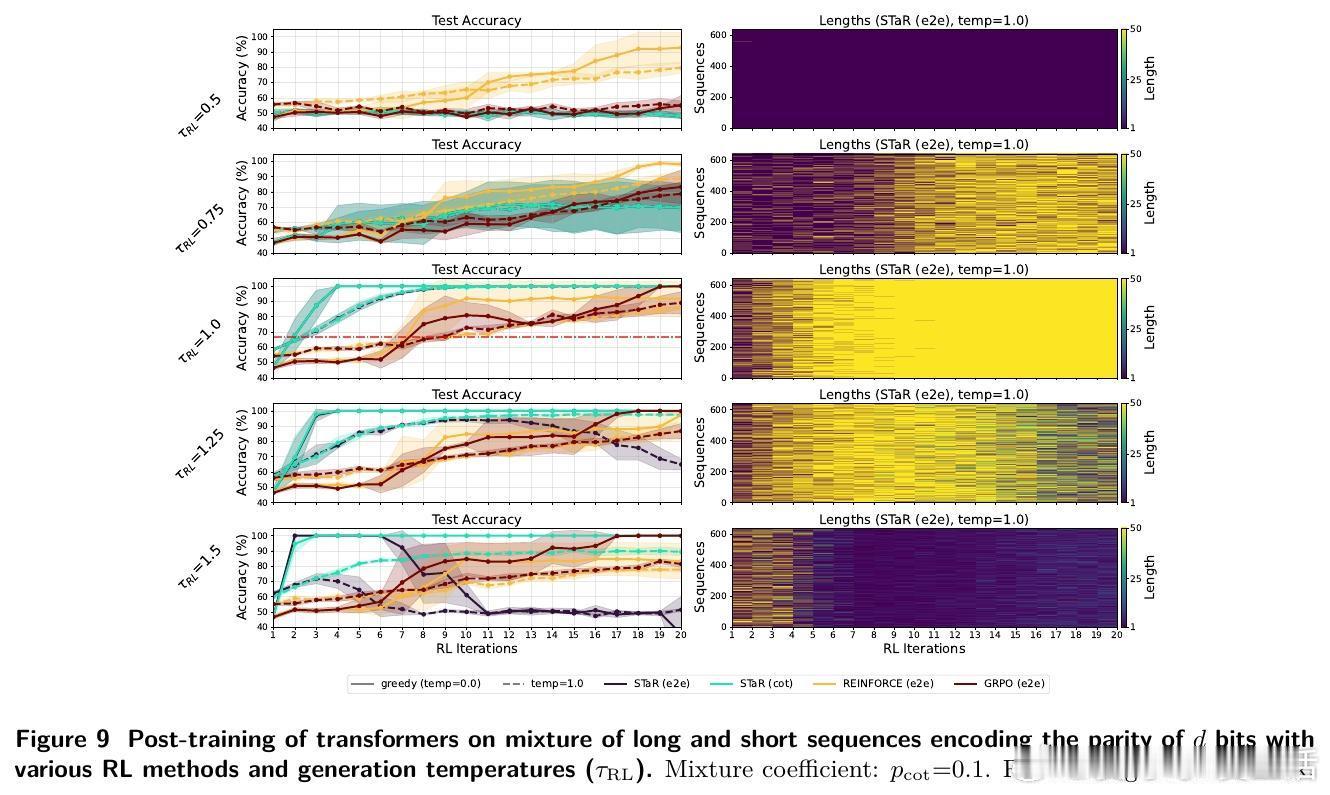
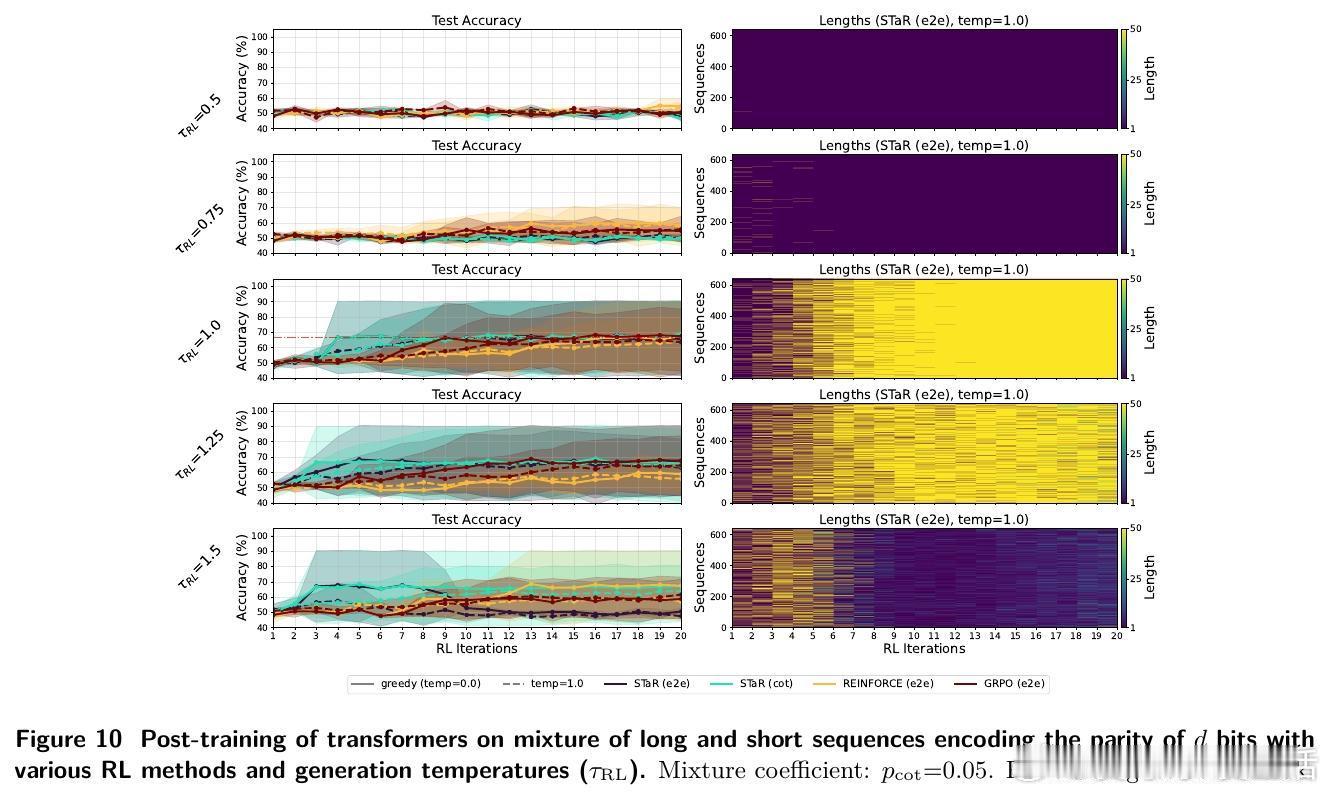
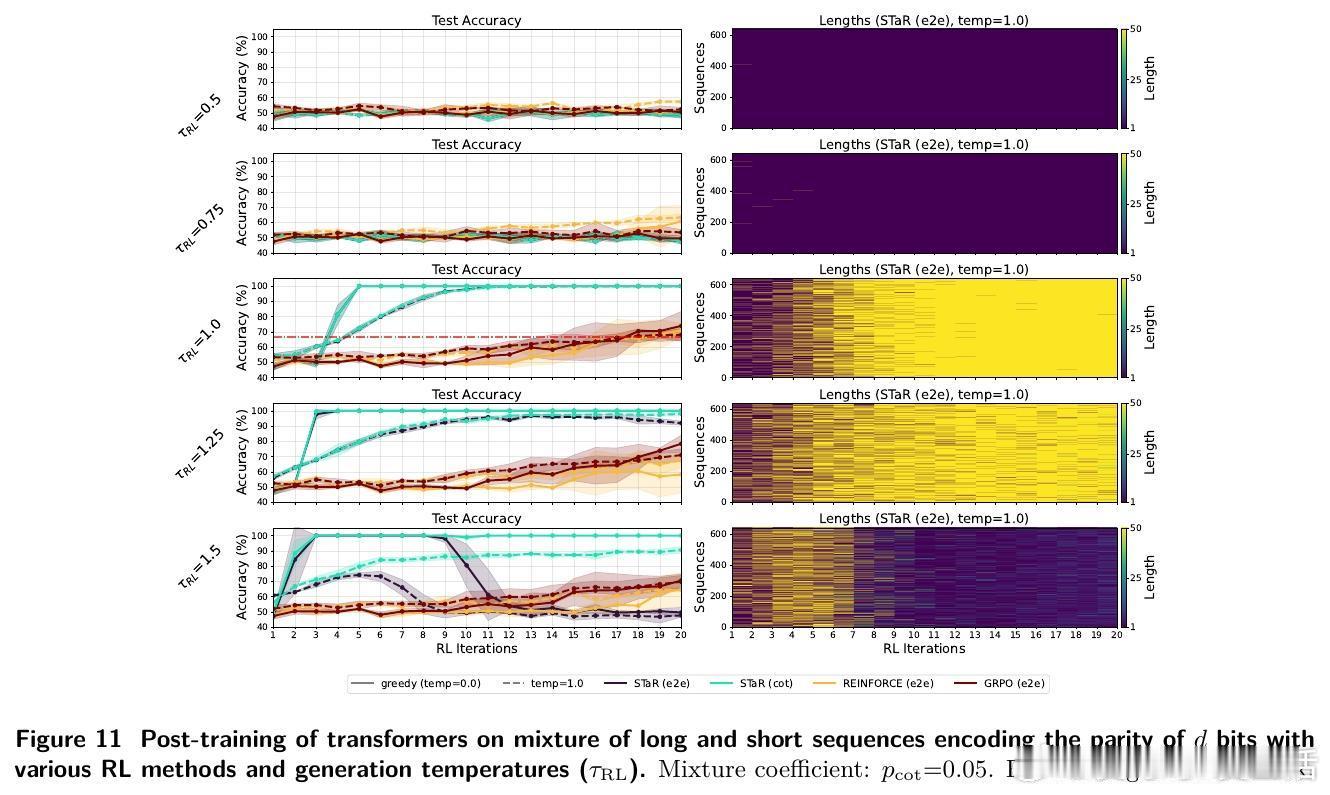
- 后训练阶段:用RL(STaR、REINFORCE、GRPO等算法)结合正确性奖励,强化模型生成长推理链。
