[CL]《Scaling Agents via Continual Pre-training》L Su, Z Zhang, G Li, Z Chen... [Alibaba Group] (2025)
阿里通义实验室最新发布的AgentFounder-30B模型,通过创新的“Agentic Continual Pre-training”(Agentic CPT)方法,实现了深度研究型智能体的显著性能跃升。
• Agentic CPT突破传统后训练瓶颈,构建具备内生agentic偏好的基础模型,缓解能力学习与行为对齐间的优化冲突。
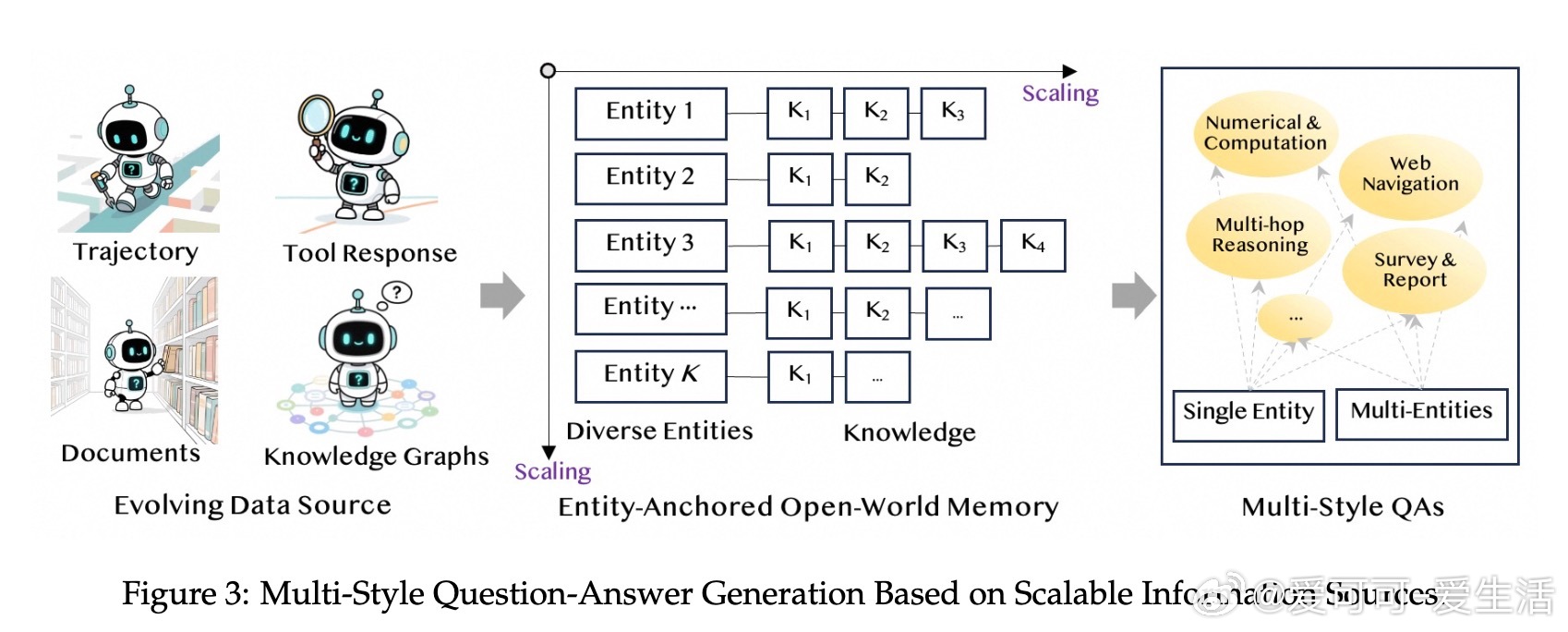
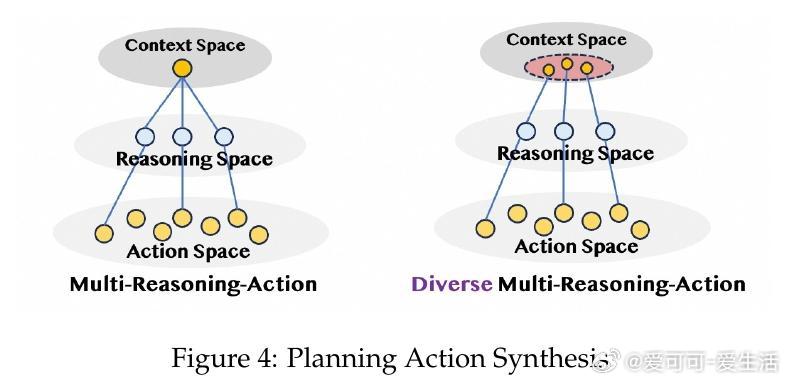
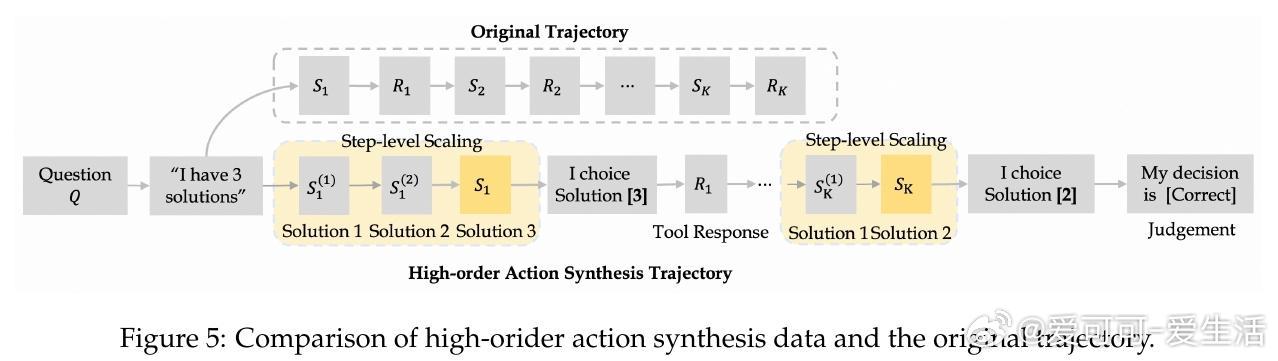
