[LG]《Distilled Pretraining: A modern lens of Data, In-Context Learning and Test-Time Scaling》S Goyal, D Lopez-Paz, K Ahuja [FAIR at Meta] (2025)
Distilled Pretraining(蒸馏预训练)为现代大语言模型(LLM)带来了全新视角,揭示了数据利用、上下文学习与测试时扩展能力间的复杂权衡。
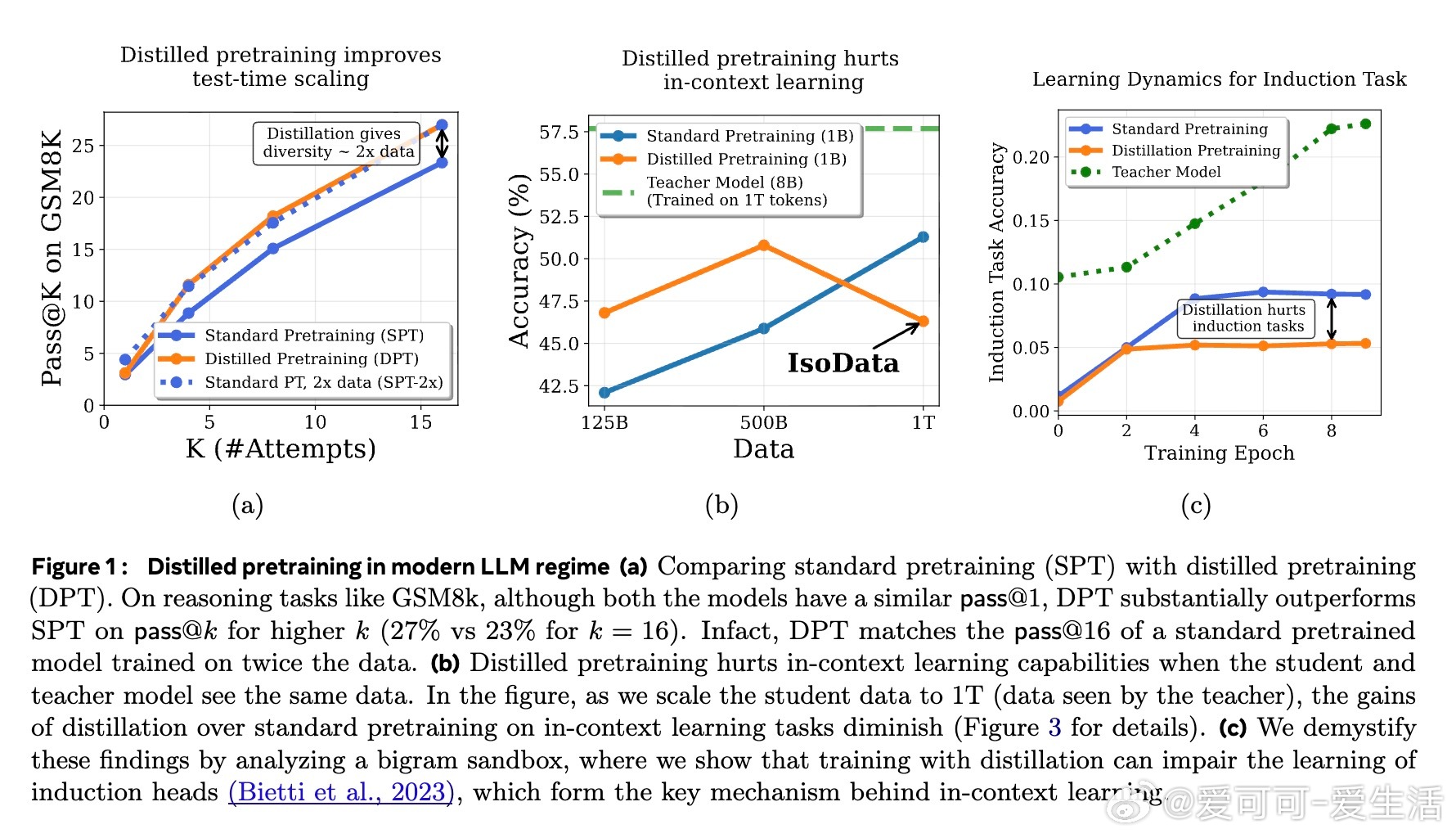
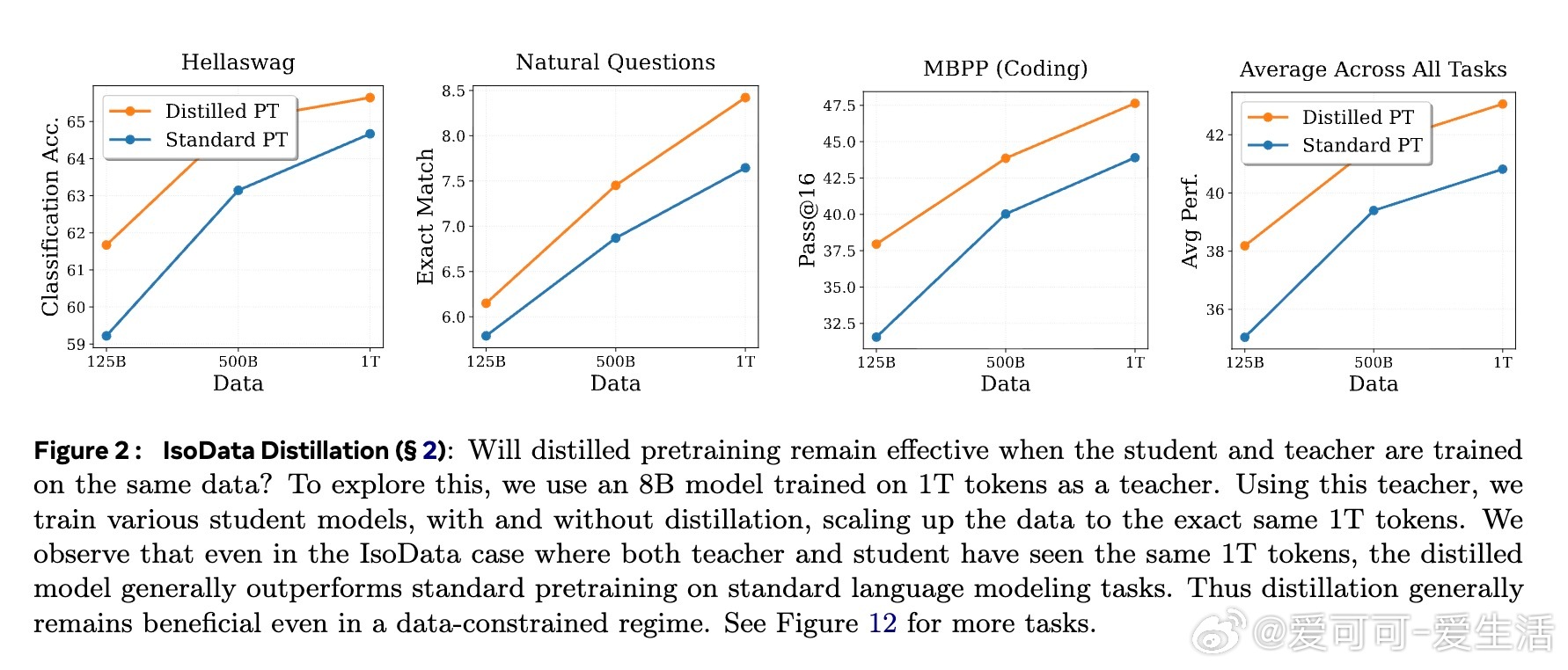
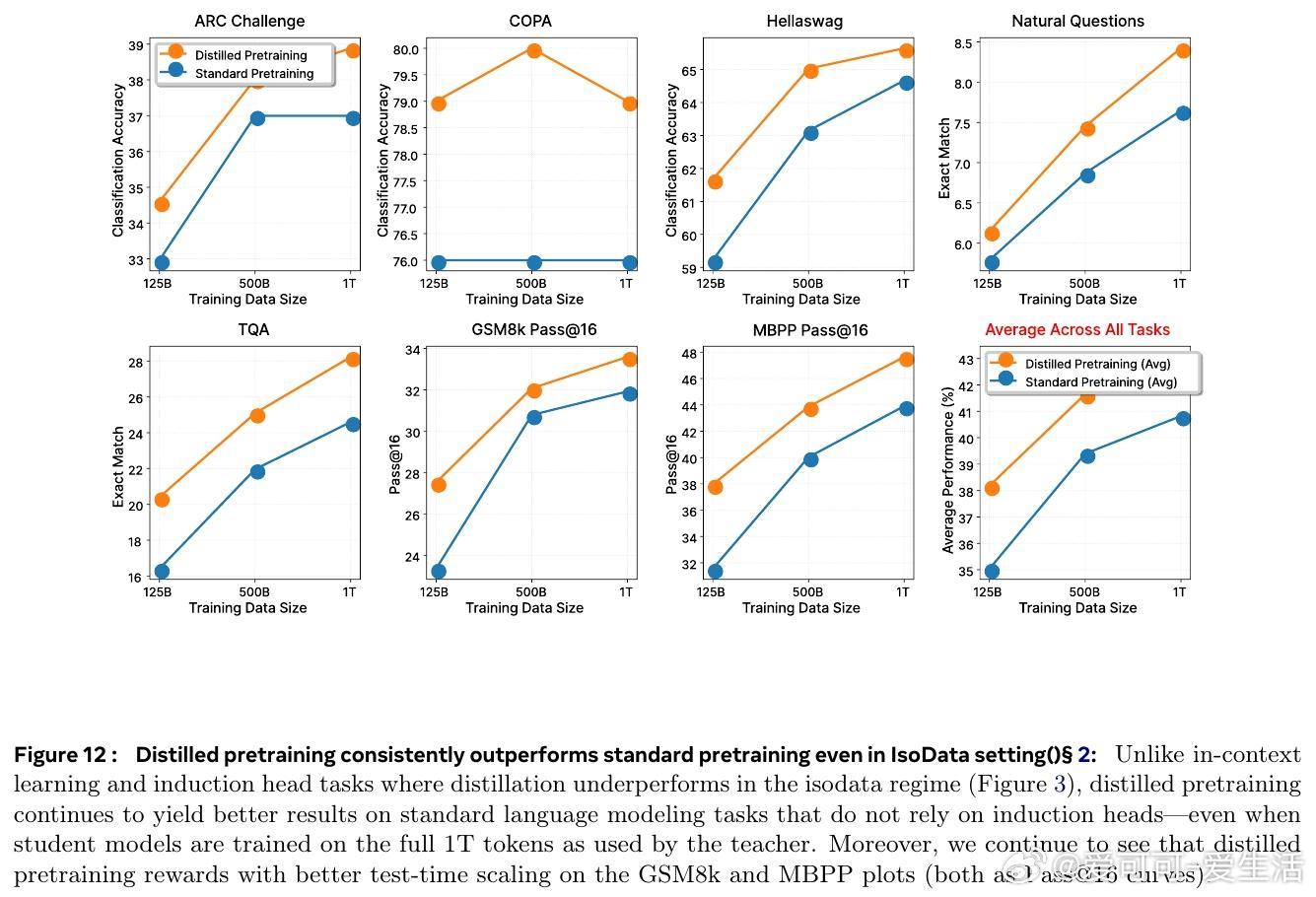
