[CL]《UR²: Unify RAG and Reasoning through Reinforcement Learning》W Li, B Xiang, X Wang, Z Gou... [Tsinghua University & Hebei University of Economics and Business] (2025)
UR²:首个统一检索增强生成与推理的强化学习框架,开启AI动态知识访问新时代
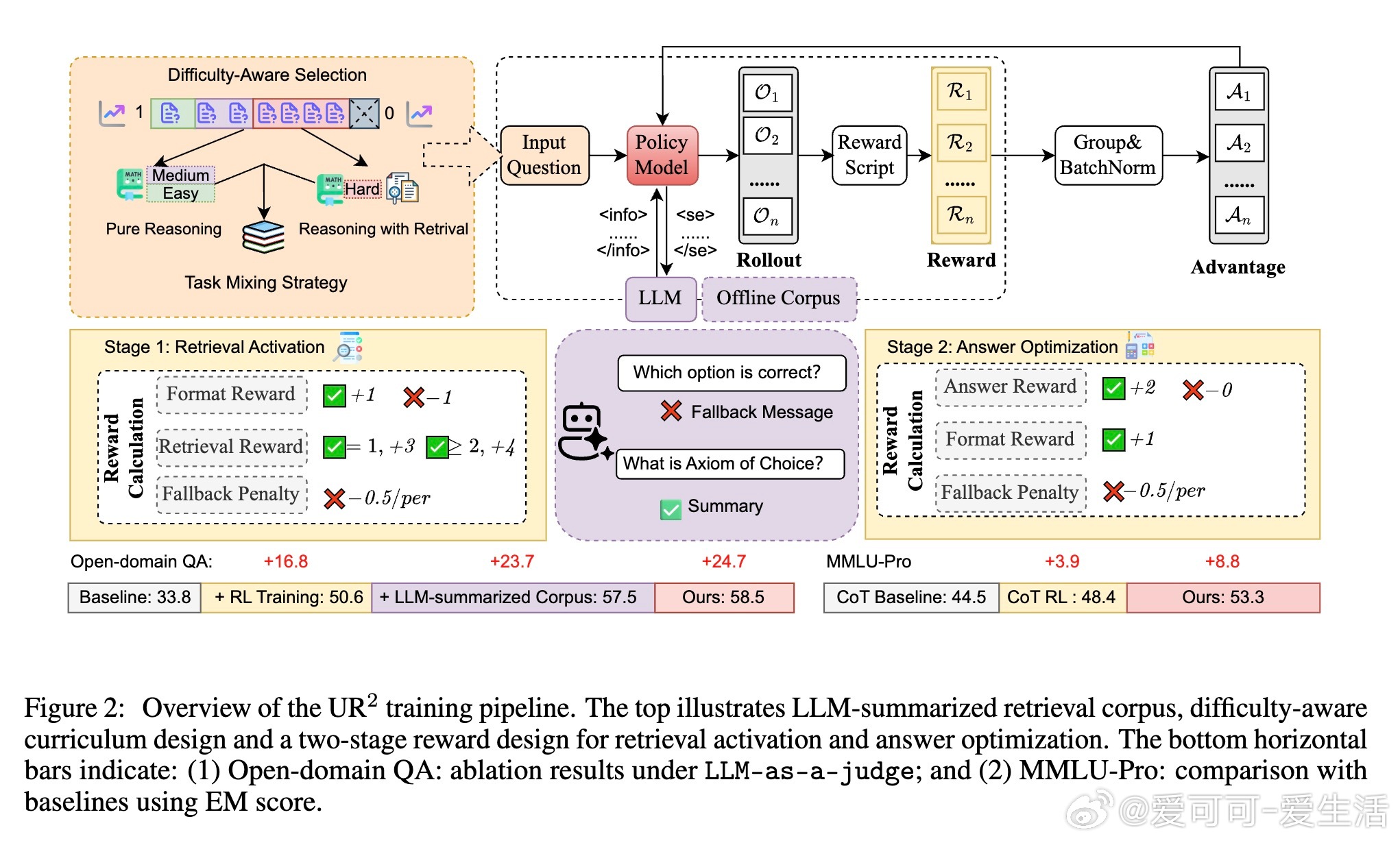
