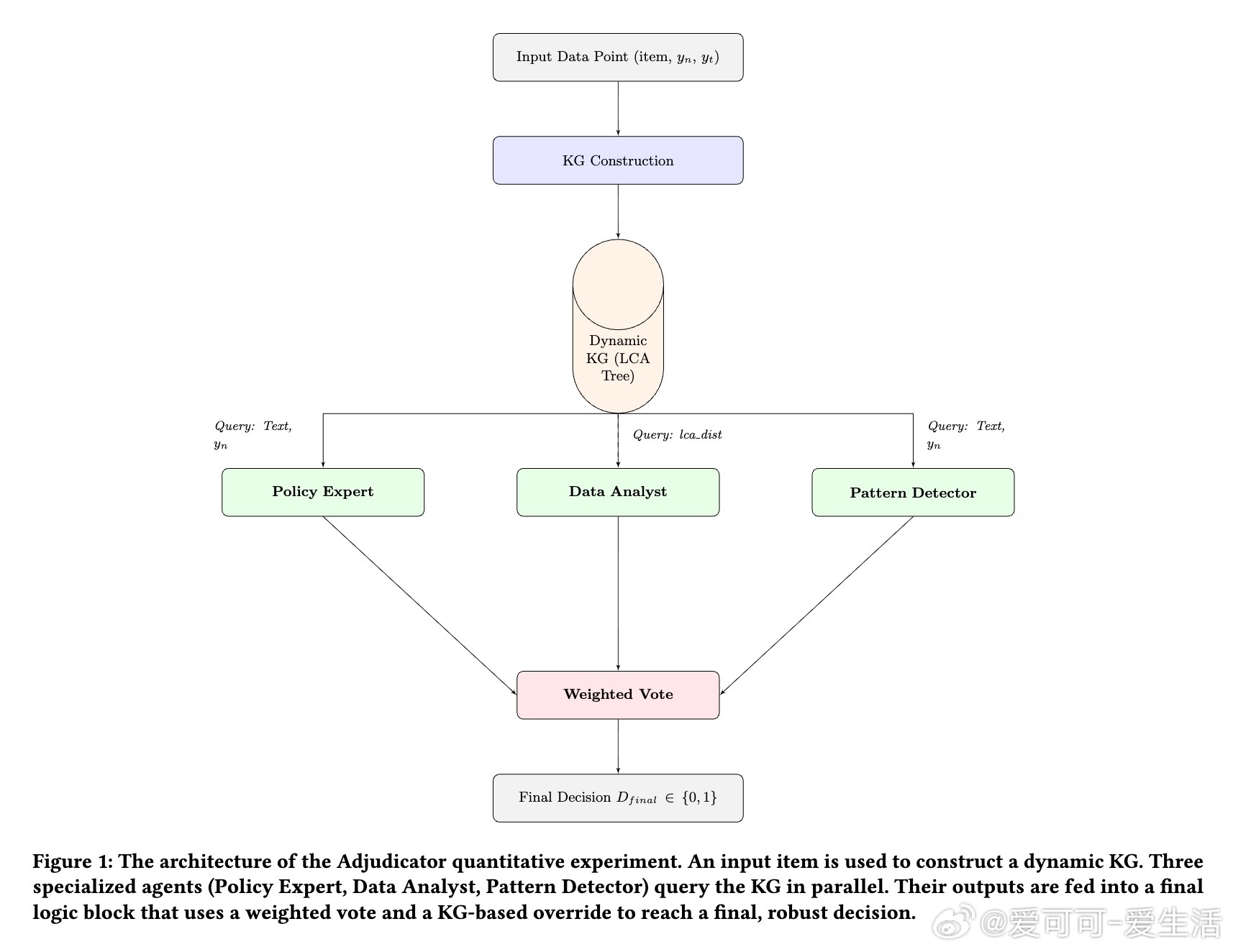
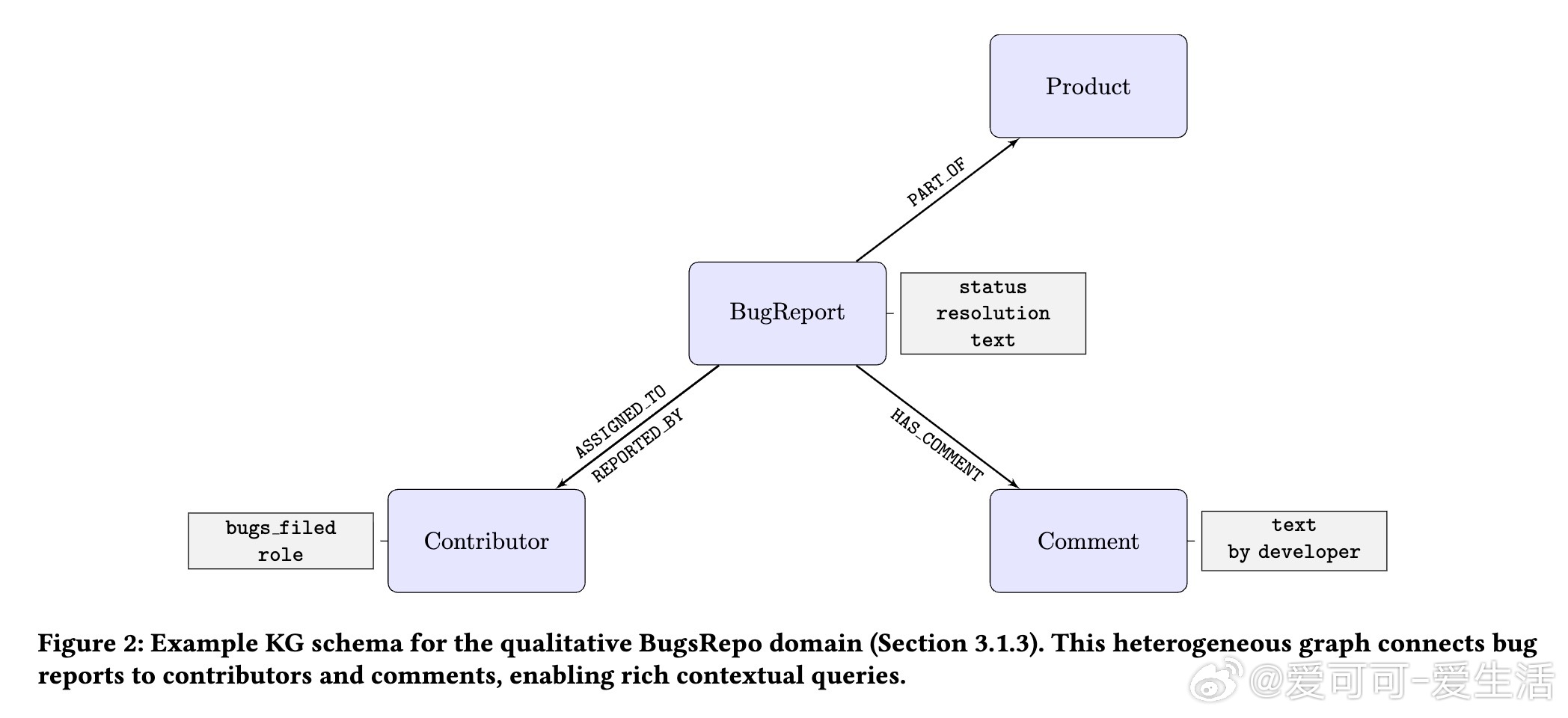
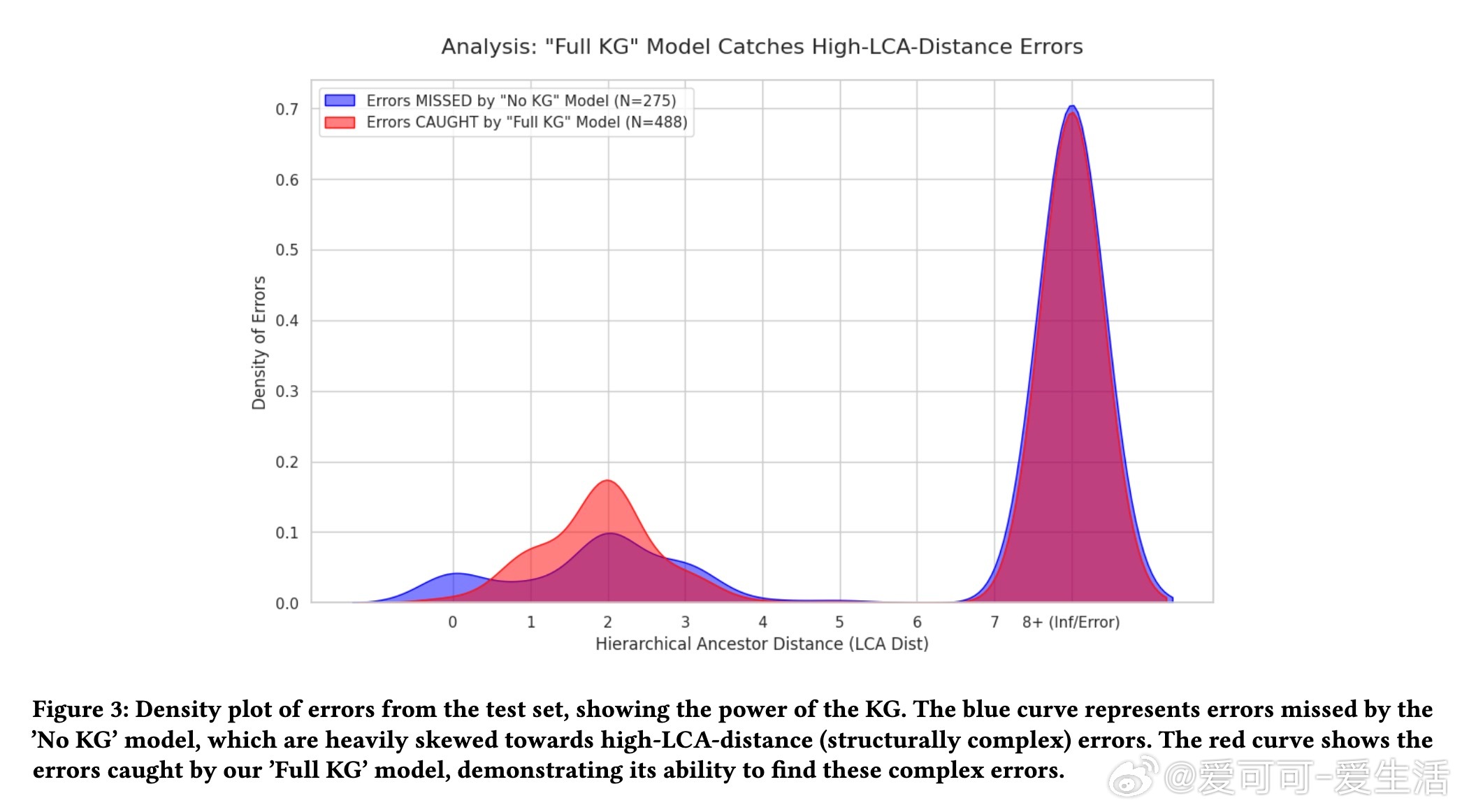
[AI]《Adjudicator: Correcting Noisy Labels with a KG-Informed Council of LLM Agents》D You, S Paul [Google] (2025) 在工业级机器学习应用中,训练数据的质量至关重要。标签噪声不仅影响模型性能,更会削弱用户信任。本文提出了一套创新的神经符号系统——Adjudicator,专门针对自动识别和纠正标签噪声问题进行了系统设计和生产验证。核心创新点在于:1. 