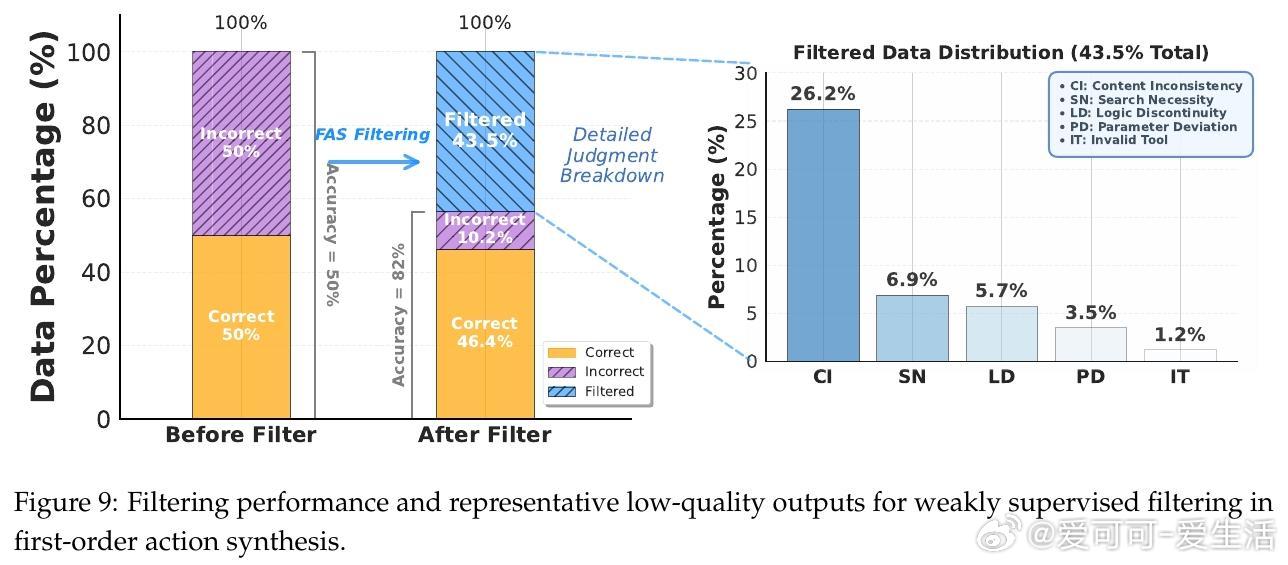
• 数据合成策略涵盖“First-order Action Synthesis”(FAS)和“High-order Action Synthesis”(HAS),无需外部API调用,支持海量多领域多样化动作轨迹生成,提升模型规划与推理能力。
