[CL]《Efficient Knowledge Probing of Large Language Models by Adapting Pre-trained Embeddings》K Sharma, Y Jin, R Trivedi, S Kumar [Georgia Institute of Technology & MIT] (2025)
PEEK:用预训练嵌入模型高效估计大语言模型(LLM)知识全景
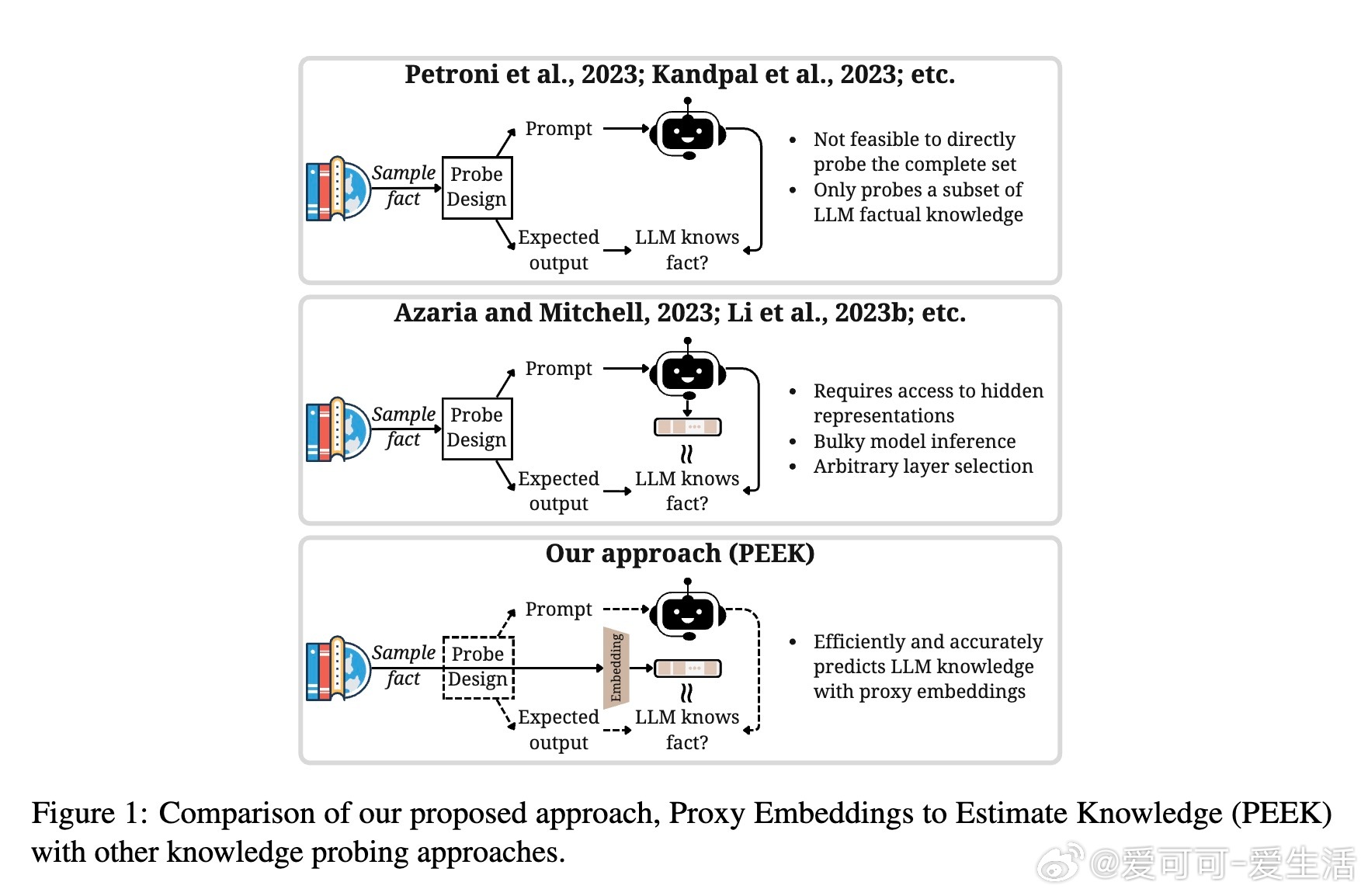