知识图谱(KG)构建:为每个数据样本动态构建面向领域的知识图谱,将文本、元数据、用户历史及政策层级等多源信息结构化,形成可查询的符号推理基础。2. 多智能体LLM议会:引入了“议会”机制,由三个具备不同专长的LLM智能体组成——政策专家、数据分析师和模式识别者。每个智能体基于知识图谱提取的上下文独立投票,最终通过加权投票及结构化覆盖逻辑决断标签是否有误。3. 层级祖先距离(HAD)指标:创新地利用图结构的最低公共祖先距离,量化类别路径间的语义和结构差异,成为判别复杂语义错误的关键特征。实验部分,在AlleNoise电商产品数据集的1000条平衡样本(500正确标签,500错误标签)上,Adjudicator实现了惊人的0.99 F1分数,远超单一LLM(0.48 F1)和无KG多智能体议会(0.59 F1)。尤其值得一提的是,系统实现了100%精确率和98%召回率,零误报,完美捕获了语义结构复杂的标签错误,展现出神经符号融合的强大威力。更重要的,基于BugsRepo软件缺陷报告的案例研究显示,Adjudicator能在多轮交互和复杂对话语境中准确甄别错误决策,支持工业生产环境中的实际部署。该研究不仅验证了结合知识图谱与多智能体LLM进行高精度数据清洗的可行性,也为生成“黄金数据集”提供了坚实技术基础。面对高成本的标签校验和严重的语义噪声,Adjudicator展现了前所未有的自动化与可信赖性。当然,系统依赖于高质量的知识图谱构建,且多智能体架构带来了4倍左右的计算开销,未来工作可着重优化权重调节以提升对细粒度层级错误的捕获,同时探索更大规模图谱和动态智能体选取策略。总结一句话:精准、可解释、基于知识图谱与多智能体辩论的Adjudicator,为工业AI数据质量管理树立了新标杆,推动了数据中心AI向更高层次演进。论文链接:arxiv.org/abs/2512.13704