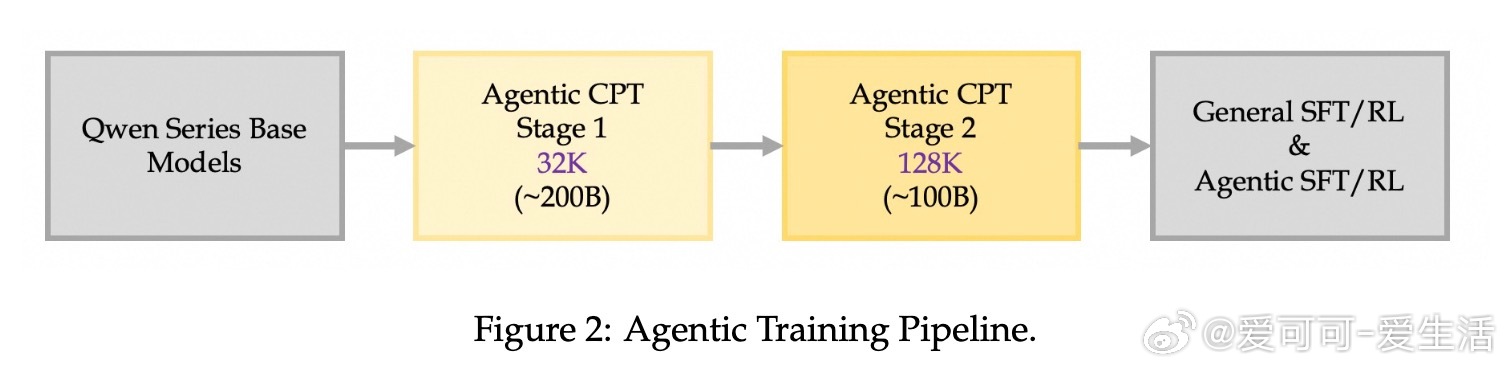
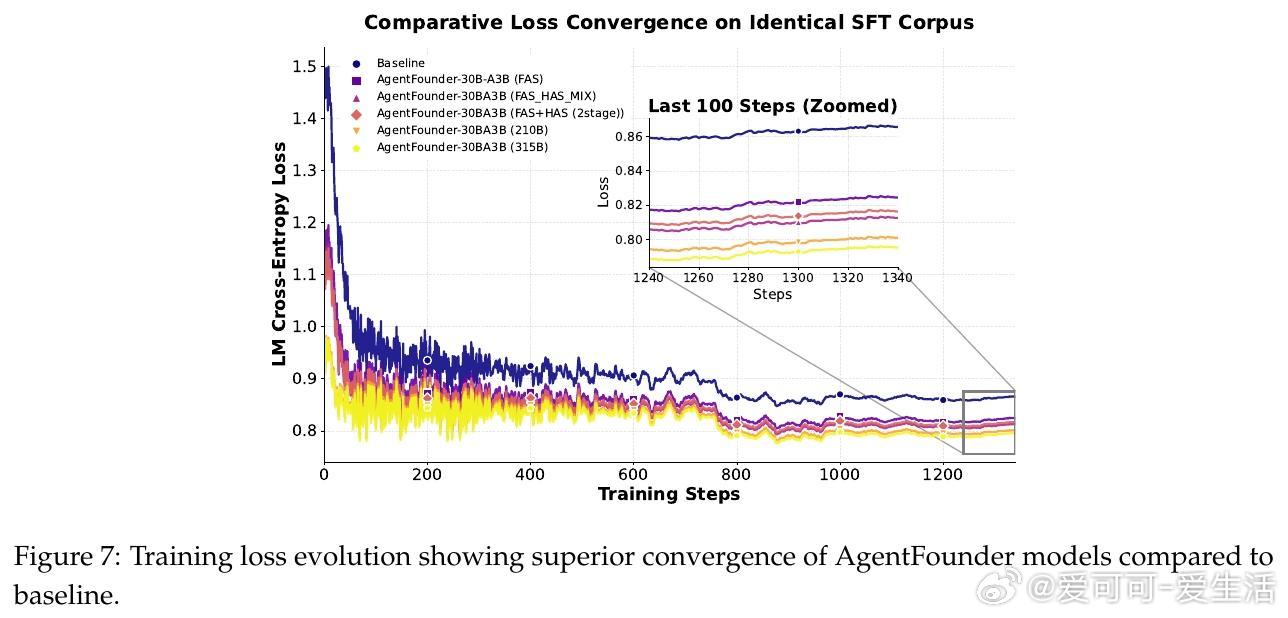
• 采用两阶段训练方案:初期以32K上下文处理广泛agentic数据,后期通过128K长上下文精炼复杂长程决策路径,促进长时推理与多步骤规划。
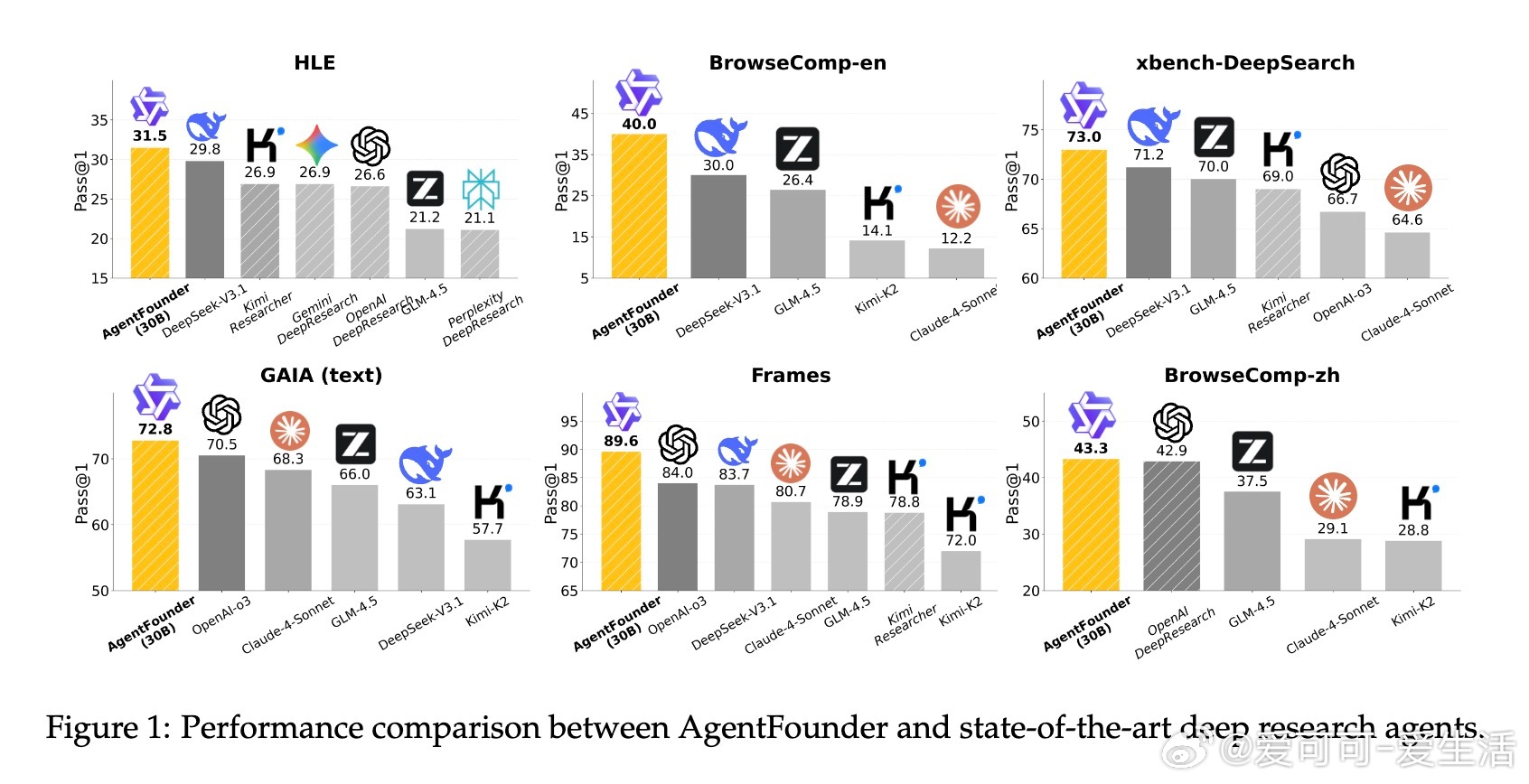