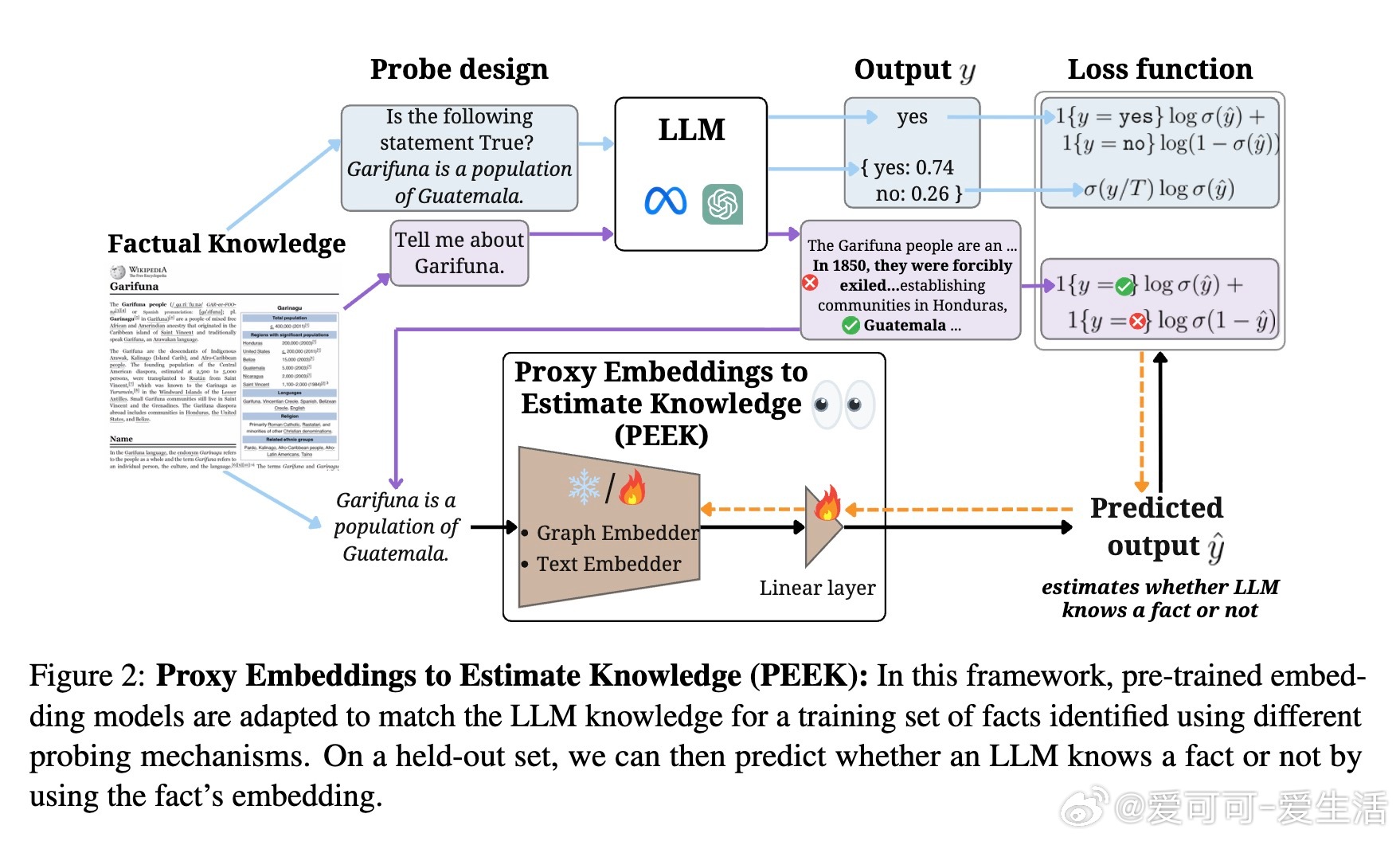
• LLM虽拥有跨领域知识,但直接探测成本高、效率低,PEEK提出用预训练句子嵌入模型作为代理,通过线性层微调预测LLM对事实的掌握情况,避免频繁调用庞大模型。
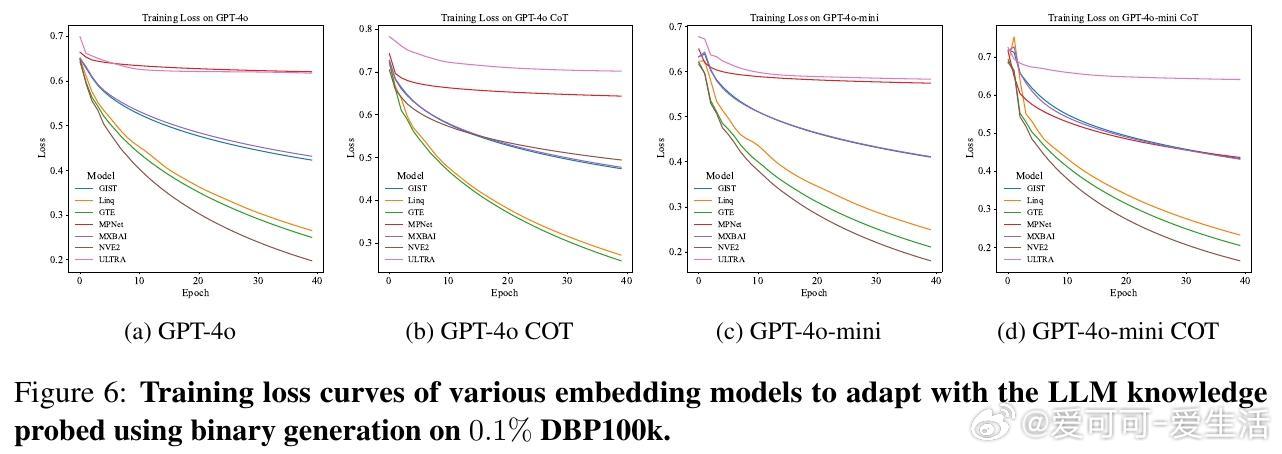
• 覆盖四种知识探测方式:二元事实生成(yes/no)、二元logits预测、隐藏层激活预测、长文本事实生成,全面映射LLM知识空间。
