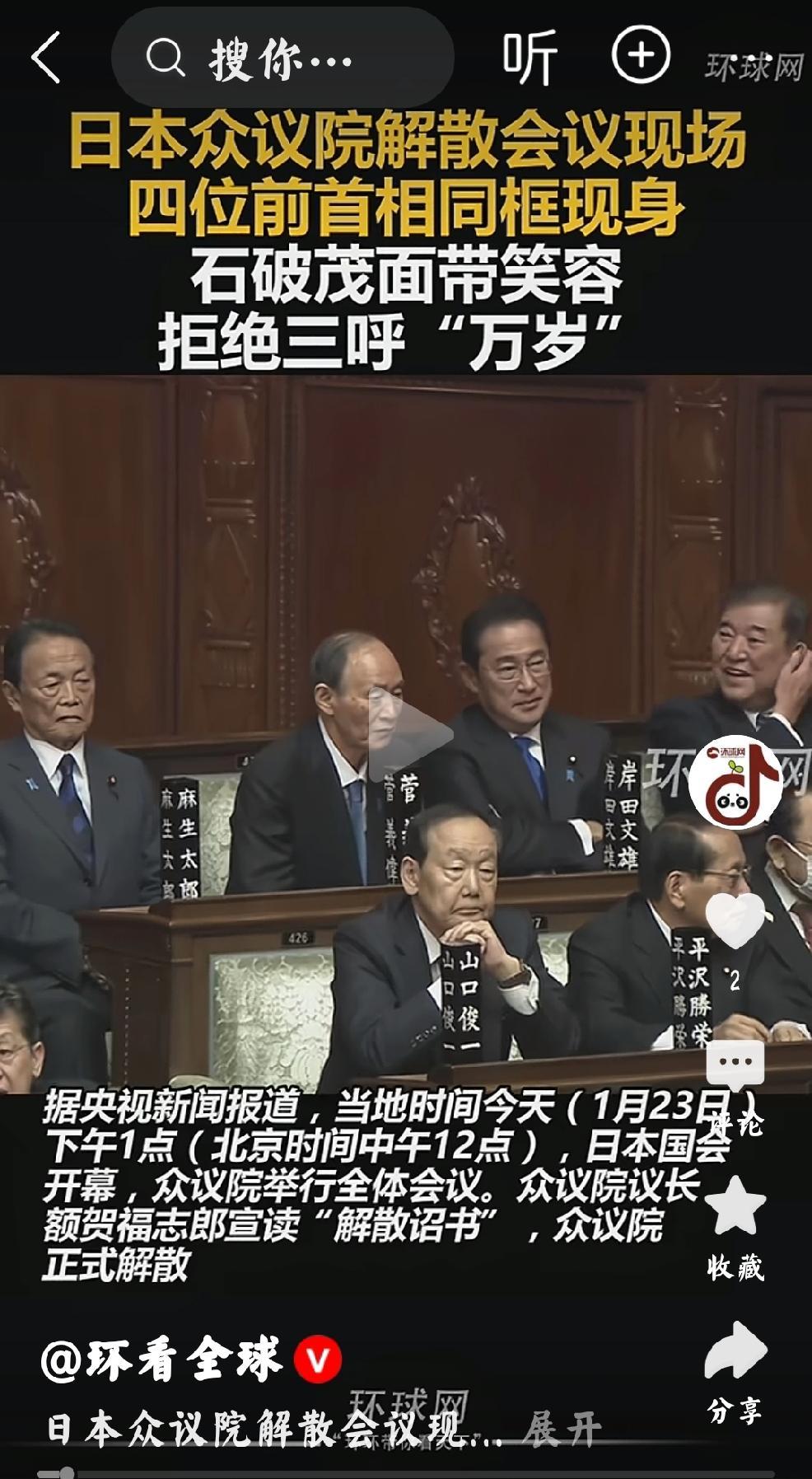
中国的强国地位被认可靠的是实力,而印度的地位却靠嘴吹。 在今年的瑞士达沃斯论坛上,印度派出了号称史上最豪华的阵容,至少6位部长和100多位CEO参与各种论坛。目的就是为了宣讲印度经济增长的“故事”,并且“纠正他人对印度的错误认知”。 果然,当国际货币基金组织把印度列为人工智能的“第二梯队强国”时,那位信息技术部长急得当场开课,从软件外包扯到班加罗尔科技园,恨不能把"我们和中美平起平坐"刻在西装袖口。 可台下懂行的人都知道,就在中国DeepSeek开源通用大模型的前一年,印度AI圈还在为"有没有像样的本土算法"发愁。 2023年以前,印度AI领域最拿得出手的,是几家给美国大厂做数据标注的外包公司。班加罗尔的科技园里,贴着"AI独角兽孵化基地"的招牌下,真实场景是程序员们熬夜标注自动驾驶数据,每小时赚3美元。 直到DeepSeek开源Model 1.0,印度媒体才突然发现:这个被他们常年嘲讽"抄袭硅谷"的中国项目,居然在代码质量、训练数据量上甩出印度本土模型三条街。 更扎心的是,印度理工学院培养的AI博士,70%毕业后直接加入硅谷,剩下的要么去外企驻印分部,要么在政府项目里写PPT——德里某部委2022年的AI战略白皮书,核心算法部分直接引用了斯坦福公开课的教案。 有人会说,印度不是有塔塔、Infosys这些科技巨头吗?没错,但这些公司的AI业务基本是"组装厂模式":从英伟达买芯片,用TensorFlow框架,雇三哥程序员调参数,最后包装成"印度自研AI解决方案"卖给中东土豪。 2024年孟买证券交易所披露的数据显示,印度TOP10 AI企业的研发投入总和,还不到中国一家中型AI公司(比如商汤科技)的三分之一。 更绝的是,当中国开源社区已经有超200个大模型可供调用时,印度最大的AI开源平台上,最热门的项目是"用Python写的奶茶店订单管理系统",下载量刚过万。 对比太刺眼。