- 理论层面:用线性自回归模型证明,当长推理示例不极端稀少时,RL后训练能快速实现泛化。
📈 主要发现
1️⃣ 预训练难以泛化:当长推理示例低于约1/3比例,模型预训练后生成短答,准确率接近随机。
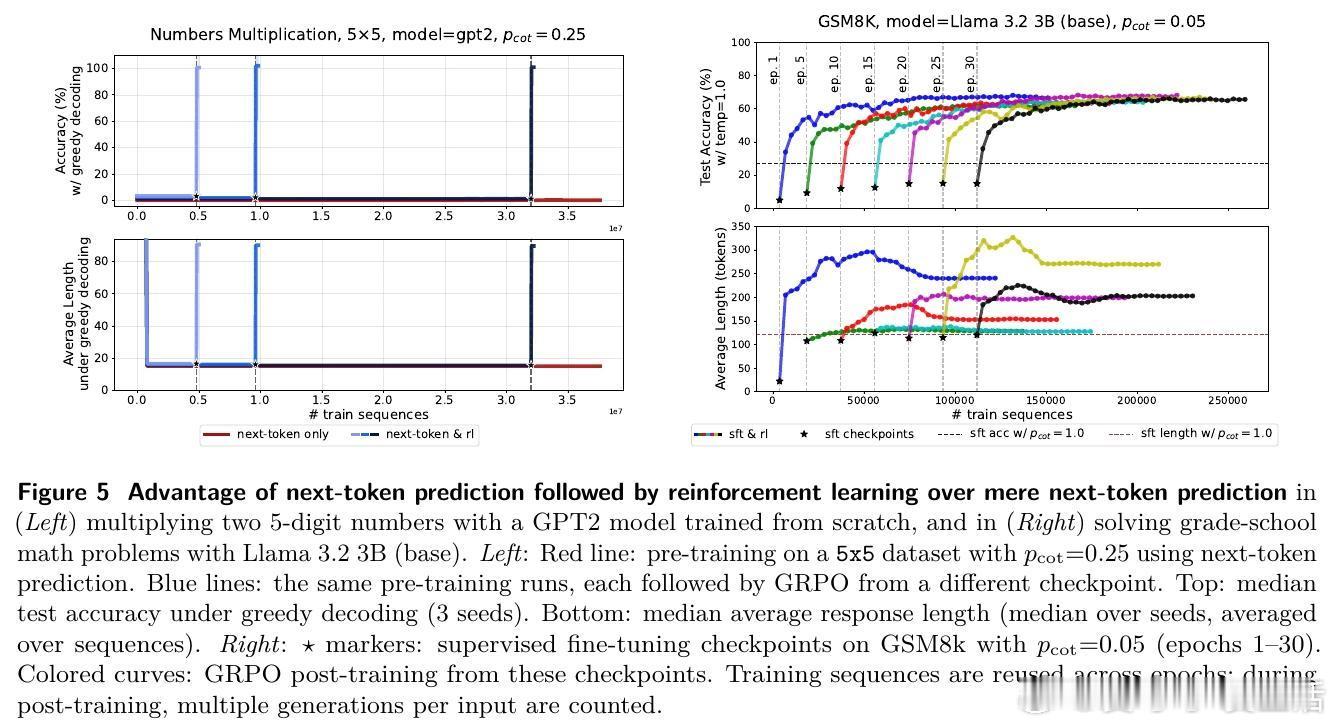
