[LG]《AgentFly: Fine-tuning LLM Agents without Fine-tuning LLMs》H Zhou, Y Chen, S Guo, X Yan... [UCL & Huawei Noah’s Ark Lab & Jilin University] (2025)
AgentFly创新性地提出了一种无需微调底层LLM参数的适应性学习范式,通过记忆驱动的在线强化学习实现持续进化。
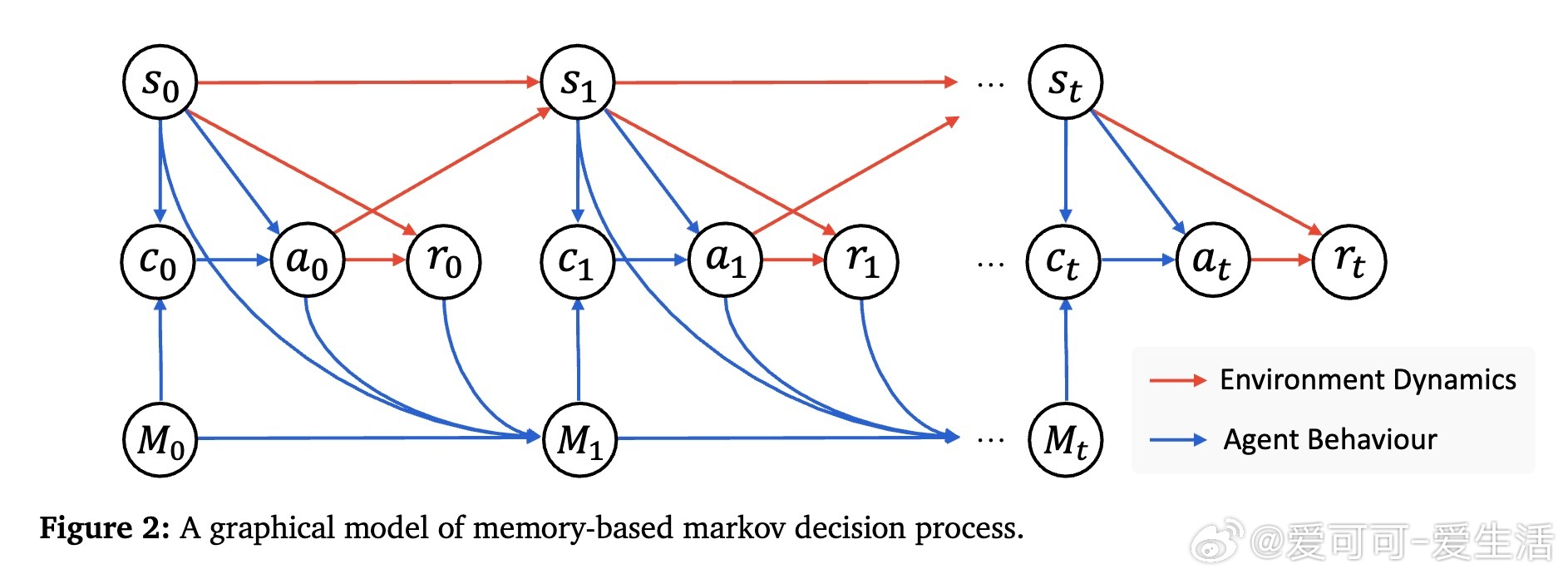
• 采用记忆增强马尔可夫决策过程(M-MDP)模型,结合神经案例选择策略,高效检索与当前任务相似的历史经验,指导行动决策。