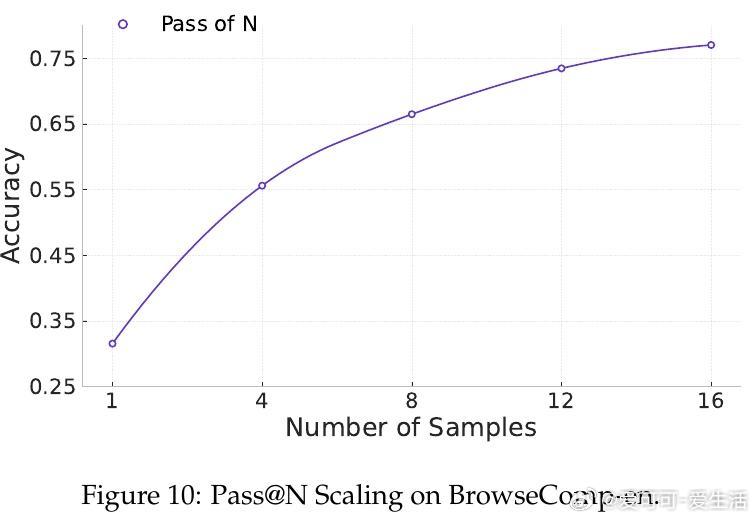
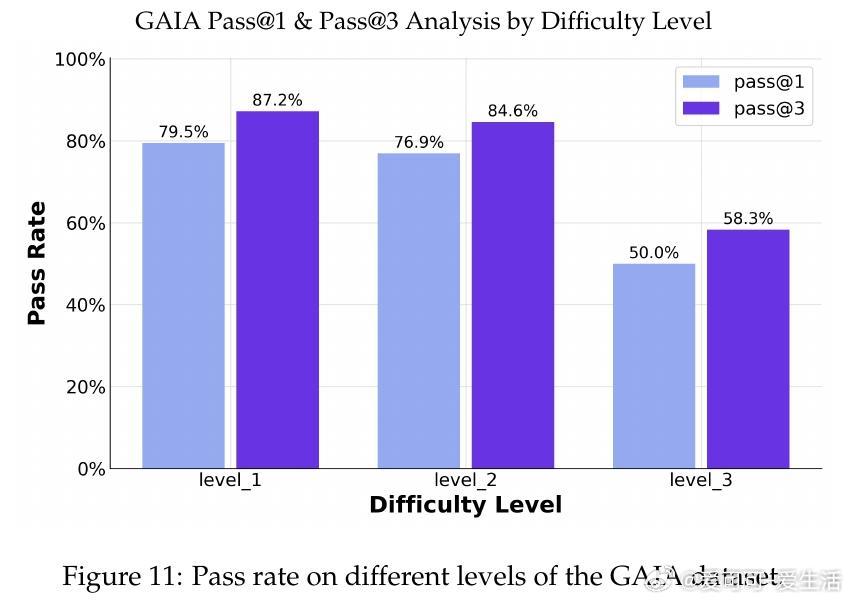
• 在10项公开基准测试中,AgentFounder-30B全面领先开源及多数商用深度研究型智能体,BrowseComp-en达39.9%,HLE突破31.5%门槛,展现卓越的复杂环境适应与工具调用能力。
