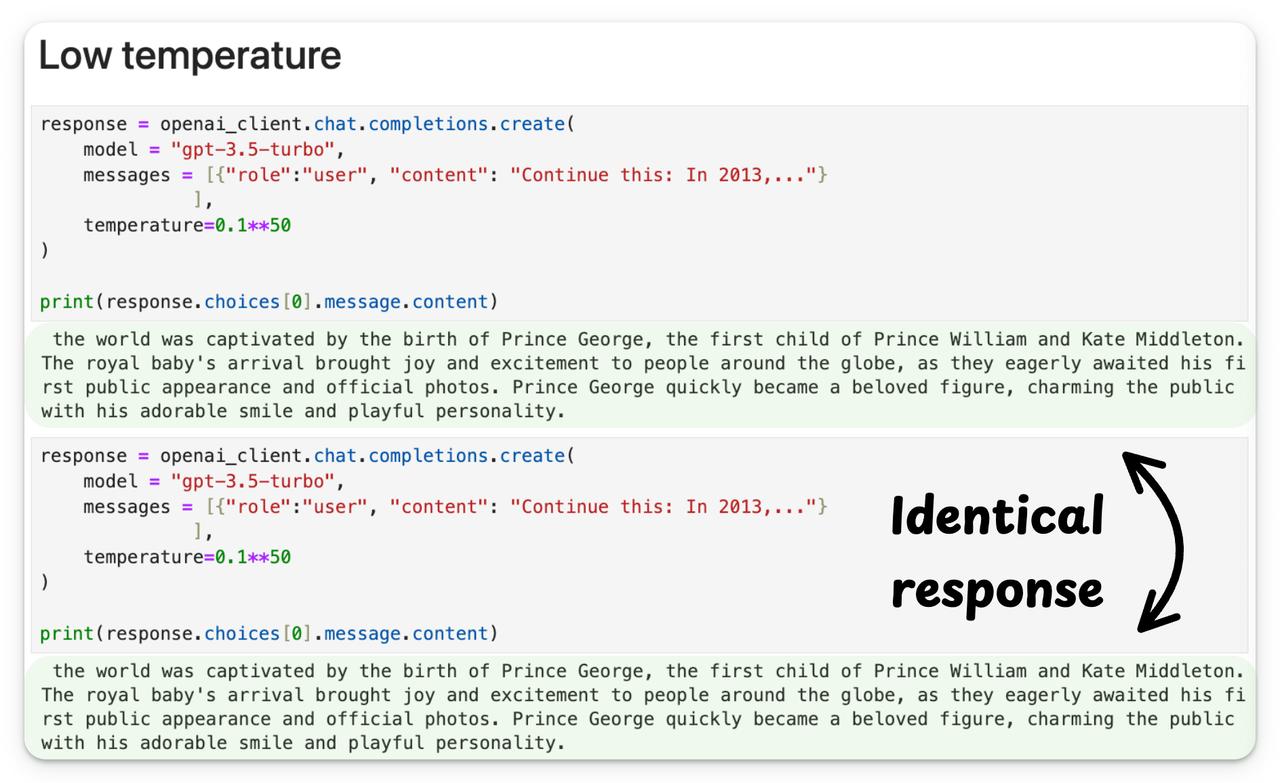
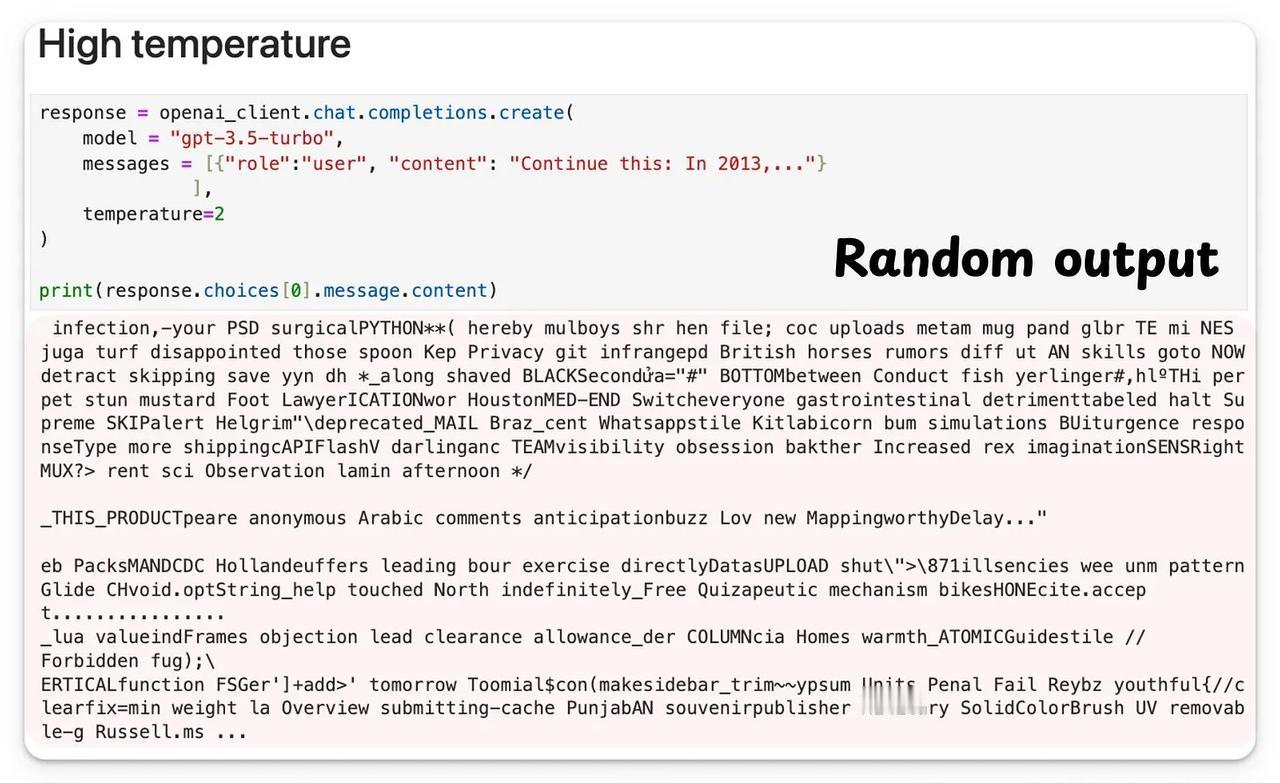
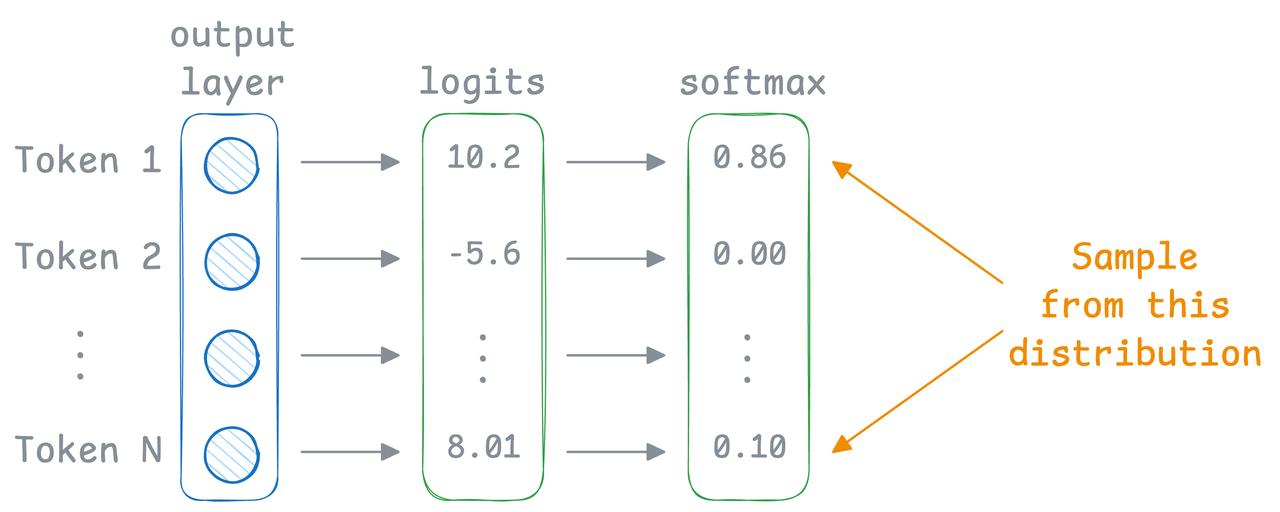
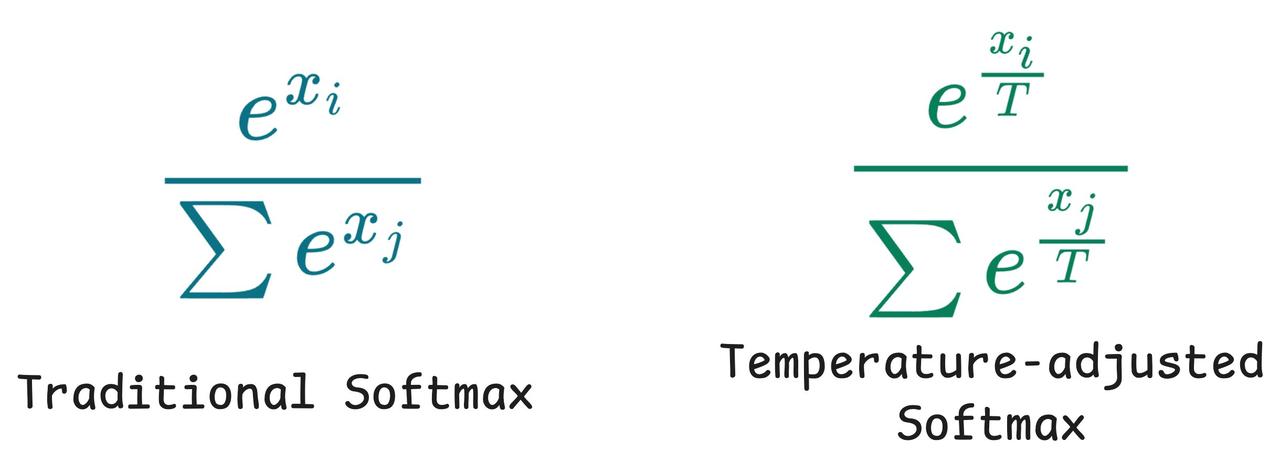
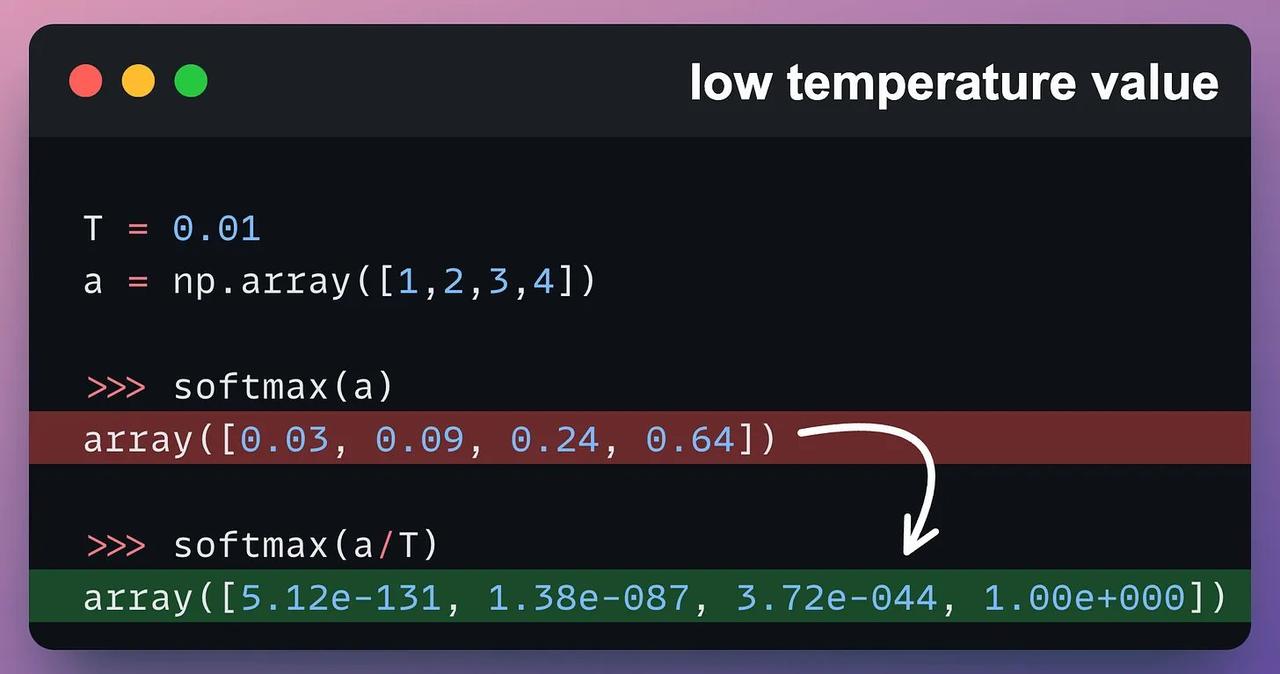
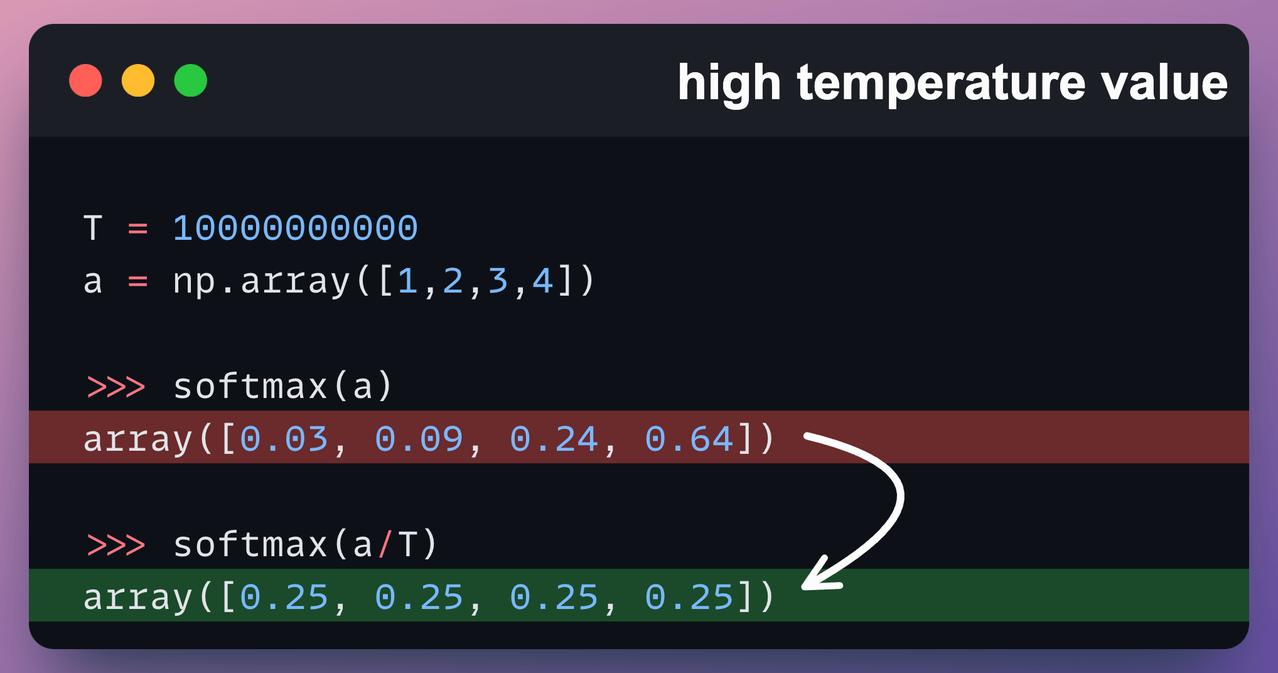
