[LG]《Evolving Language Models without Labels: Majority Drives Selection, Novelty Promotes Variation》Y Zhou, Z Liang, H Liu, W Yu... [Tencent AI Lab] (2025)
大语言模型(LLMs)无标签自我进化的关键突破:EVOL-RL
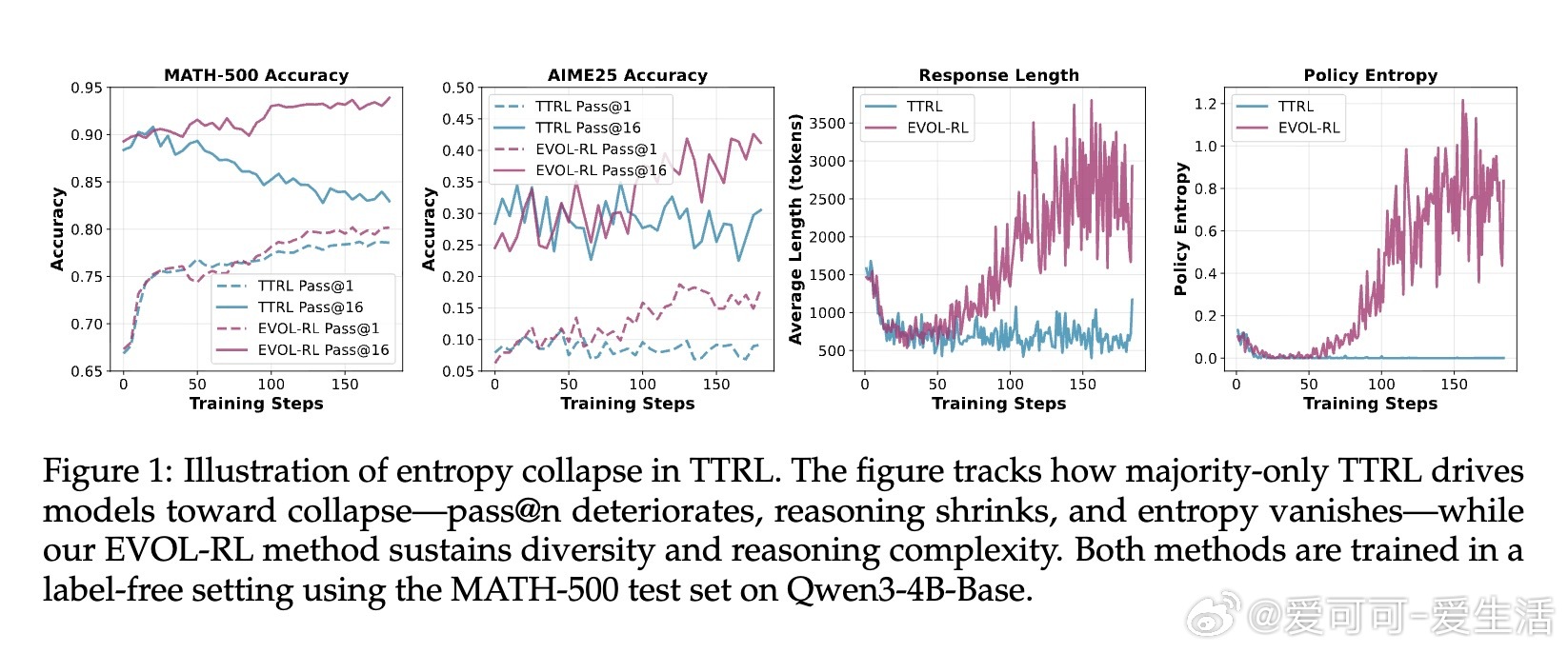
