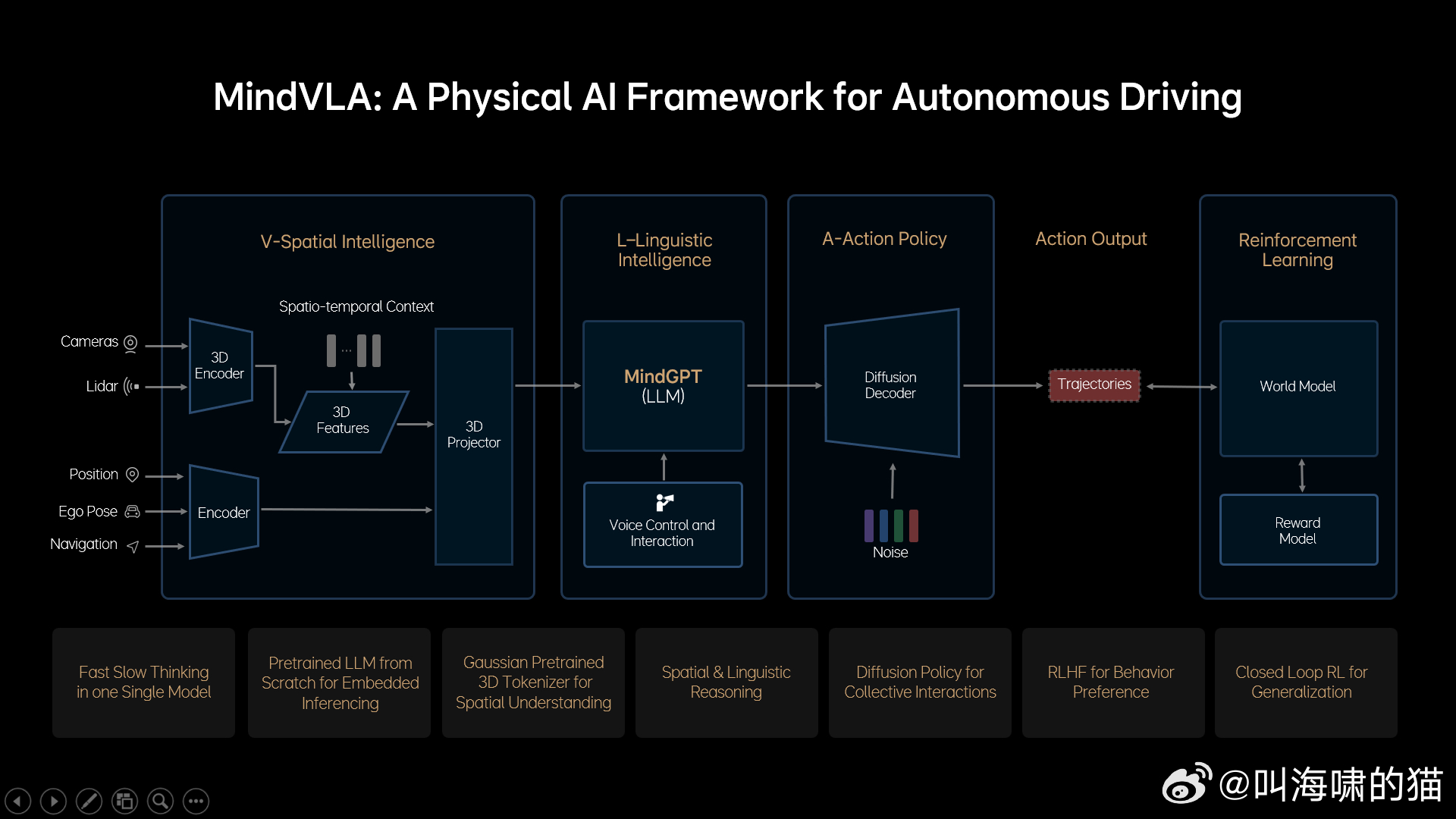
仔细看了下理想VLA的介绍,感觉最大的变化,就是引入大语言模型,和3D表征一起,共同输出行为轨迹。
可以看到理想整篇文章里,提到最多的就是怎么对大语言模型进行后训练和工程化,让其满足智能驾驶低延迟的需求,包括像DeepSeel一样用到了MoE专家模型。
理想的表达是“为了解决这些问题,我们需要自己从0开始,设计和训练一个适合VLA的基座模型,因为任何开源的LLM模型都不具备这样的能力”。
“在这个新的基座模型训练过程中,我们花了很多时间去找到最佳的数据配比,融入了大量3D数据和自动驾驶相关的图文数据,并减少了文史类数据的比例。
最后,为了进一步激发模型的3D空间理解和推理能力,我们加入了未来帧的预测生成和稠密深度的预测等训练任务。”
明显能看出来,理想对大语言模型的改造工程相当之大,好在自己做了MindGPT。
最后呈现给用户端的体验,会有哪些大的亮点?其实不多,主要还是交互的拟人化,比如语音控制智驾系统。
当然,对于系统来说,智驾本身的决策过程应该也会更有思考性,这一点,用户估计需要花更多时间才能感知到。
智驾技术似乎也要进入狭长甬道了,为了一些微观的体验提升,而投入大量技术和工程改进,然后等待积累到下一个爆发点。