• 即使在数据完全共享(IsoData)条件下,蒸馏预训练依然提升了模型在标准语言建模任务上的表现,表明其价值超越了单纯数据增加的范畴。
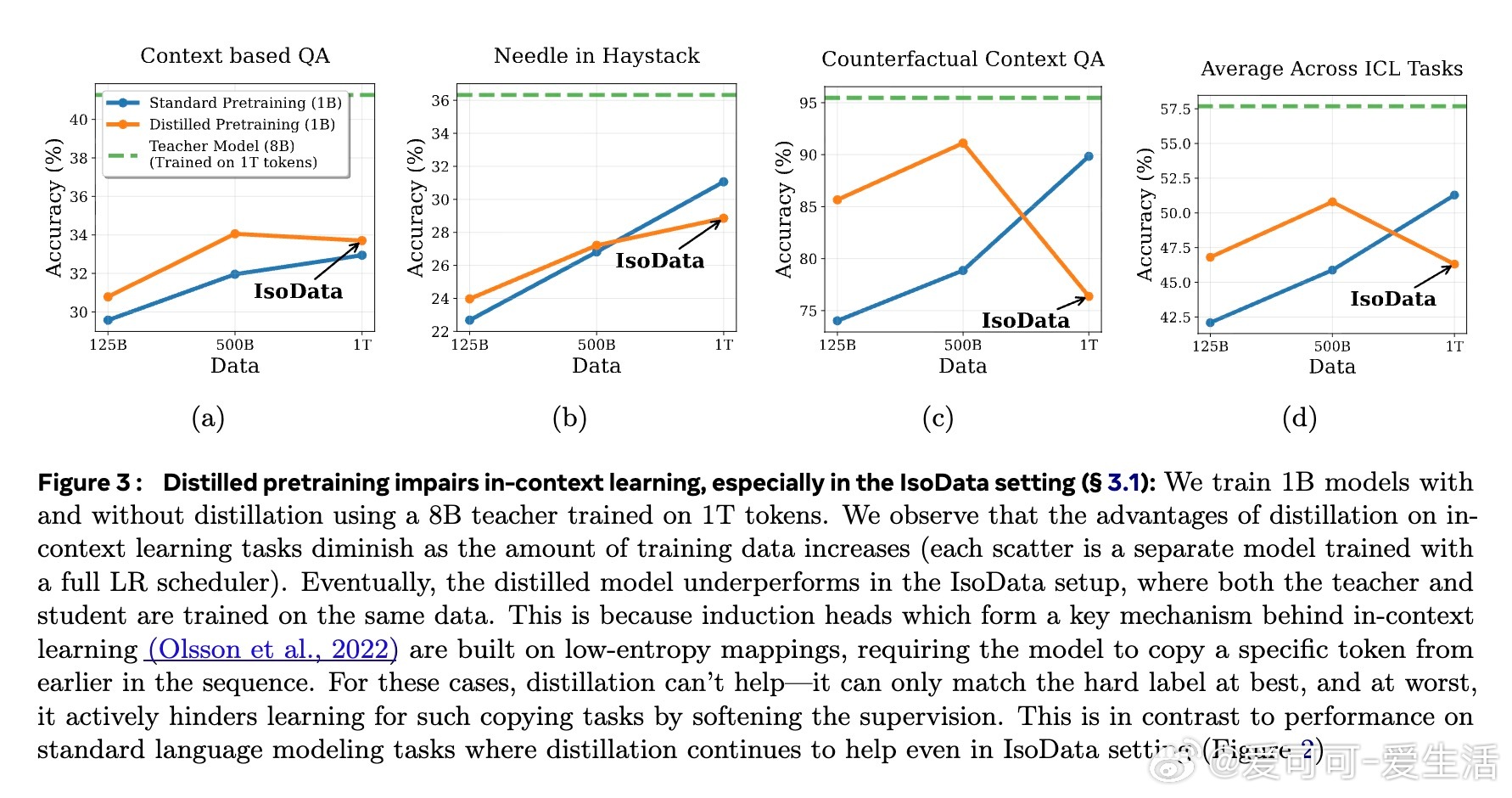
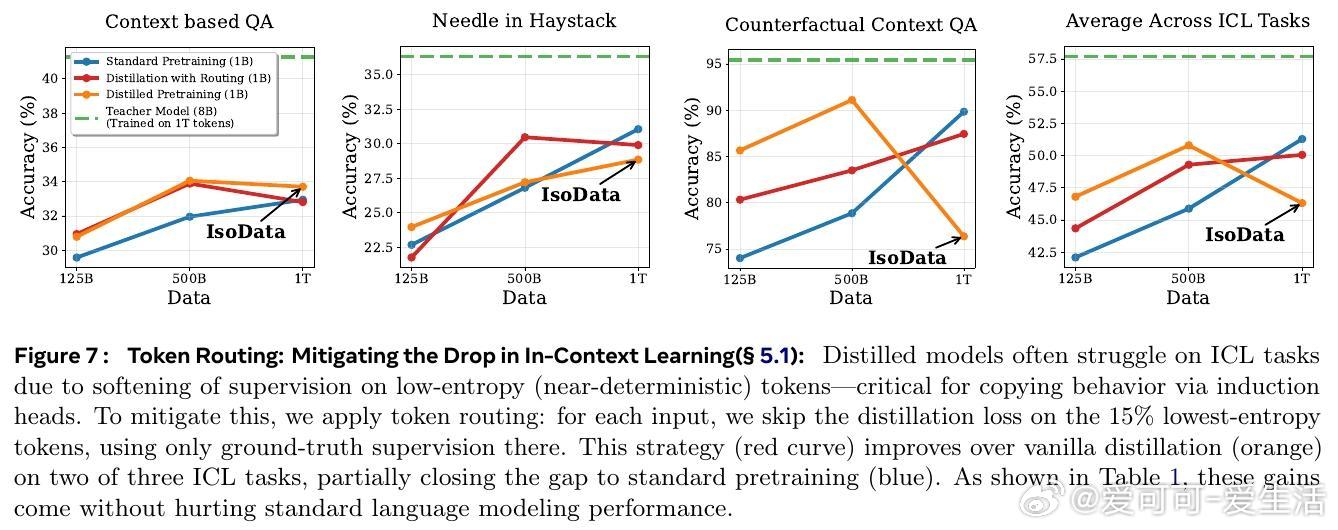
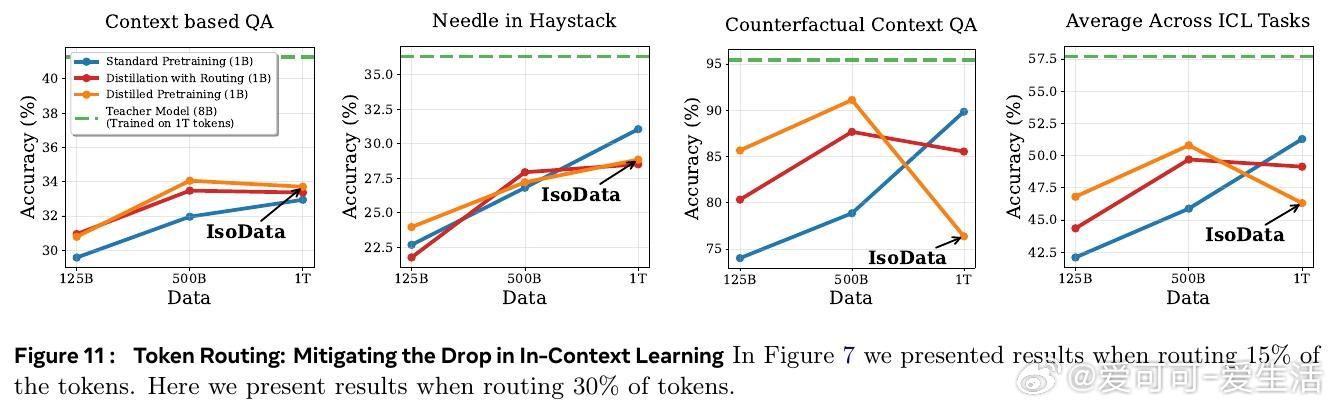