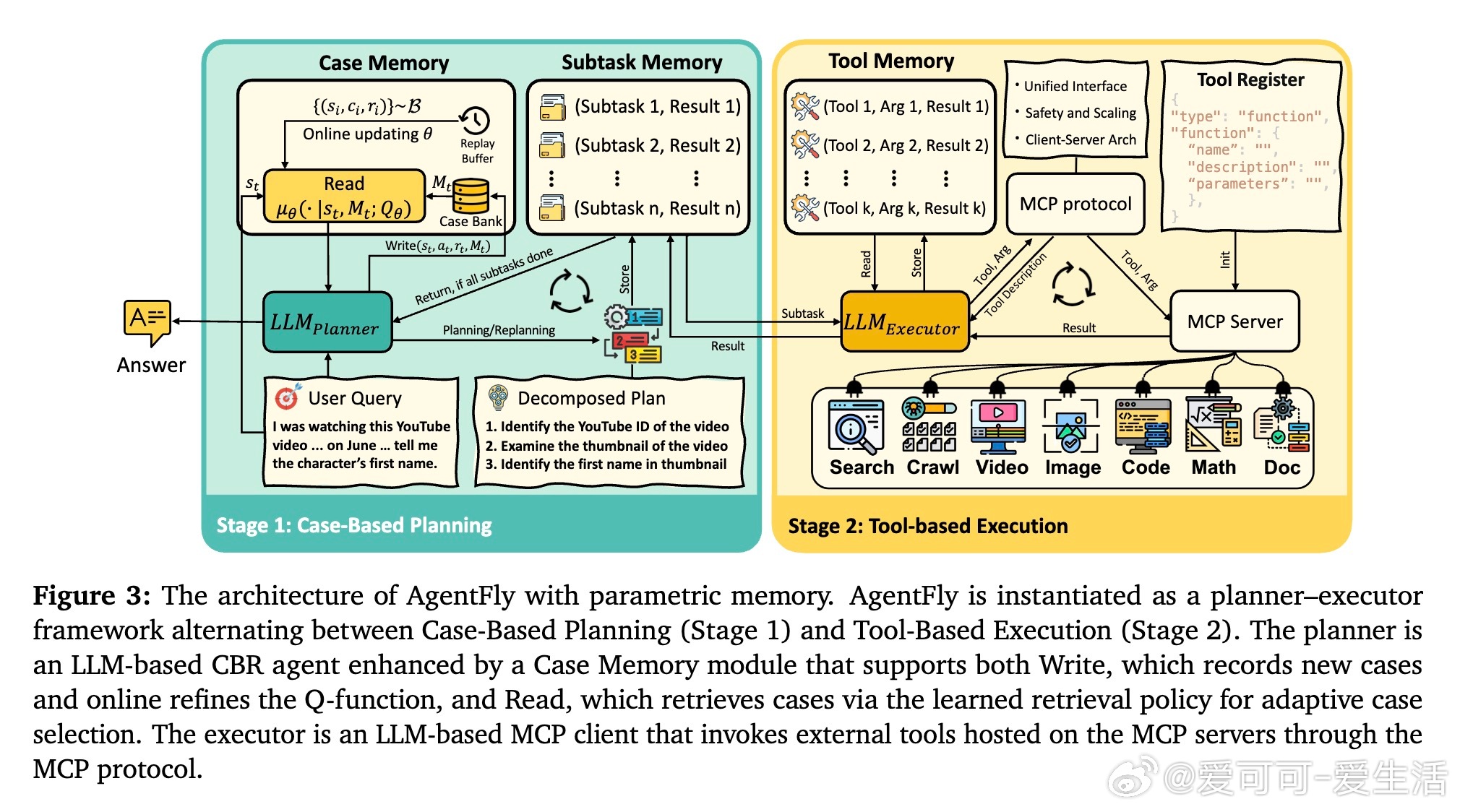
• 案例库以情景记忆形式存储成功与失败轨迹,支持非参数和参数化两种记忆管理方式,后者通过在线更新Q函数实现自适应案例筛选。
• 设计了规划者-执行者架构,规划者基于GPT-4.1执行案例推理,执行者通过MCP协议灵活调用搜索、爬虫、多模态处理、代码执行等工具,满足复杂长程推理需求。
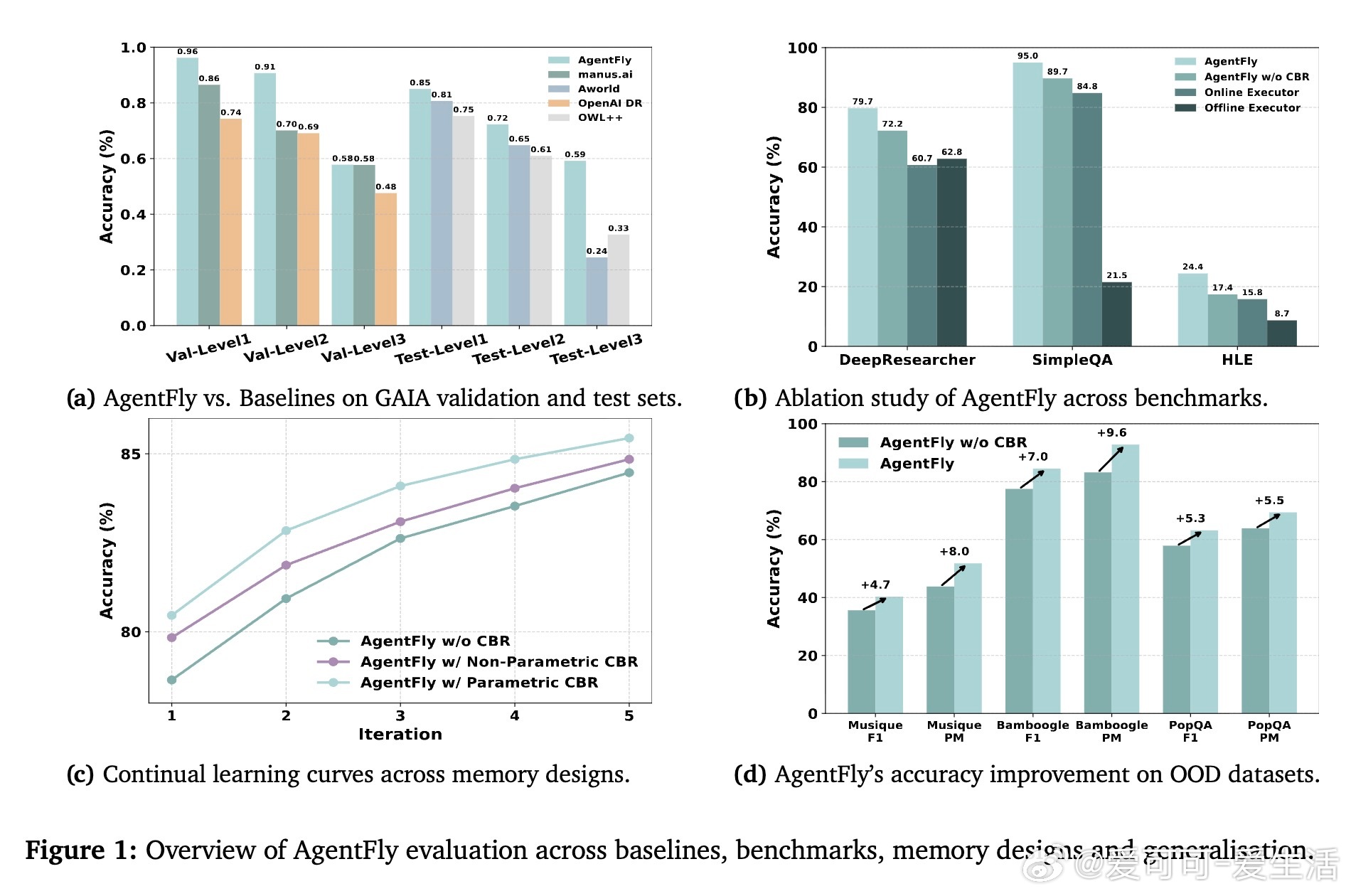
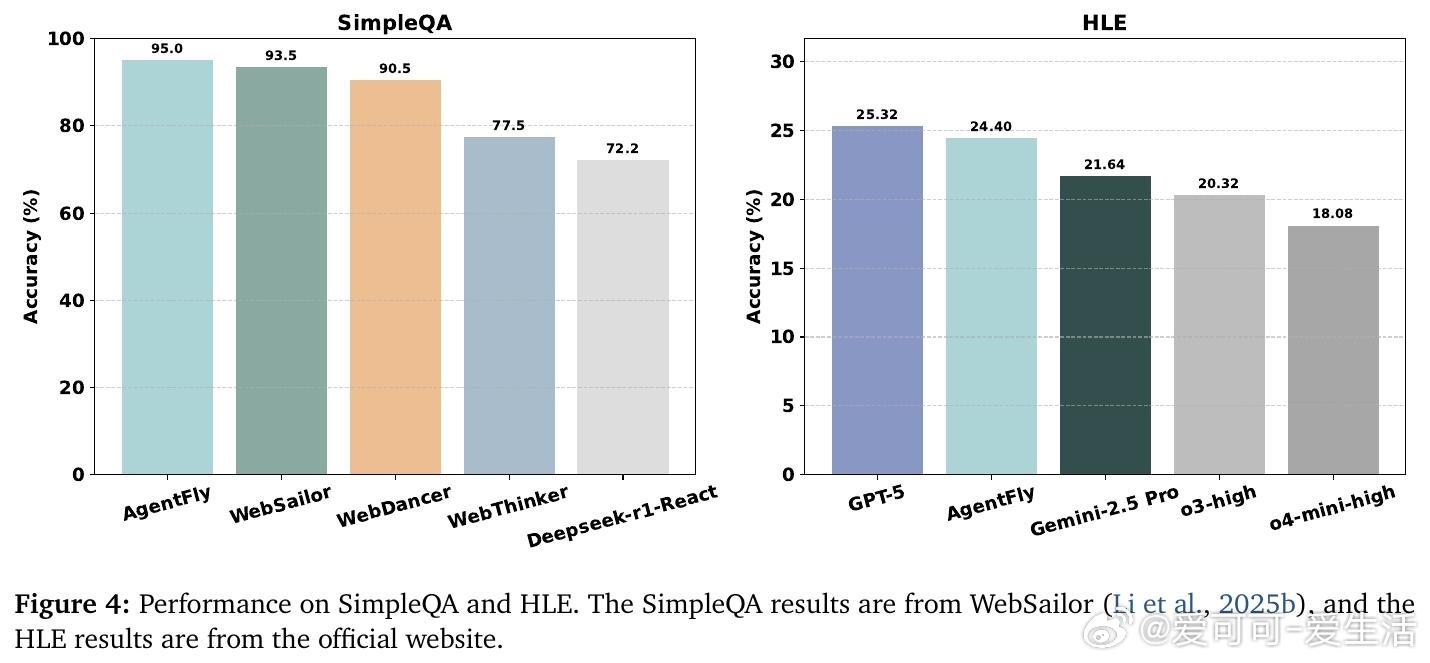