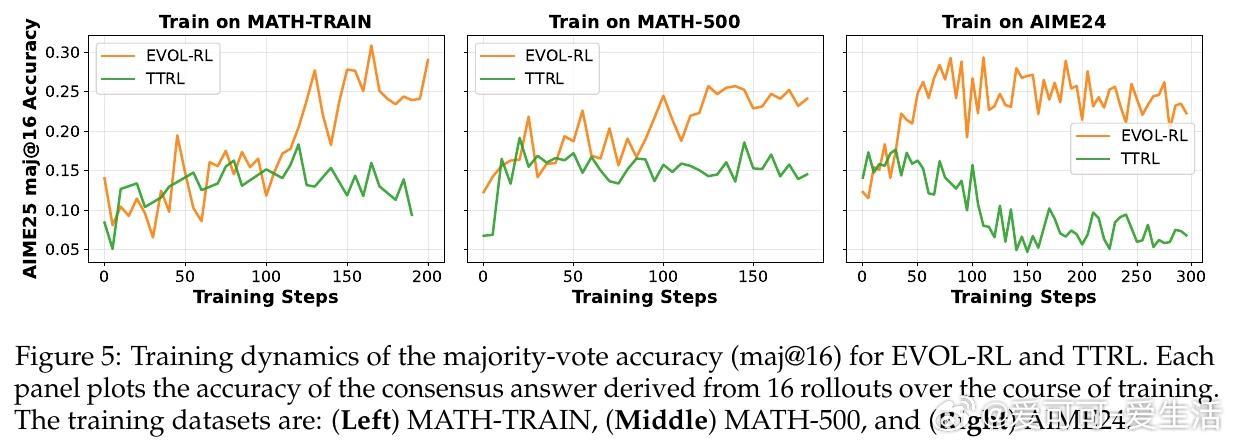
• 传统无标签自我训练依赖多数投票(majority vote)稳定学习,但导致探索能力下降,出现“熵崩溃”——生成答案趋同、简短且脆弱。
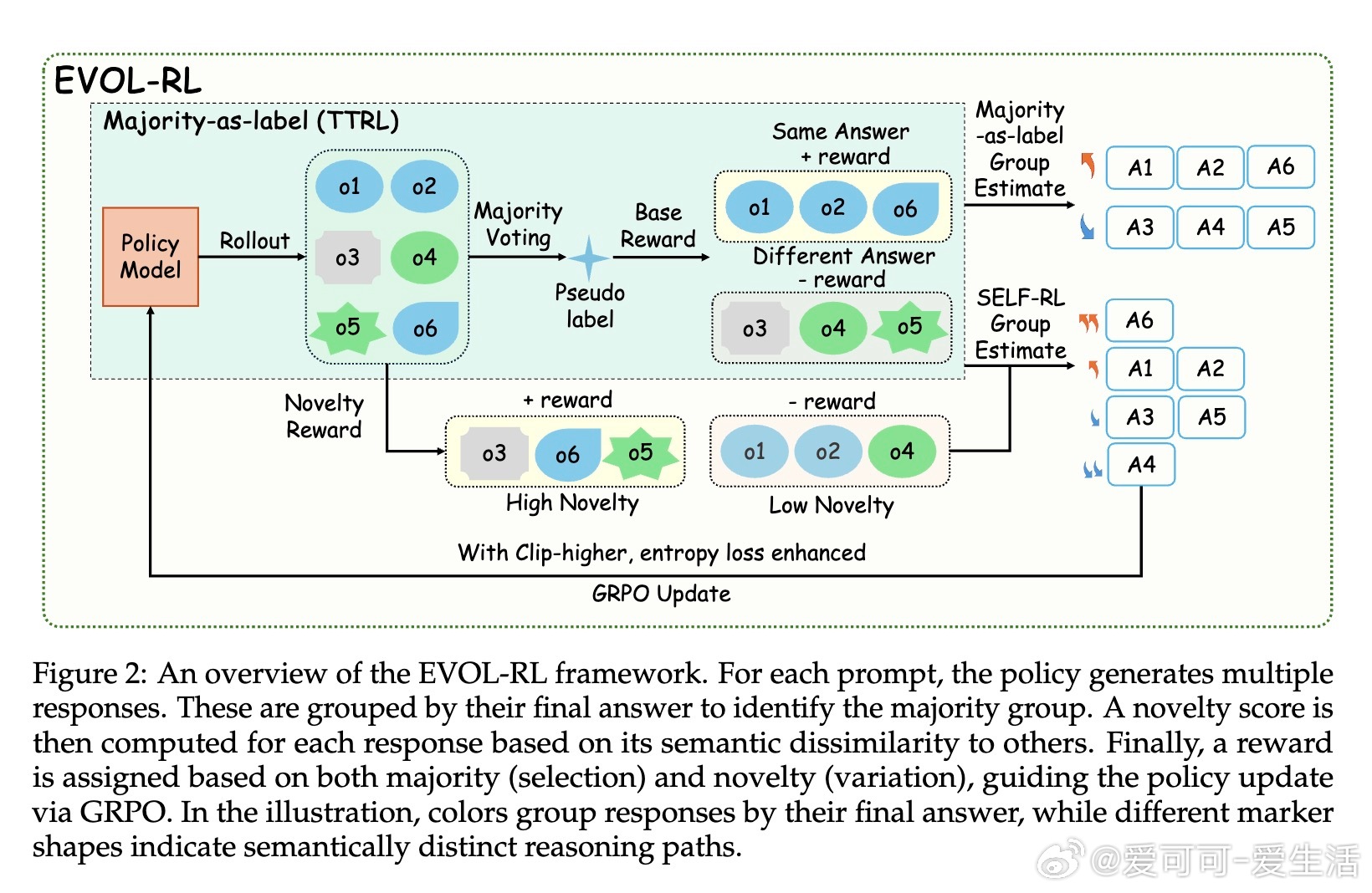
• EVOL-RL结合“多数投票选优+语义新颖度奖励”,在保持稳定锚点的同时激励变异,防止模型陷入单一解空间,持续激发多样化推理路径。
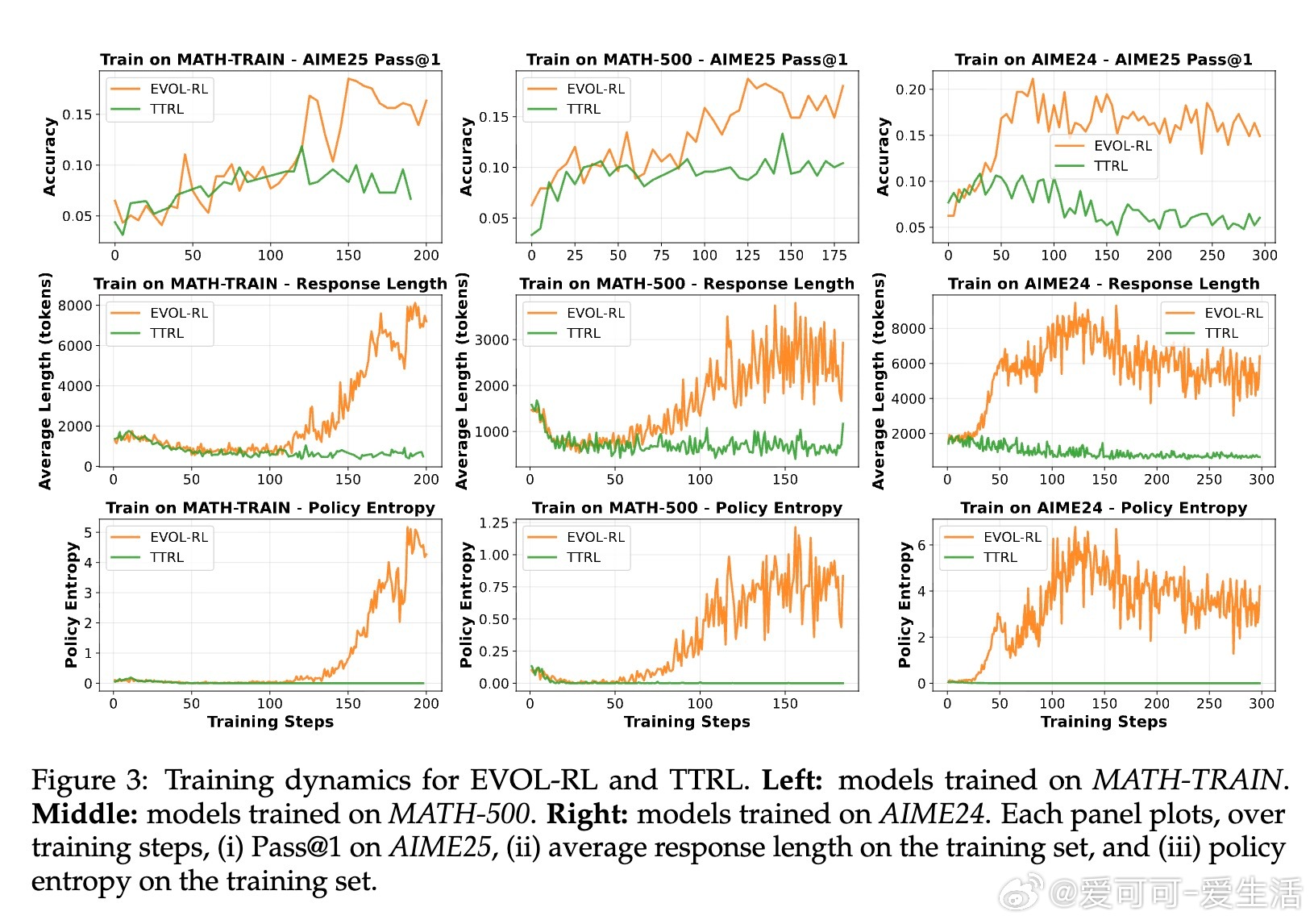