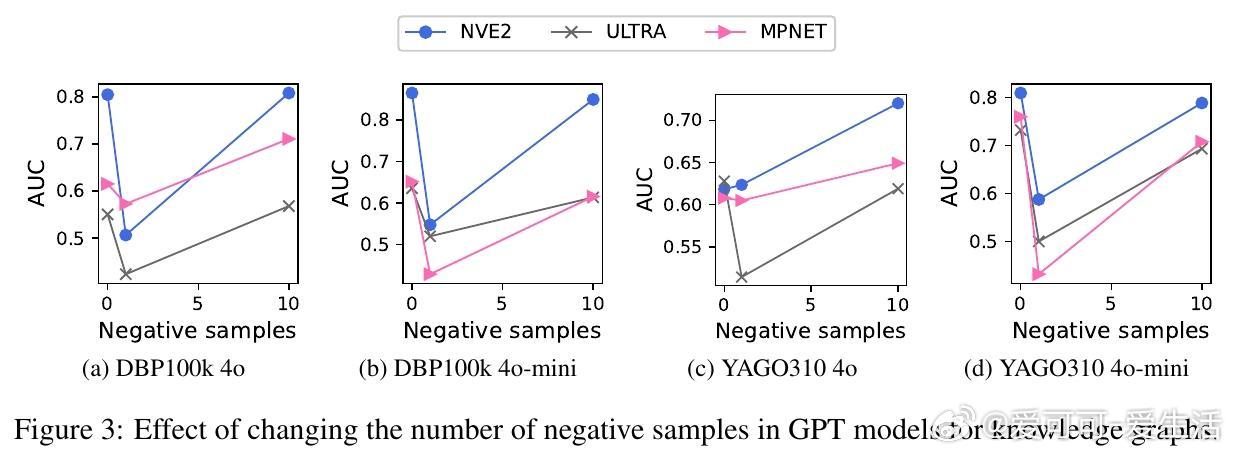
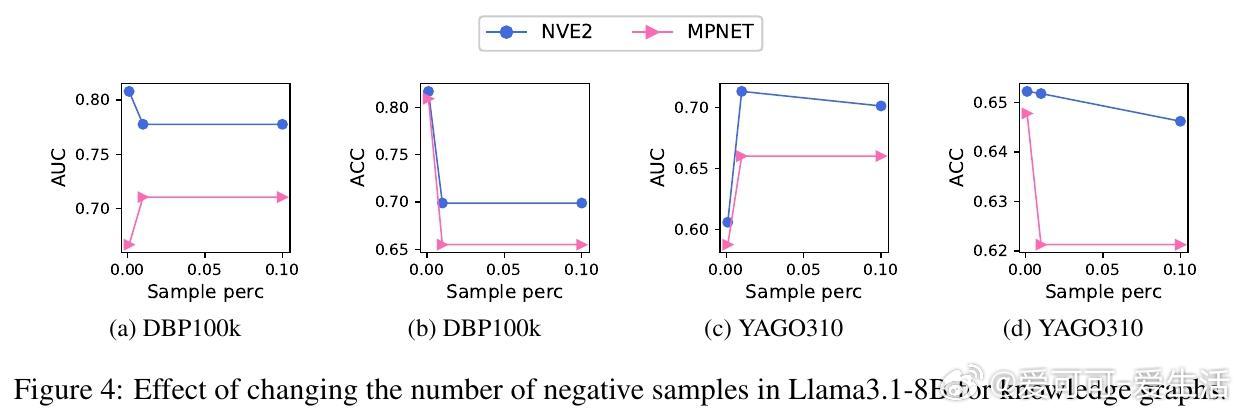
• 33个维基百科衍生数据集、7种嵌入模型、4款主流LLM实测,嵌入模型准确率最高达90%,句子嵌入优于图神经网络嵌入,揭示LLM知识编码偏向文本语义而非图路径结构。
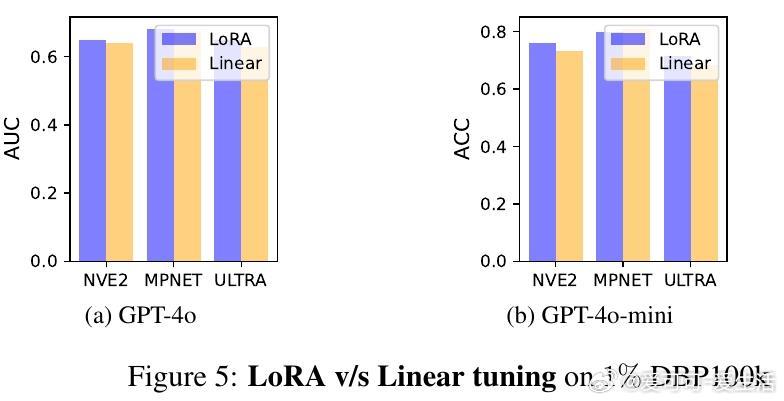
• 线性调优与LoRA微调效果相近,证明事实知识隐含于嵌入空间,简单线性映射即可捕捉,极大提升知识探测效率和可扩展性。
• PEEK可用于LLM部署前知识缺口识别、辅助检索增强生成过滤已知事实、辅助幻觉检测与模型编辑,降低模型风险与维护成本。
• 未来可探索动态适应的嵌入代理、专用领域嵌入训练及更复杂推理任务估计,推动LLM知识理解和安全应用边界。
详细研读👉 arxiv.org/abs/2508.06030
代码与数据👉 github.com/claws-lab/peek
大语言模型知识探测预训练嵌入机器学习人工智能