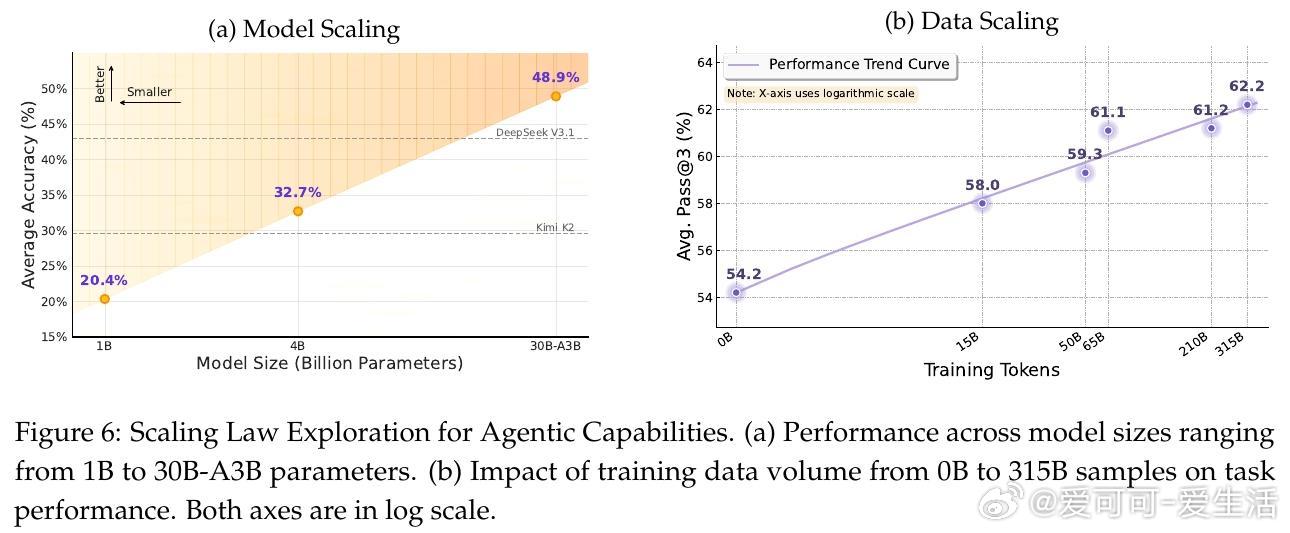
• 模型规模与数据规模均呈现显著的对数级性能提升,30B参数模型优于更大体量竞品,标志着Agentic CPT在高效利用计算资源上具备优势。
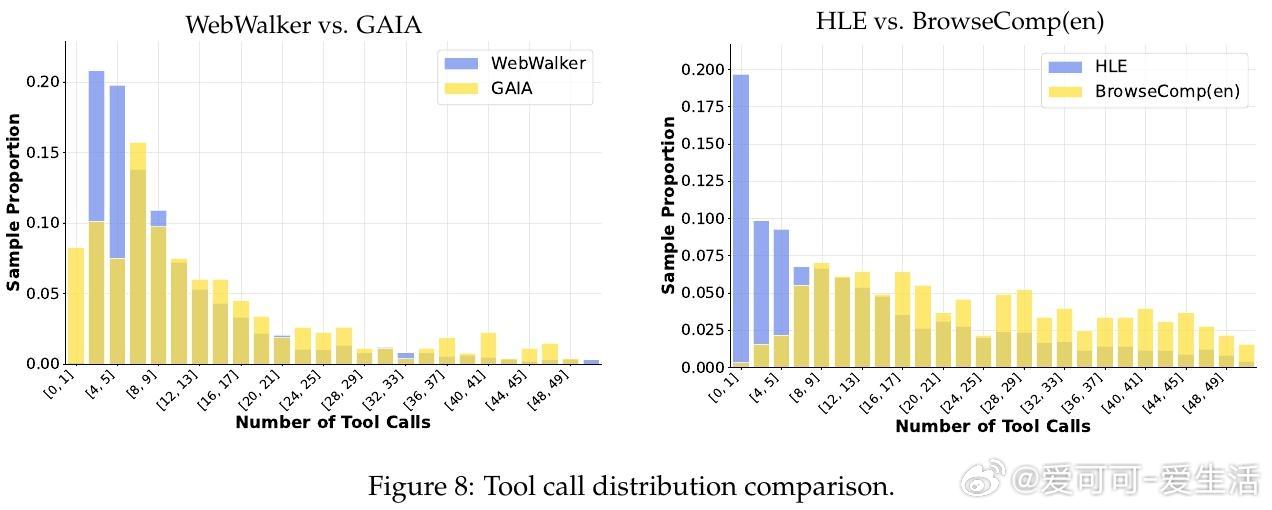
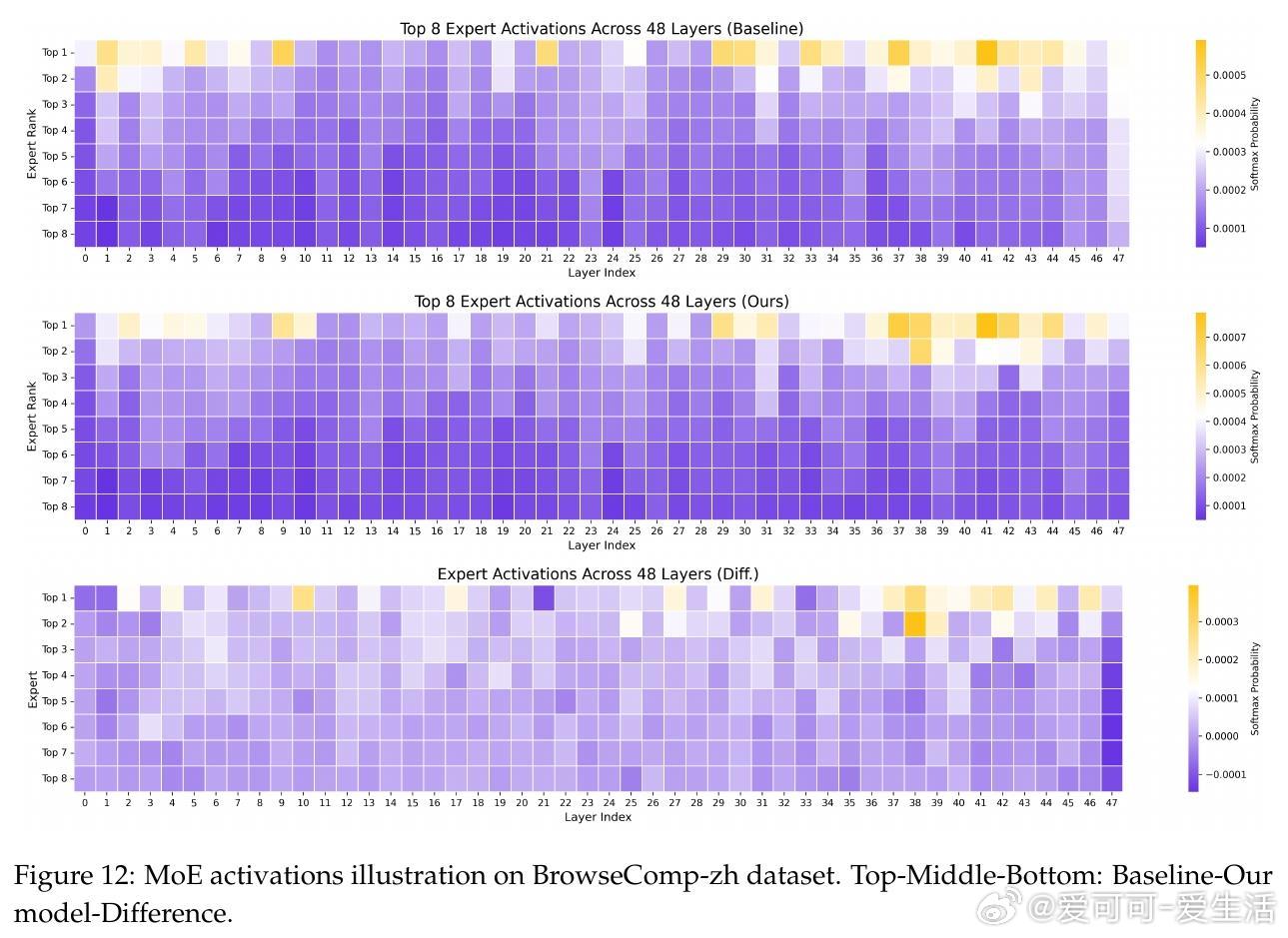