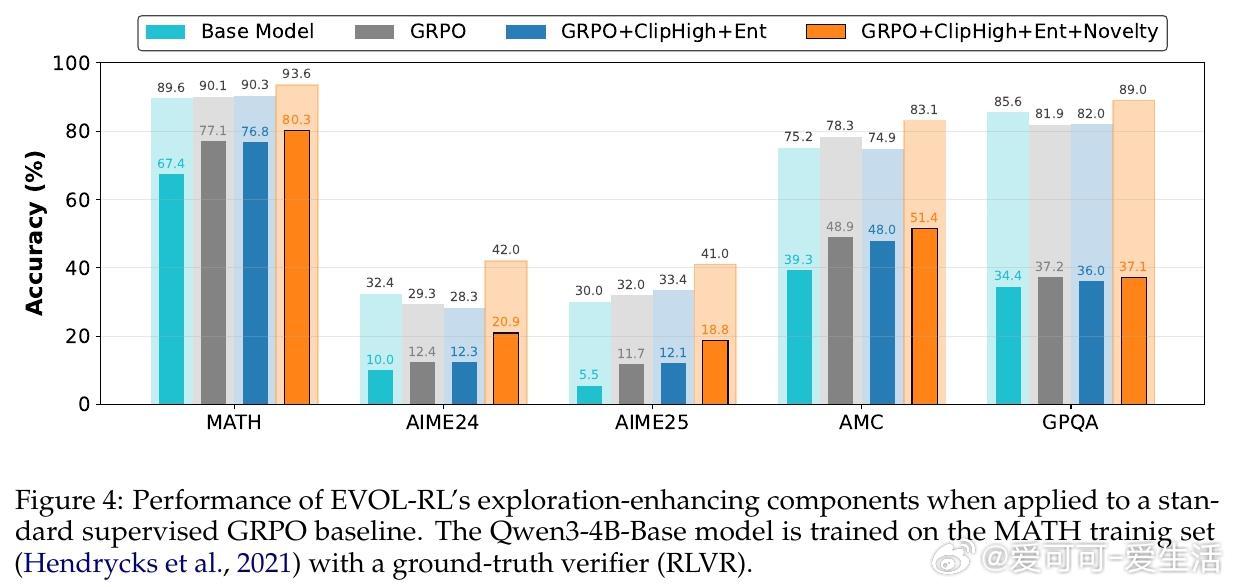
• 采用GRPO算法,配合不对称策略剪辑和熵正则化,保障强信号保留与搜索多样性,显著延长推理链条,提高pass• 大幅提升数学推理基准(AIME25等)表现:Qwen3-4B基线模型pass• EVOL-RL不仅适用于无标签环境,同样强化有标签RL训练效果,展现极强通用性和稳定性。
心得:
1. 单一多数信号虽稳但终陷局,保持多样性和探索是模型持续进化的核心。
2. 语义层面测量新颖度比单纯答案差异更有效,促进多元推理风格共存。
3. 训练策略需兼顾强信号保留与探索激励,三者协同才能突破传统自训练瓶颈。
详情🔗arxiv.org/abs/2509.15194
大语言模型无标签学习自我进化强化学习机器学习数学推理



![WS-21的模型来了[鼓掌]3711结构,加力改成环形内喷+加大风扇压比,选用](http://image.uczzd.cn/15942295075296308956.jpg?id=0)

