深度解析为何不推荐 Ollama,推荐多 GPU 服务器使用 vLLM 或 ExLlamaV2:
• Ollama 实质上是 llama.cpp 的封装,未跟进最新多 GPU 及 Tensor Parallelism 优化,导致多卡环境下严重拖慢整体性能。
• llama.cpp 适合 CPU 或单卡环境,支持 CPU offloading,适合 GPU 资源有限的用户,但不支持批量推理和多 GPU 并行,无法发挥多卡优势。
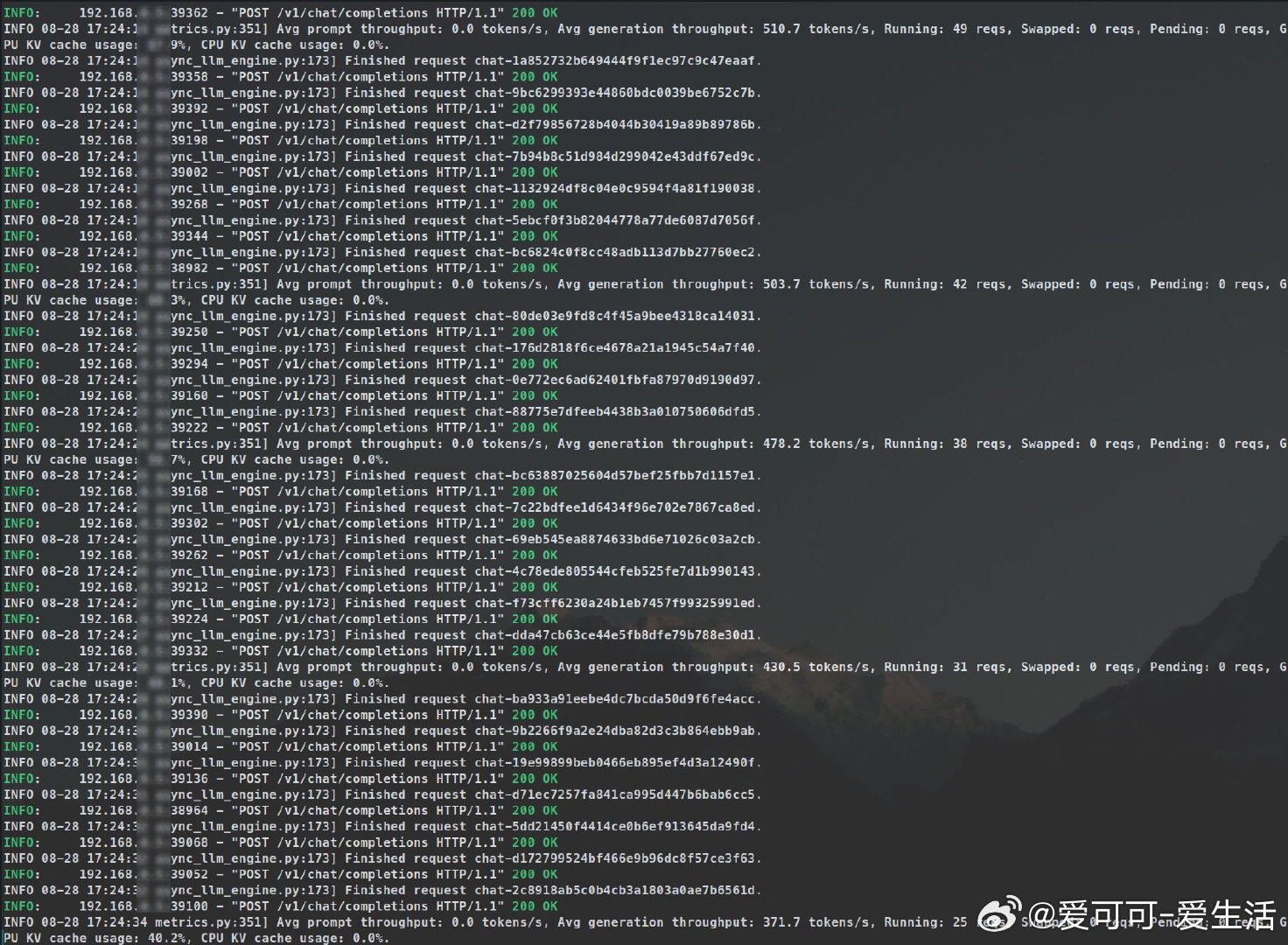
• vLLM 与 ExLlamaV2 均支持 Tensor Parallelism 和批量推理,能够将大型模型计算分摊到多张 GPU,实现显著加速,尤其适合 8+ 卡服务器。
• ExLlamaV2 独创 EXL2 量化算法,在显存受限时表现优异,兼顾速度与精度,适合高效批量推理。
• 作者自建 14 卡 RTX 3090 AI 服务器,实测 vLLM 和 ExLlamaV2 大幅领先 Ollama 和 llama.cpp,轻松处理数千异步请求,性能稳定且资源利用率高。
• Ollama 仅适合单卡、简单聊天模型,批量任务或复杂推理时极易卡顿,且环境配置和显存分配不合理,使用体验差。
• 推荐从源码级别理解推理引擎差异,避免被闭源工具锁定,提升本地 AI 服务稳定性和自主可控性。
心得:
1. 多 GPU 服务器使用支持 Tensor Parallelism 的推理引擎是释放硬件潜力的关键,避免用不支持的工具造成资源浪费。
2. 量化技术和模型架构深度结合,能在保持准确度的同时极大缩减显存和计算需求,提升整体效率。
3. 彻底掌握推理引擎和硬件架构细节,远比盲目追随闭源产品更能保障长期技术优势和业务连续性。
详情阅读👉 ahmadosman.com/blog/do-not-use-llama-cpp-or-ollama-on-multi-gpus-setups-use-vllm-or-exllamav2/
多GPU 推理引擎 vLLM ExLlamaV2 本地AI TensorParallelism llama_cpp Ollama