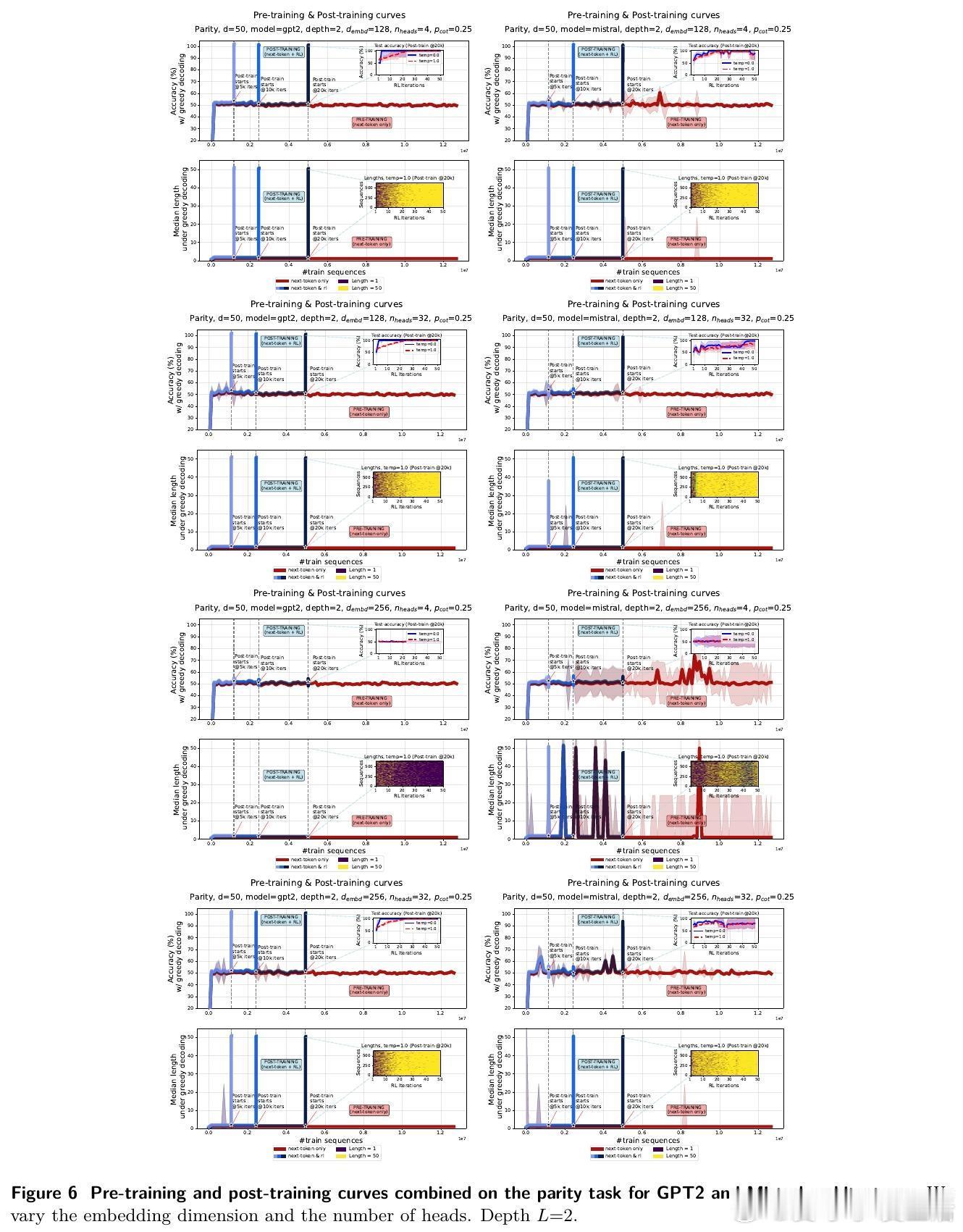
2️⃣ RL显著加速学习:引入RL后,模型迅速学会生成长推理链,准确率飙升至100%,且推理长度显著增长。
3️⃣ 长度增长机制:RL通过奖励正确长序列,放大长示例权重,推动模型输出更长、更细致的“思维链”,提升表达能力与泛化。