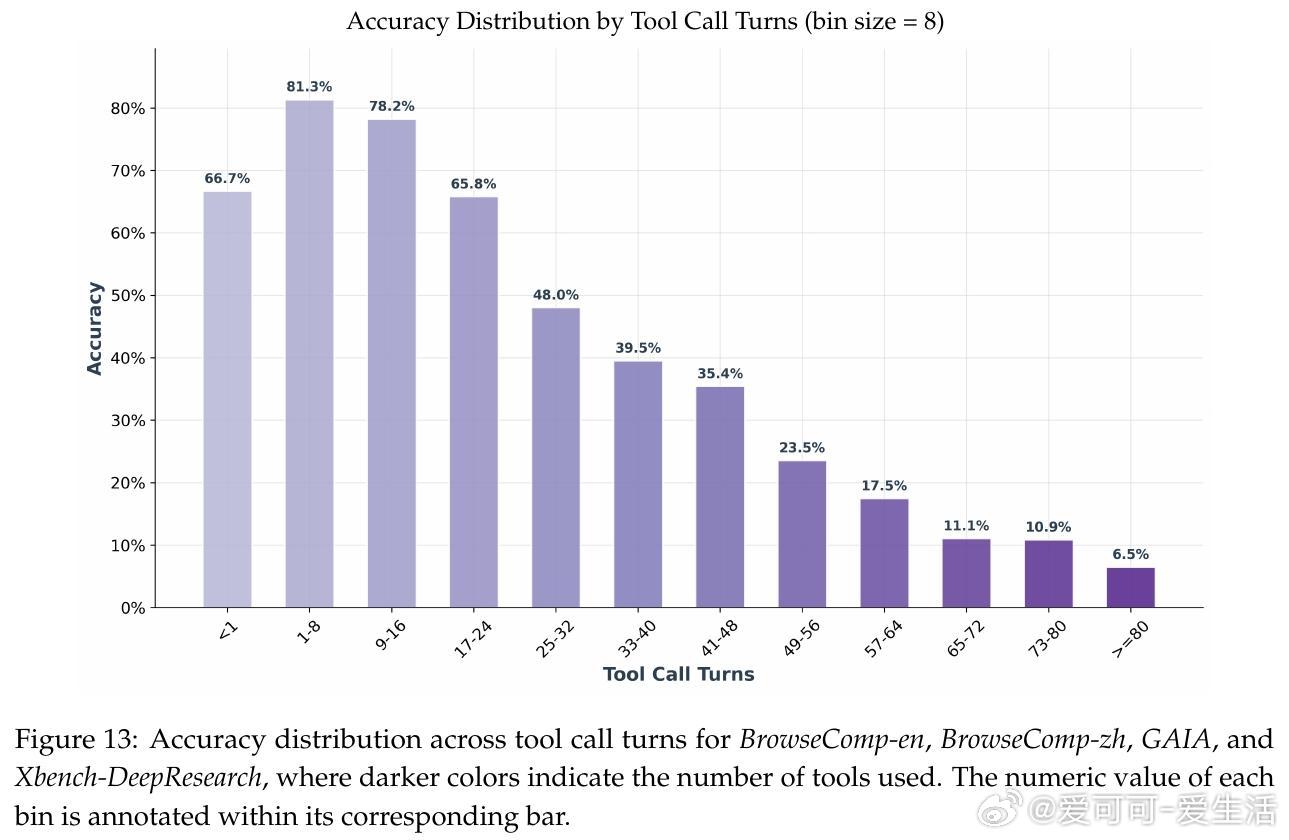
• 工具调用分析显示,AgentFounder能根据任务复杂度自适应调整调用频次,平衡探索与效率,在结构化和开放式任务中均表现稳定。
• 具备强大的泛化工具使用能力,在ACEBench等通用场景中也超越基础模型,展现未来通用智能体潜力。
心得:
1. 构建agentic基础模型而非单纯依赖后训练,显著提升了多步推理和工具调用的内生能力,避免了传统训练中“能力-对齐”矛盾。
2. 多样化且跨域的agentic数据合成,配合长上下文训练,是解决复杂决策与推理任务的关键。
3. 模型与数据的规模协同放大效应证明,系统性预训练策略能持续驱动性能突破,凸显了训练范式革新的长远价值。
详见🔗 arxiv.org/abs/2509.13310
人工智能大语言模型深度学习智能体持续预训练多模态AI