• 在GAIA长程规划、DeepResearcher实时网络研究、SimpleQA事实问答及HLE学科前沿等四大基准测试中均取得领先成绩,特别是在GAIA验证集上达87.88%准确率,测试集79.40%,显著优于现有训练型方法。
• 消融实验显示,适度规模的高质量记忆案例(K=4)最优,案例推理显著增强泛化能力,对未见任务提升4.7%-9.6%绝对分数。
• 通过软Q学习与状态相似度核方法,AgentFly高效学习检索策略,避免了昂贵的模型微调,体现了类人记忆和类比推理的学习机制。
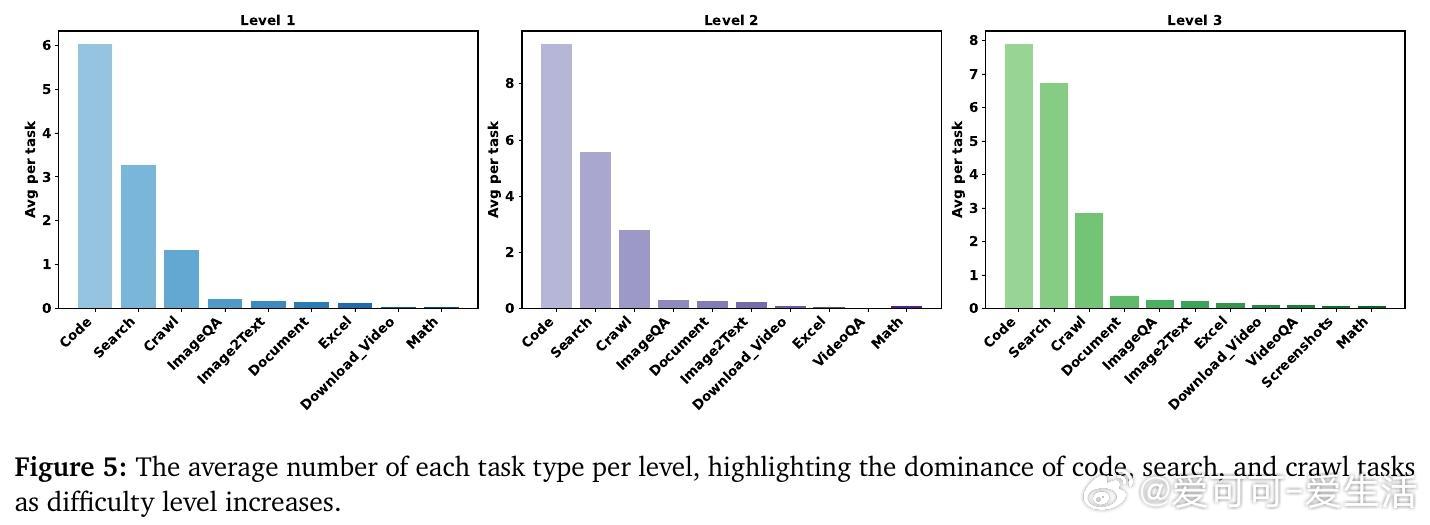
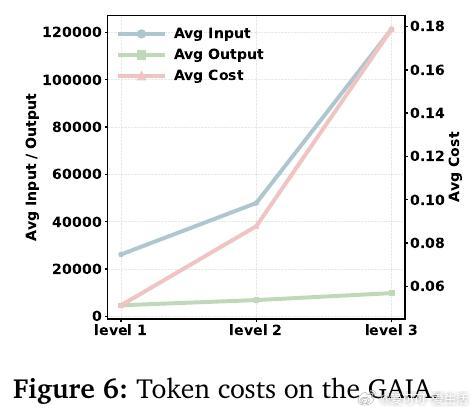
• 详细工具统计揭示,随着任务难度提升,代码调用、搜索和爬虫工具使用量显著增加,但模型内部推理在最高难度任务中扮演关键整合角色。
• 快速规划模式(GPT-4.1)相比冗长深思模式,在复杂任务中表现更优,强调了模块化系统中简洁、高效规划的重要性。
AgentFly为构建无需参数更新、可持续在线学习的通用LLM代理提供了新范式,推动机器学习向开放式技能习得与深度科研自动化迈进。
了解详情🔗 arxiv.org/abs/2508.16153
代码开源🔗 github.com/Agent-on-the-Fly/AgentFly
大语言模型案例推理强化学习持续学习自动化研究人工智能