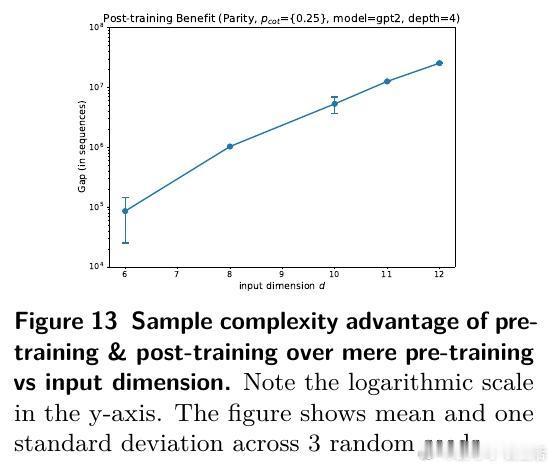
4️⃣ 理论验证:线性自回归模型证明RL后训练样本复杂度远低于纯预训练,且RL轮次仅需对数级别即可实现泛化。
5️⃣ 扩展实验:同样现象在数字乘法、数学推理(GSM8K、MATH)等更复杂任务和预训练模型(GPT2、Llama)上得到验证。
💡 深度启示
- RL不只是提升表达,更是优化样本利用率与训练效率,尤其是在复杂任务长推理样本稀缺时。
-“思维链”长度的增加,本质是模型学习能力提升的表现,而非仅是计算深度需求。
- 本文首次理论揭示了“逐词预测+RL”训练范式的优势和优化动力学,为未来LLM训练策略设计提供坚实基础。
🔗 原文链接:arxiv.org/abs/2510.11495