• 蒸馏过程削弱了模型的上下文学习能力,尤其是基于“induction heads”的复制机制,原因在于软标签对低熵(确定性)映射的监督削弱,影响了模型对上下文中特定token的精确复制。
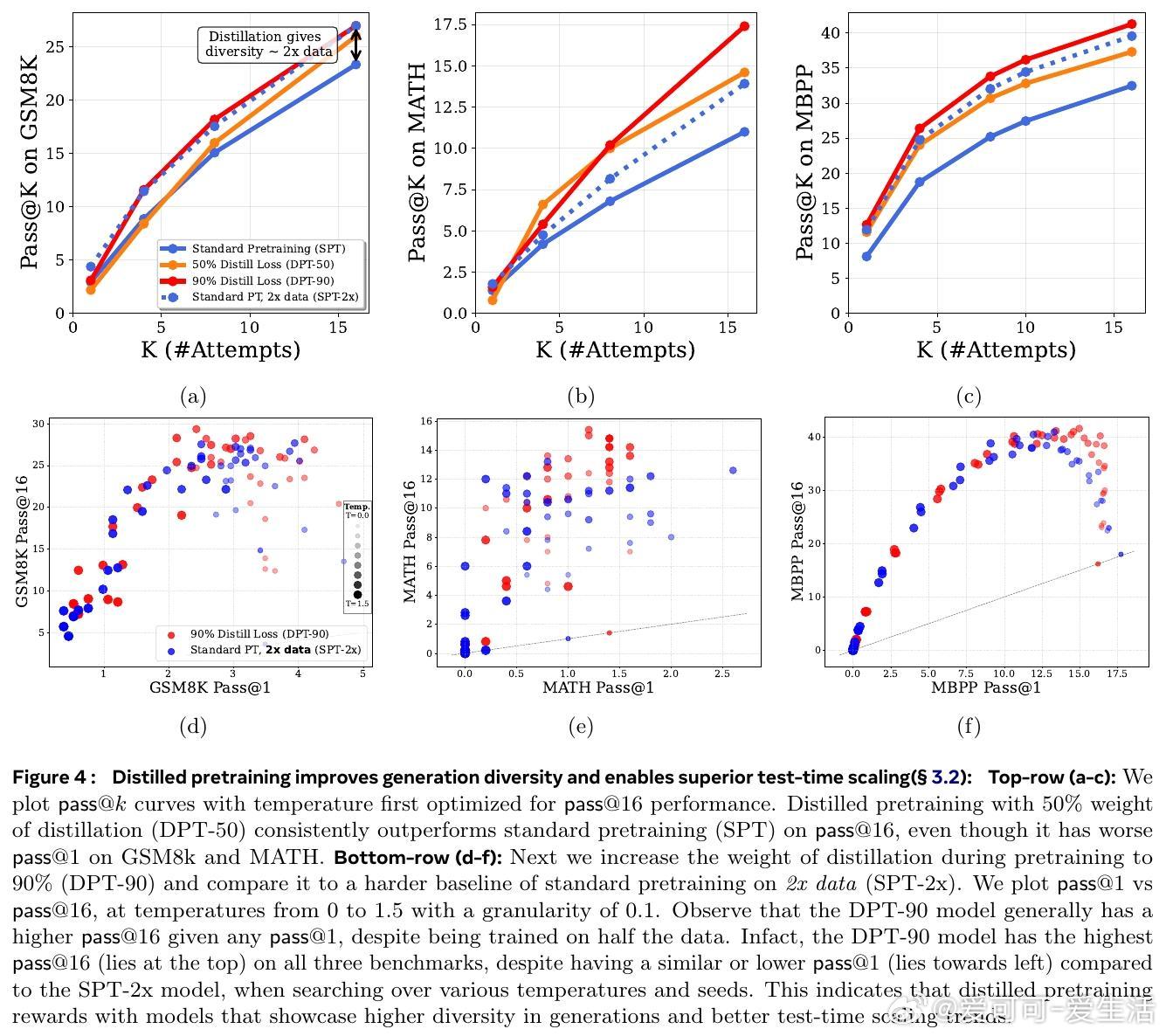
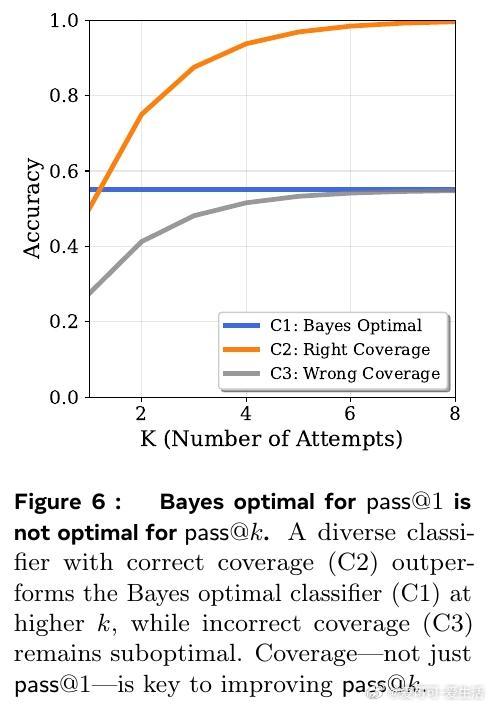
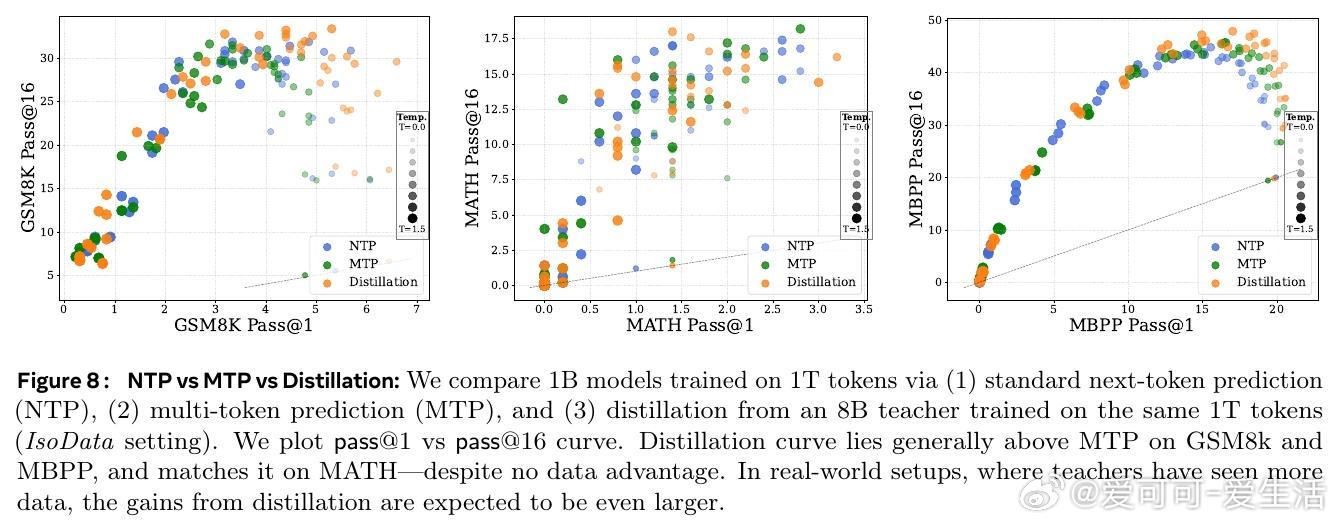