中国AI企业早在2018年就开始砸钱搞底层研发,百度飞桨、华为昇腾,哪个不是从芯片到框架全链条打通? 2023年DeepSeek开源时,光训练数据就用了2万亿,相当于把整个维基百科+全球前100网站内容来回嚼三遍。 而印度同期最先进的AI模型,训练数据量不到人家百分之一,还包含大量从社交媒体爬的低质内容——有印度程序员吐槽,他们的模型经常把"泰姬陵"认成"红色城堡",因为训练集里太多宝莱坞电影截图。 印度的"嘴强王者"传统,在AI领域暴露得淋漓尽致。2025年国际AI顶会统计显示,印度学者发表的论文数量排全球第五,但引用率倒数第十,很多研究停留在"证明理论可行"阶段。 而中国团队已经在解决实际问题:黄河防汛用上了AI洪水预测模型,准确率比传统方法高40%;内蒙古的治沙无人机,靠AI识别每一株沙棘的生长状态。 这些落地场景,印度不是没想过,而是根本玩不转——2024年德里试点的AI交通调度系统,上线一周就因算力不足瘫痪,最后不得不找中国云服务商紧急扩容。 最讽刺的是人才。印度每年培养10万计算机毕业生,可本土AI公司留不住人。2023年一份行业调查显示,印度AI从业者的平均跳槽周期只有14个月,原因很现实:本土企业给的薪资是美国同岗位的1/5,项目还大多是"政府面子工程"。 反观中国,2025年AI人才平均年薪涨到58万,华为天才少年计划直接给百万起薪,这种环境下,谁愿意留在印度写PPT? 有人可能疑惑,印度不是有庞大的英语人口和软件外包基础吗?错了。AI时代最值钱的不是代码搬运工,而是能定义问题的人。当中国团队在黄河边用AI优化调水调沙时,印度的AI专家还在争论"是否应该禁止AI写宝莱坞剧本"。这种格局差距,比技术差距更致命。 回到达沃斯的那个场景:印度部长激昂陈词时,台下中国工程师正用手机查看国内的AI防汛系统——当天黄河小浪底的调水调沙数据,通过AI模型实时更新,误差不到0.5%。 这就是实力的分量:你可以在论坛上买通稿、雇水军,但当洪水来了,能救命的永远是实实在在的代码,而不是PPT里的"第一梯队"。