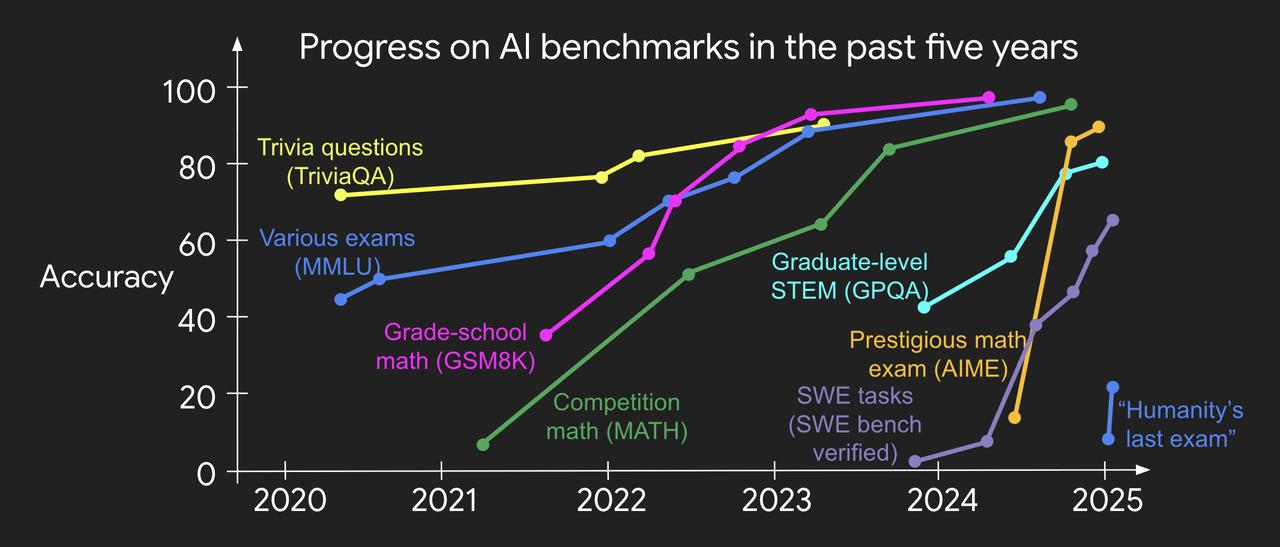
#思维链一作没回应是否被挖##思维链一作谈验证不对称性# 那边Hyung Won Chung卖关子,Jason Wei本人也没闲着。 没有回复铺天盖地被Meta挖走的传闻,反倒是罕见的连发两条X,不谈八卦,全是硬货,话题都和强化学习息息相关: - 验证不对称性与验证者定律【图1】 - 策略内学习【图2】 这两个听起来有点拗口的概念,实际还能和人生联系起来。一起来看看他都讲了啥: 一、验证不对称性与验证者定律 什么是验证不对称性?简单来说就是,有这么一类任务,判断对错比解决问题本身容易太多了。 验证不对称性很重要,也是纵观深度学习发展史后得出的结论。历史告诉我们:任何可被量化的目标,最终都能被优化。 用强化学习的术语来说,验证解决方案的能力等同于创建强化学习环境的能力。因此,可以得出一条验证者定律: 训练AI解决某项任务的难易程度,与该任务的可验证性成正比。所有可解决且易验证的任务,终将被AI攻克。 更准确地说,AI能否成功训练来解决某项任务,取决于该任务是否具备以下特质: - 客观真理性:所有人都能就优质解决方案达成共识 - 快速可验证:任何给定方案都能在数秒内完成验证 - 批量可验证:能够同时验证大量解决方案 - 低噪声性:验证结果与解决方案质量高度相关 - 连续奖励性:能轻松对同一问题的多个解决方案进行优劣排序 这条定律的正确性不言而喻:过去AI领域提出的主流基准测试几乎都易于验证,也相继被攻克。【图3】 二、策略内学习 策略内学习是强化学习的核心概念:与其模仿别人的成功路径,不如自己采取行动并从环境反馈中学习。 初期可能靠模仿走得更快,但一旦能走出合理路径后,就应该要尝试发挥出自己的优势。 Jason举了个例子:在训练语言模型解决数学应用题时,强化学习比简单模仿人类思维链的监督微调更有效。 他说:“人生也是这样。” 我们最初通过模仿学习起步,但最终会意识到:我们永远无法超越别人,因为他们在发挥我们根本不具备的优势。 策略内学习的启示在于:要超越老师,就必须走自己的路,承担环境给予的风险与奖励。 他介绍了自己特别享受的两件事:(1)海量阅读数据,(2)通过消融实验理解系统各组件的相互作用。 他表示,虽然耗时,但这些实验让他对RL的有效性获得了独到见解。 总结一句话:起步靠模仿,突破靠探索。 读完这两篇推文,虽然还是不知道他跳槽了没有,但至少知道了两件事: - 任务越容易验证,越容易被AI学会; - 走别人没走过的路,才可能走得更远。 最后再八卦一句,Jason Wei还转发了一条Hyung Won Chung刚刚发送的康奈尔演讲视频。【图4】 要知道,Jason Wei之前发X可没那么勤快,而且也没怎么转发过Hyung Won Chung的贴文…… 处于聚光灯下的两人,到底是在释放一个什么信号呢?