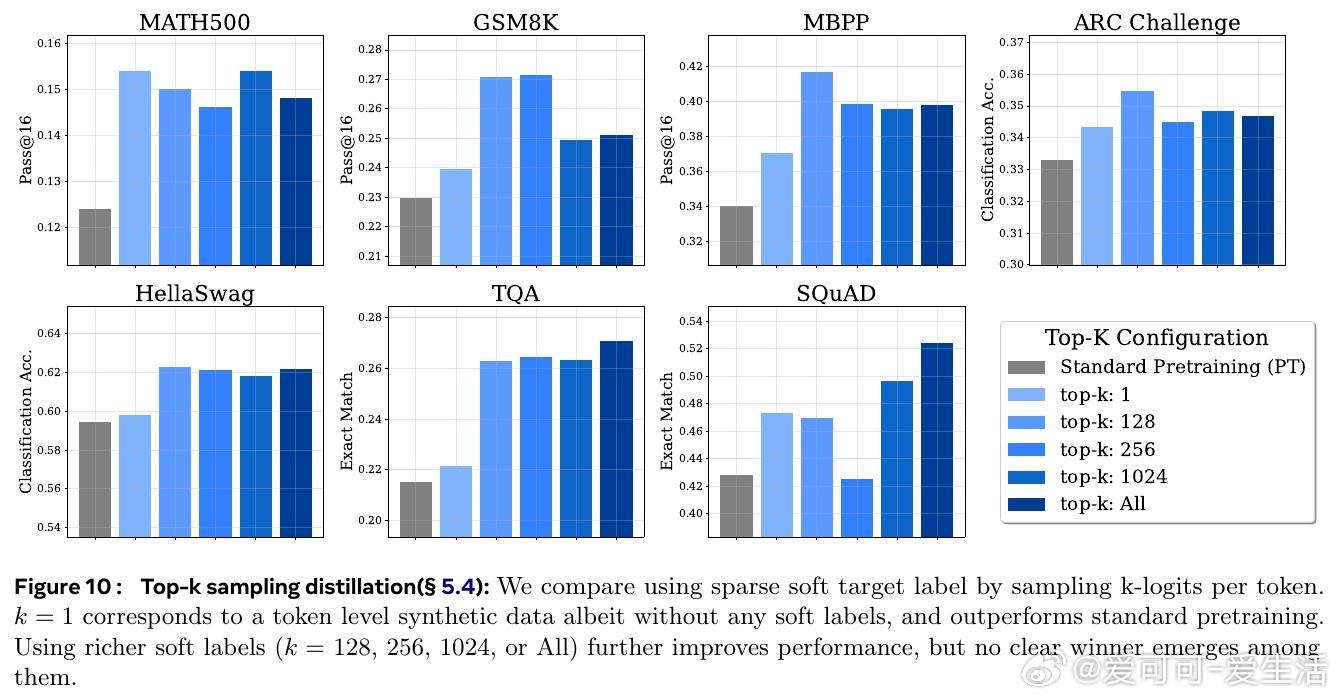
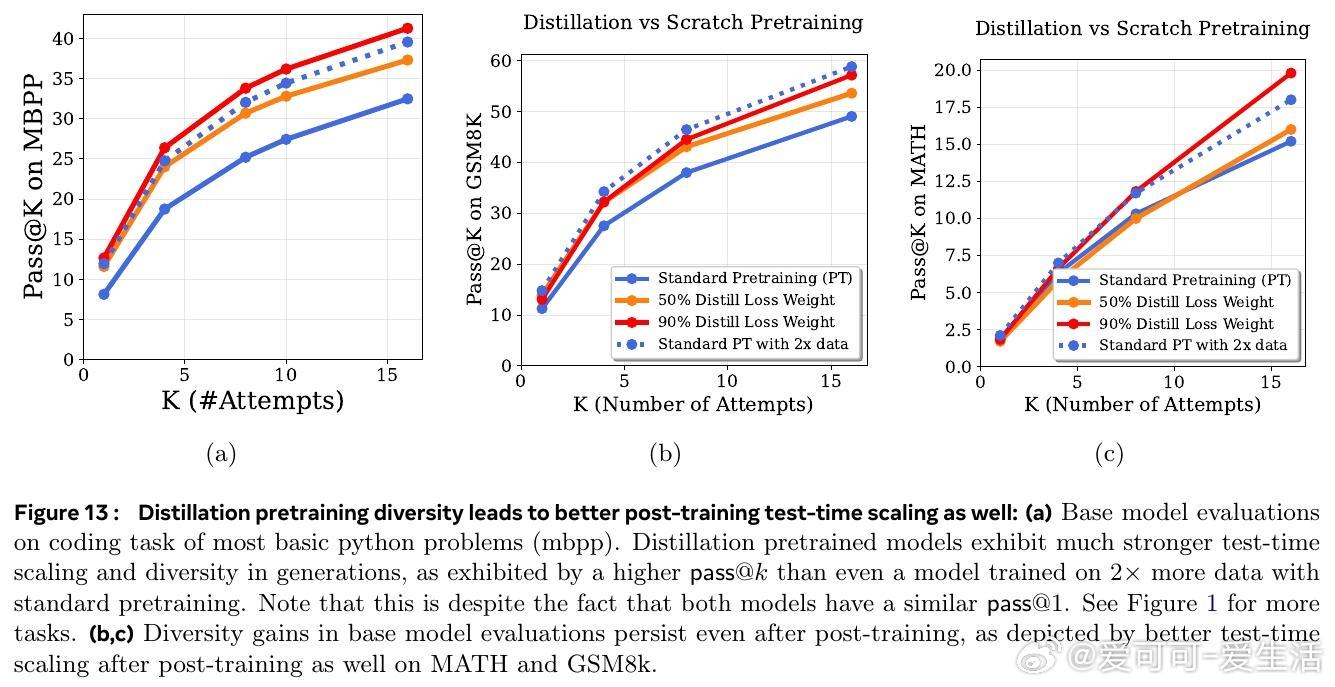
• 与此相反,蒸馏大幅提高了模型生成的多样性,极大增强了测试时多尝试(Pass• 基于大ram模型的分析表明,蒸馏加速了高熵(多样性大)的token分布学习,但对低熵