调整不了气温,但还可以调整温度参数(Temperature)。 了解大模型的朋友,对这个参数可能都不陌生。温度参数是影响大语言模型生成内容的关键要素,它通过调控模型输出的概率分布,从而决定了生成文本的随机性和多样性。 今天,一起跟随科技博主Akshay的脚步,重温一下这个关键的参数概念: 比如,当我们使用较低的温度参数连续两次给模型提示词,他会生成完全相同的两个结果。【图1】 但如果你将温度参数调高,它就会开始生成一些杂乱无章的回复。【图2】 这背后的原理是什么呢? 文本生成类大语言模型的工作原理类似于分类模型,其输出层覆盖整个词表空间。【图3】 但不同于直接选择最优token的常规分类,它们会基于概率分布进行“概率采样”。 也就是说,即使“Token 1”的softmax分数最高,由于概率采样机制的存在,最终也可能不会被选中。 采样行为的影响通过温度参数(Temperature)进行调控。该参数会对softmax函数进行如【图4】的调整。 当温度参数较低时,概率分布会趋近于“最大值”而非“soft-max”分布。 也就是说,当温度参数较低时,高概率的token的概率会进一步提高,而低概率的token的概率会显著降低。 这意味着采样过程几乎必然选择最高概率的token,使得生成结果呈现(近乎)贪婪策略的特征,模型总是选择它认为最准确、最安全、最直接的词。【图5】 当温度参数较高时,概率分布会趋于均匀分布。 这意味着采样过程可能选择任意token,导致生成结果变得随机且高度不确定,正如我们此前观察到的现象。【图6】 所以,关于温度参数(T),这里还有一些最佳实践建议: - 设置较低T值可生成确定性较强的响应 - 设置较高T值可获得更随机、更具创造性的输出 - 如【图2】所示,极端高T值通常缺乏实际应用价值