• 结合Retrieval-Augmented Generation (RAG)与Reinforcement Learning from Verifiable Rewards (RLVR),突破传统孤立开发瓶颈,实现检索与推理的动态协调。
• 创新难度感知课程训练,仅对难题触发检索,节省计算资源同时提升查询质量。
• 混合知识访问策略:融合领域专属离线语料与LLM自动生成摘要,兼顾准确性与泛化能力,支持多领域数学、医学、开放域问答等复杂任务。
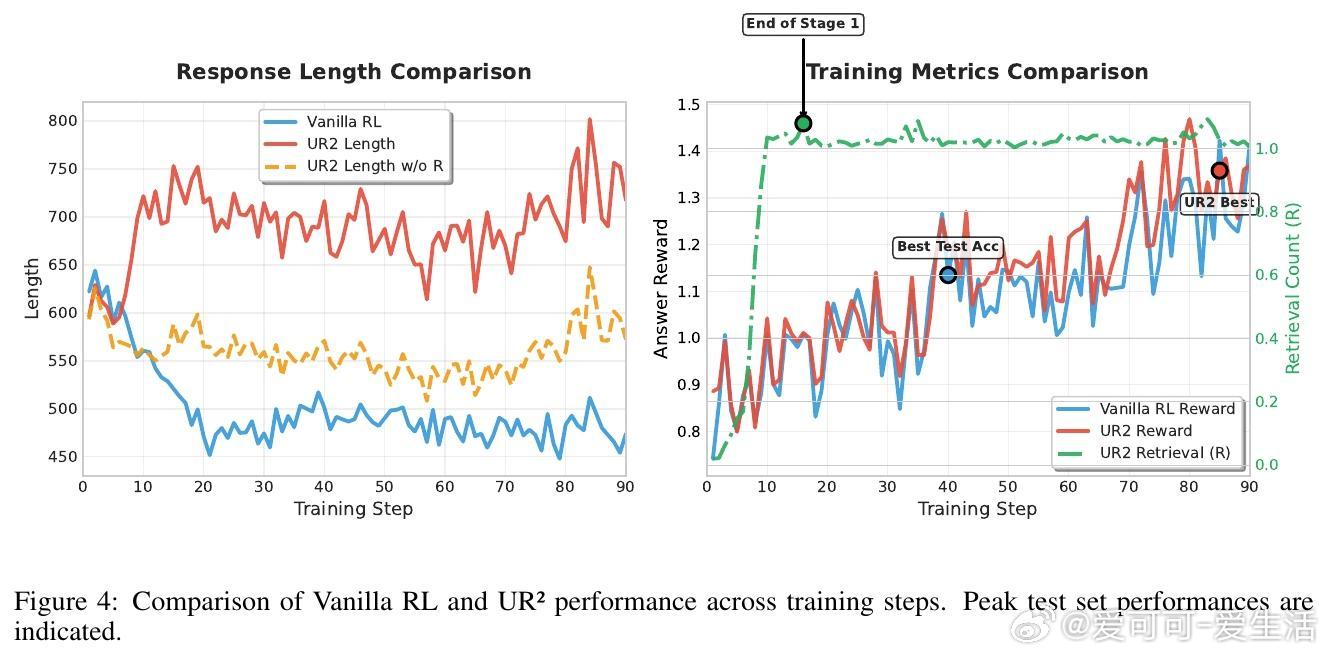
• 两阶段优化:先激活检索能力,再优化答案质量,避免过拟合检索内容,训练更稳健。