(确定性)模式无明显帮助,且可能因教师模型的不完美引入噪声,降低低熵模式学习效率。
• 实践中通过“Token Routing”策略,针对低熵token跳过蒸馏损失,能部分缓解上下文学习性能下降,且不会损害标准任务表现。
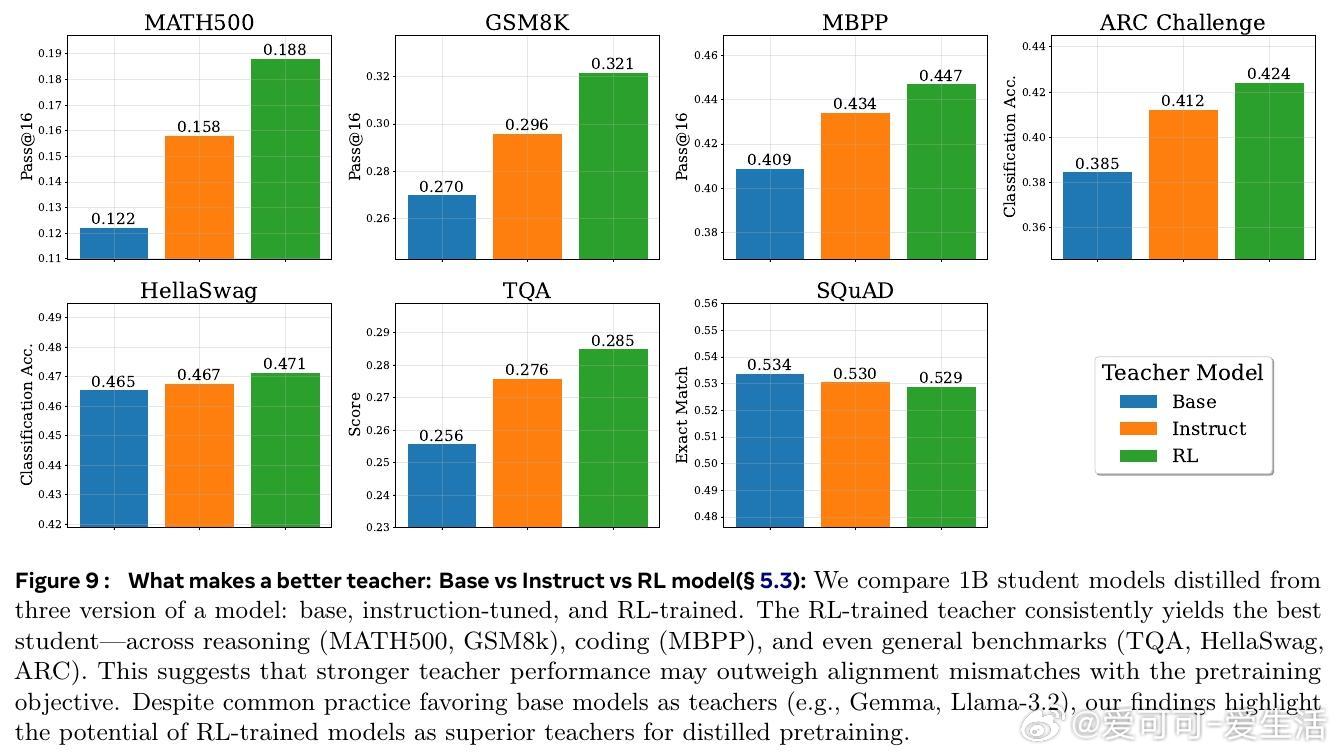
• 不同教师模型对蒸馏效果影响显著:强化学习(RL)训练的教师模型比基础模型更有利于提升学生模型能力,尤其在推理、编程及通用语言任务中表现更优。
• 蒸馏预训练在提升基础模型多样性和测试时扩展性方面的优势,可持续至后续的推理数据后训练阶段,彰显其作为基础改进的价值。
心得:
1. 蒸馏不仅是数据增量的替代,更通过软标签丰富了模型对多样答案空间的理解,促进了生成多样性,这对推理和搜索任务尤为关键。
2. 上下文学习与测试时扩展能力之间存在根本冲突——提升生成多样性往往以牺牲复制精度为代价,设计预训练策略需权衡此点。
3. 针对不同token采用差异化蒸馏监督(如Token Routing)是缓解性能冲突的有效路径,未来的预训练数据集和蒸馏方法应更精细化设计以适配现代LLM需求。
了解更多🔗arxiv.org/abs/2509.01649
大语言模型知识蒸馏预训练上下文学习测试时扩展模型多样性