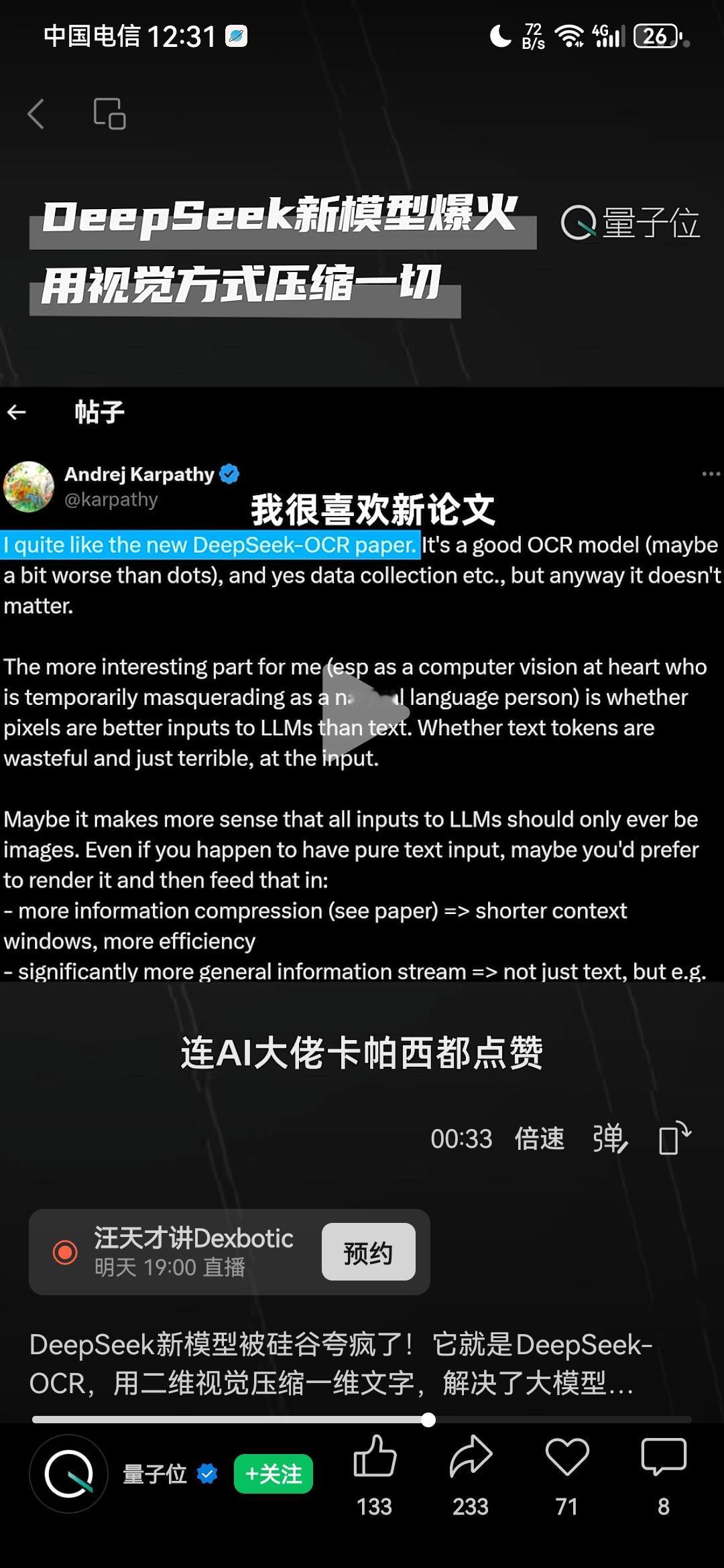
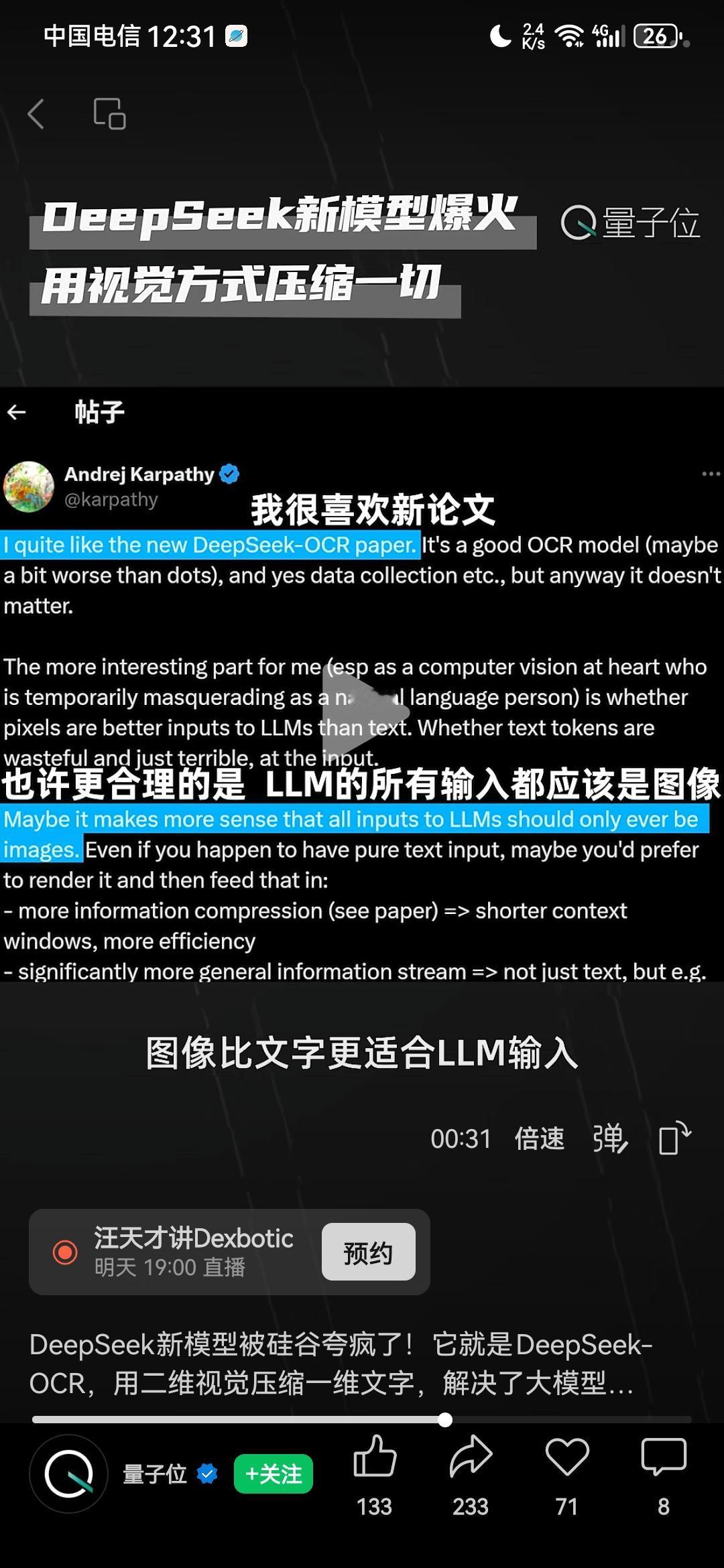
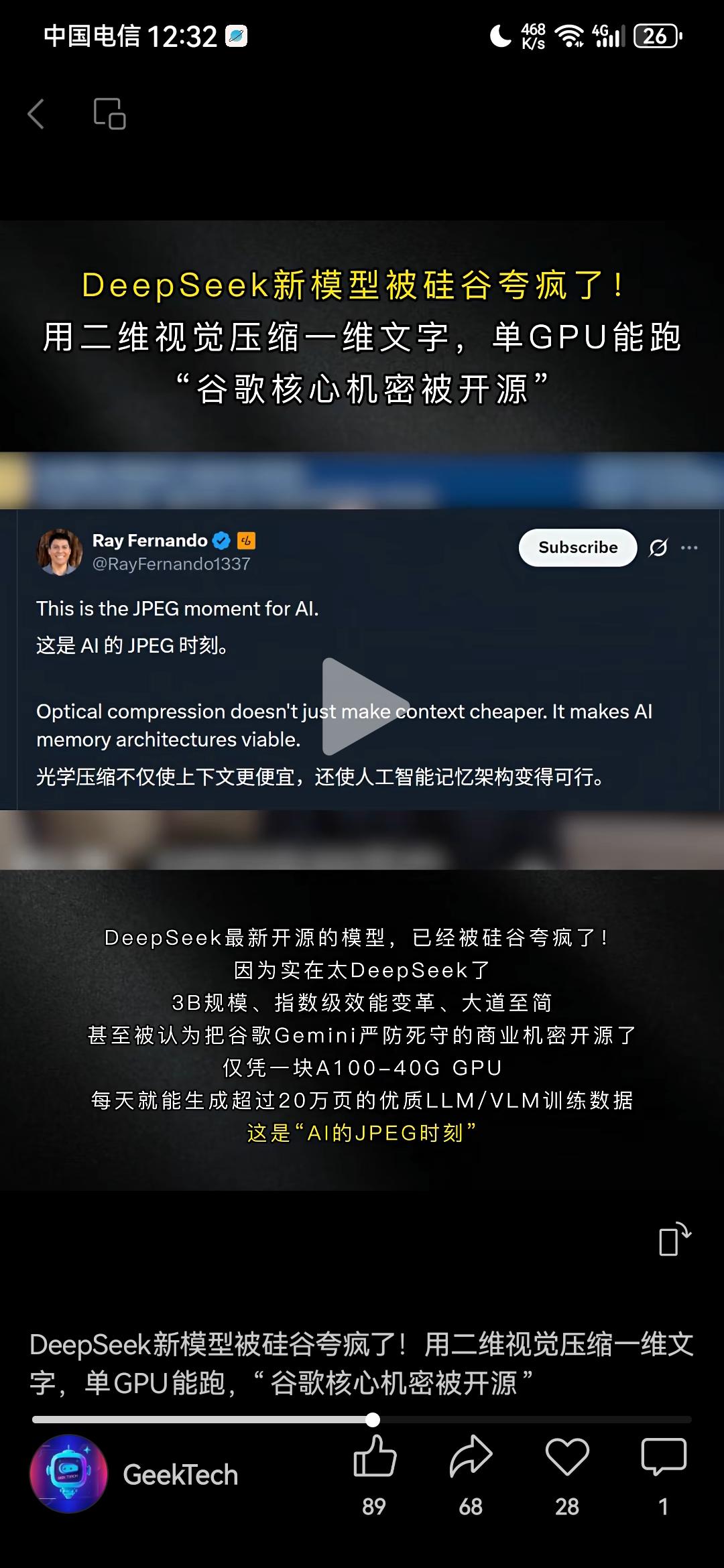
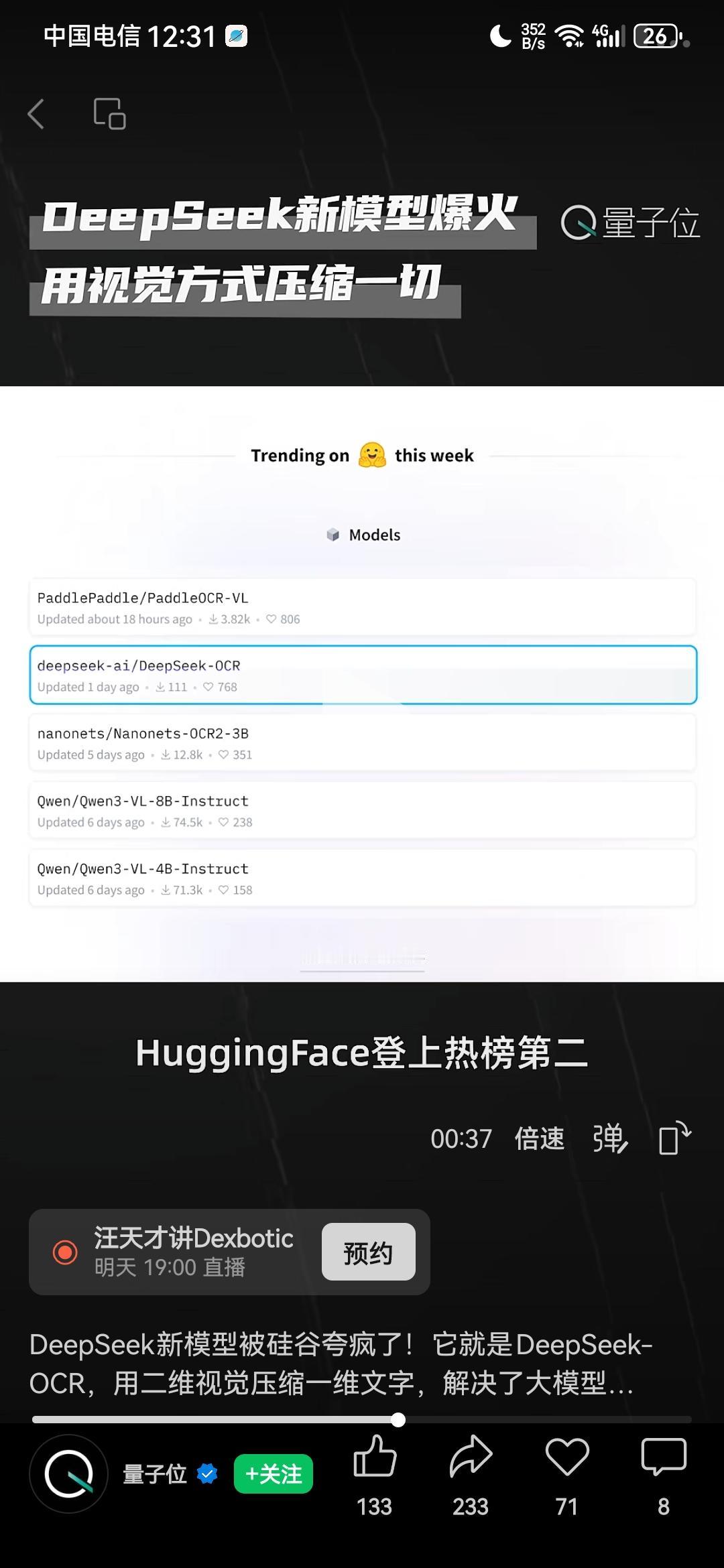
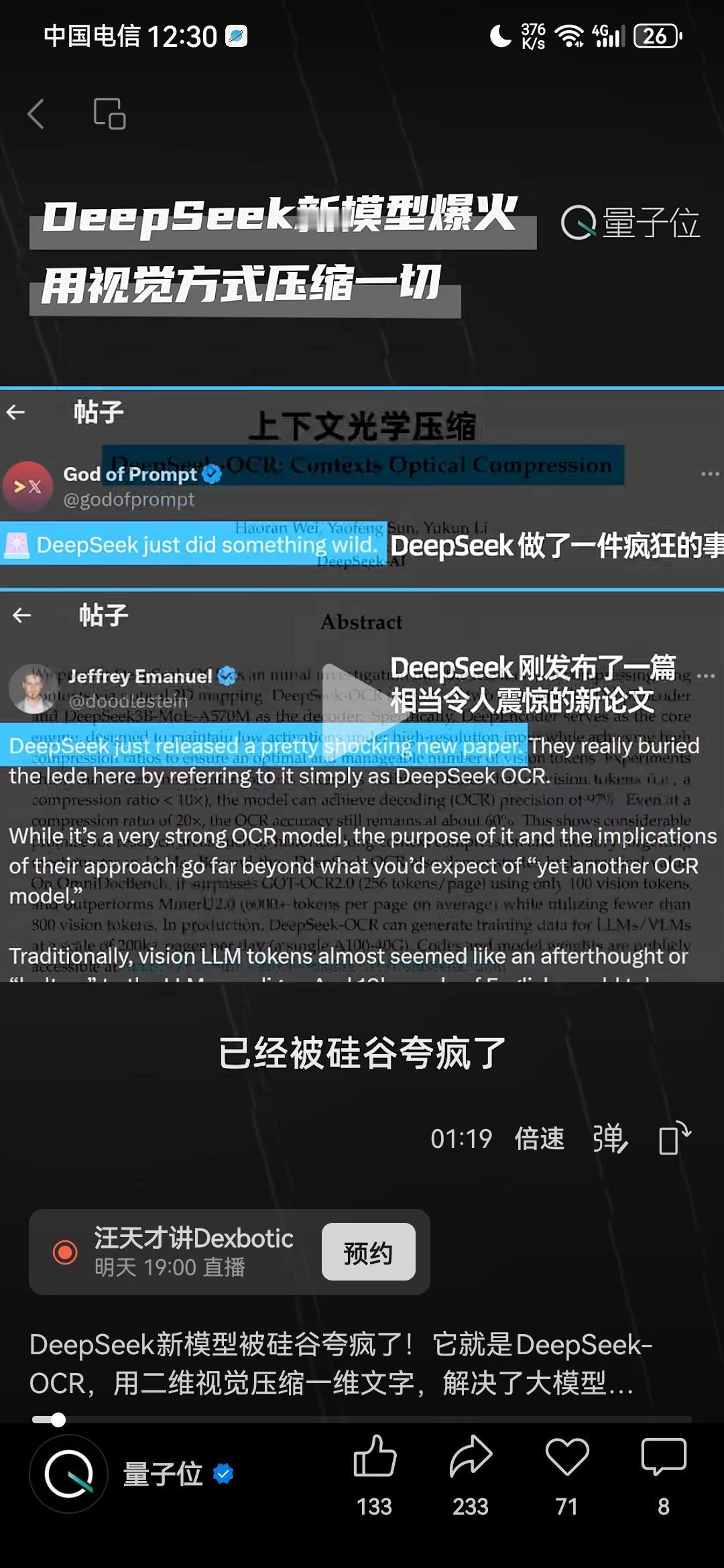
DeepSeek最近又一次震动了欧美,在硅谷掀起惊天狂澜,爆火整个人工智能圈子!