• 多任务综合训练与评测,UR2在Qwen和LLaMA模型上表现优异,超越先进RAG和RL方法,7B参数模型接近GPT-4o-mini水平,泛化能力强,兼顾推理深度与知识时效。
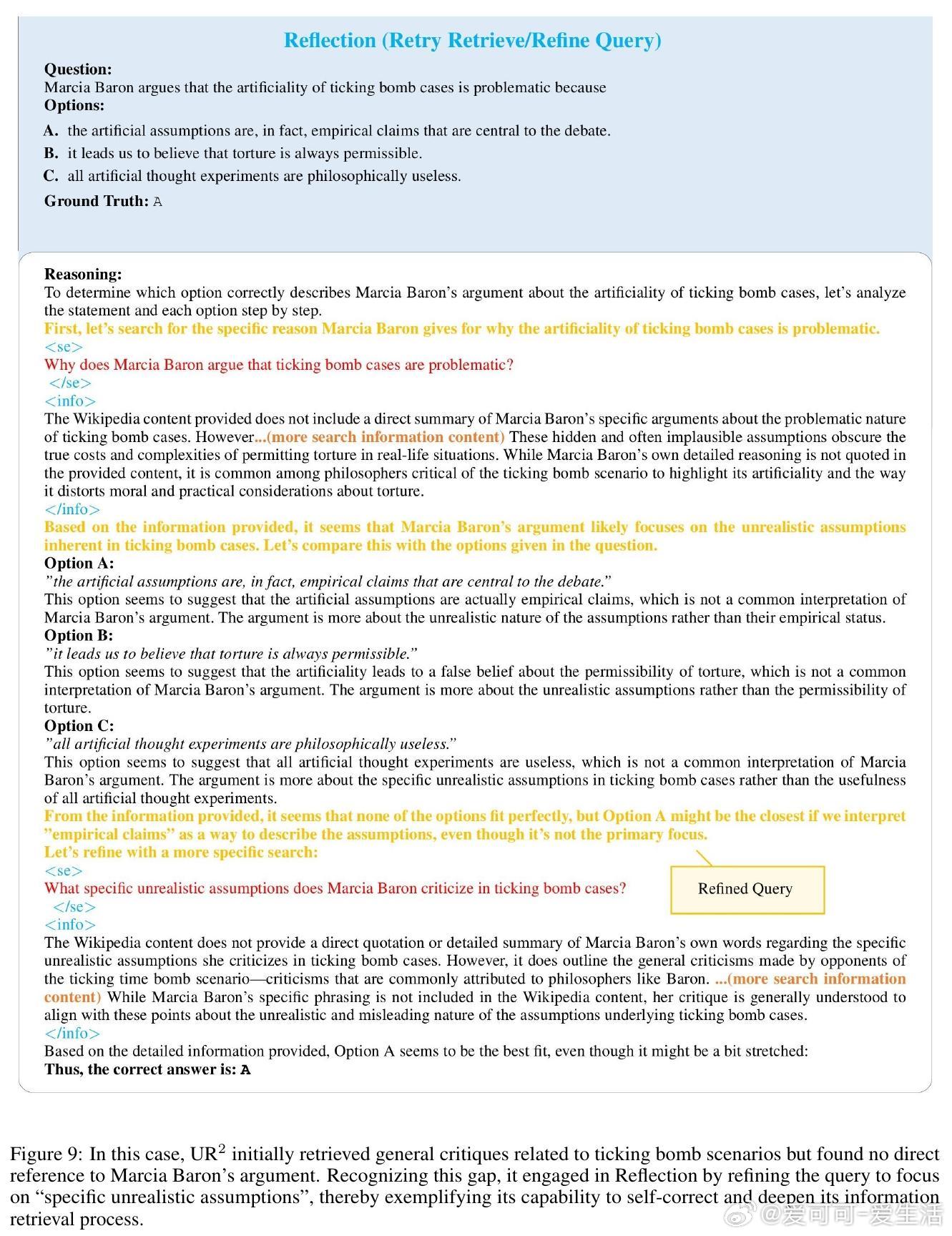
• 精细设计检索格式与奖励机制,避免无效查询与幻觉,展现自我验证、跨角度校验、多次反思重检等多样认知行为。
• 代码与模型已开源,推动AI系统更智能地结合内置知识与动态外部信息,突破静态知识库限制。
了解更多👉 arxiv.org/abs/2508.06165
GitHub👉 github.com/Tsinghua-dhy/UR2
人工智能强化学习大语言模型知识检索机器推理自然语言处理