因为其最新推出的一个新模型DeepSeek-OCR,解决了困扰诸多大模型许久的一个超级难题,对于人工智能来说堪称是又一个里程碑式的巨大突破!现在欧美所有人都为之震撼,实在是想不到,DeepSeek怎么这样牛逼,不声不响就又做出这么惊人的创新! 具体来说,就是以前的大模型,在处理长文本时,往往遇到巨大困难,随着文本字数的增长,处理长文本所需要消耗的token数量会“指数级增长”,计算成本会近乎于无限增长,就算是谷歌、微软那样的科技巨头,也无法承受那样巨大的计算成本,导致大模型处理长文本的能力,很快就会达到一个上限,而后再也无法突破。 但DeepSeek-OCR以一个出乎意料的方式解决了这个问题。 以前其他公司处理长文本的旧思路是,处理长文本,就老老实实用大模型识别那些长文本的文字。 现在DeepSeek-OCR的新思路则是,在处理长文本的时候,将那些“文字”转化成为“图像”,相比于记忆一个又一个文字,用视觉方式记载一张又一张图片,效率显然更高。 就这样一个思路的突破与创新,直接让大模型处理长文本的能力,发生了一个惊天动地的质变!这个突破有多么巨大呢?只需要列举一个数据,就能够很清晰地看出来了:OpenAI 的GPT-4Turbo,处理长文本的上限,是12万8千Token;DeepSeek-OCR处理长文本的上限,是1000万!直接超过OpenAI将近10倍! 一个12万,一个1000万,这就是DeepSeek-OCR的突破! 也正是因此,现在DeepSeek-OCR在海外彻底火了,爆火整个人工智能圈子,所有人都震撼到极点,DeepSeek-OCR的这个突破,对于人工智能来说,绝对是又一个里程碑式的巨大进步。 OpenAI联合创始成员、前特斯拉AI总监卡帕西(Andrej Karpathy),都专门在推特发文点赞;DeepSeek-OCR GitHub项目,更是1夜斩获4000+ Star,成为AI社区近期最受关注的开源模型,这个AI社区是全世界最权威最顶级的一个网上讨论平台了,结果所有顶尖人物都在这里关注DeepSeek-OCR;可以说,无数硅谷大佬都为之震撼失语。 这样的创新,谷歌没有做出来,微软没有做出来,马斯克也没有做出来,人工智能巨头OpenAI更没有做出来,但是DeepSeek却做到了!它又一次向全世界证明了自己的实力!







用户16xxx16
明明是超过接近100倍[哭笑不得]
脱贫致富
那个什么AI之母出来走两步
用户14xxx28
读者看了只知道小编一知半解,读者一脸懵逼