[LG]《Self-Improving Embodied Foundation Models》S K S Ghasemipour, A Wahid, J Tompson, P Sanketi... [Google DeepMind & Generalist AI] (2025)
基于大规模多模态预训练模型,本文提出机器人领域的两阶段后训练方法,实现自我提升与技能自主获取。
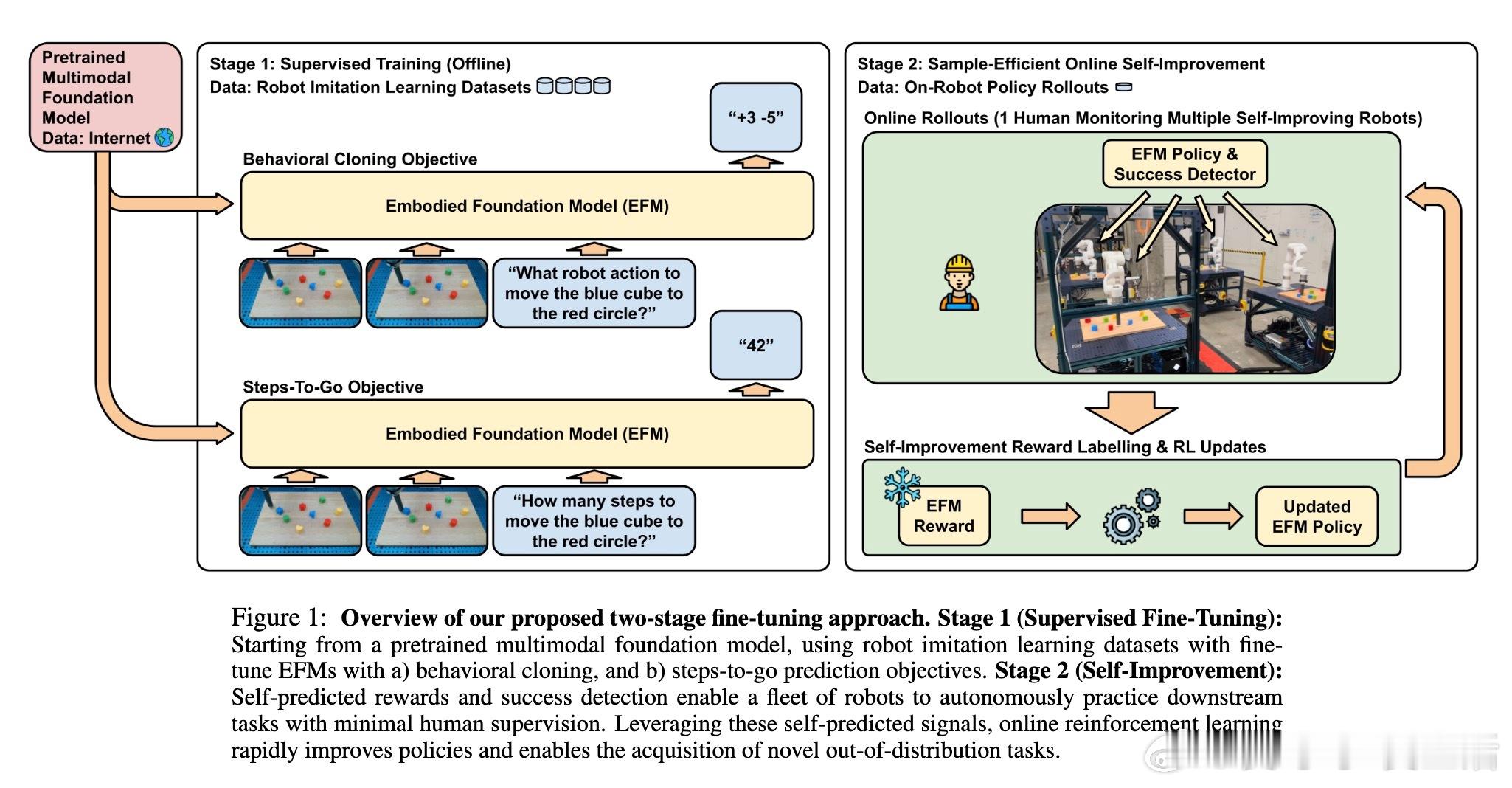
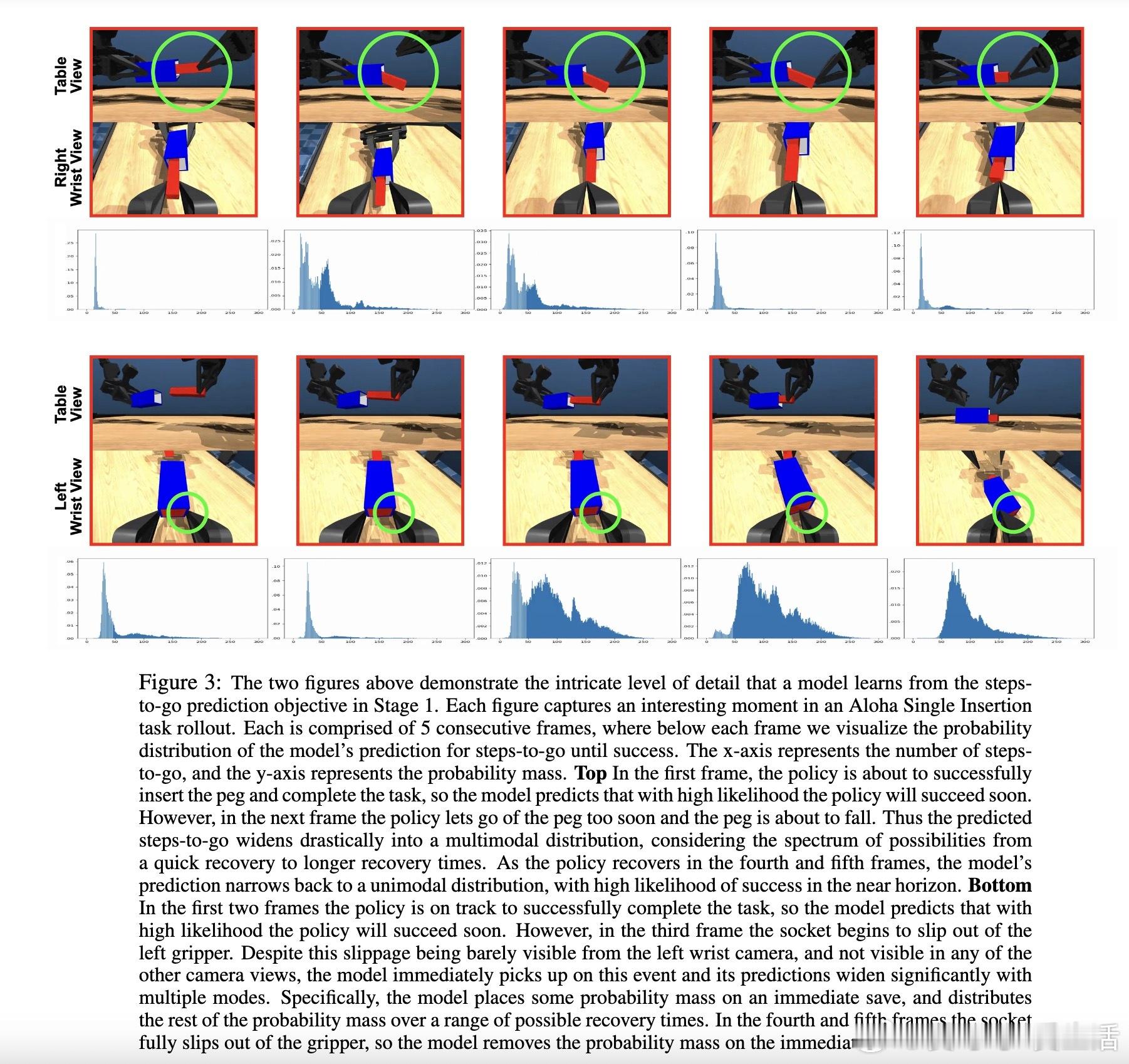
• 阶段一(SFT):结合行为克隆与“steps-to-go”预测,精细调优预训练的视觉语言基础模型,令机器人具备目标条件控制能力。
• 阶段二(自我提升):利用模型预测的steps-to-go设计数据驱动奖励函数和成功判定器,机器人在最小人类监督下自主在线强化学习,显著提升策略性能。
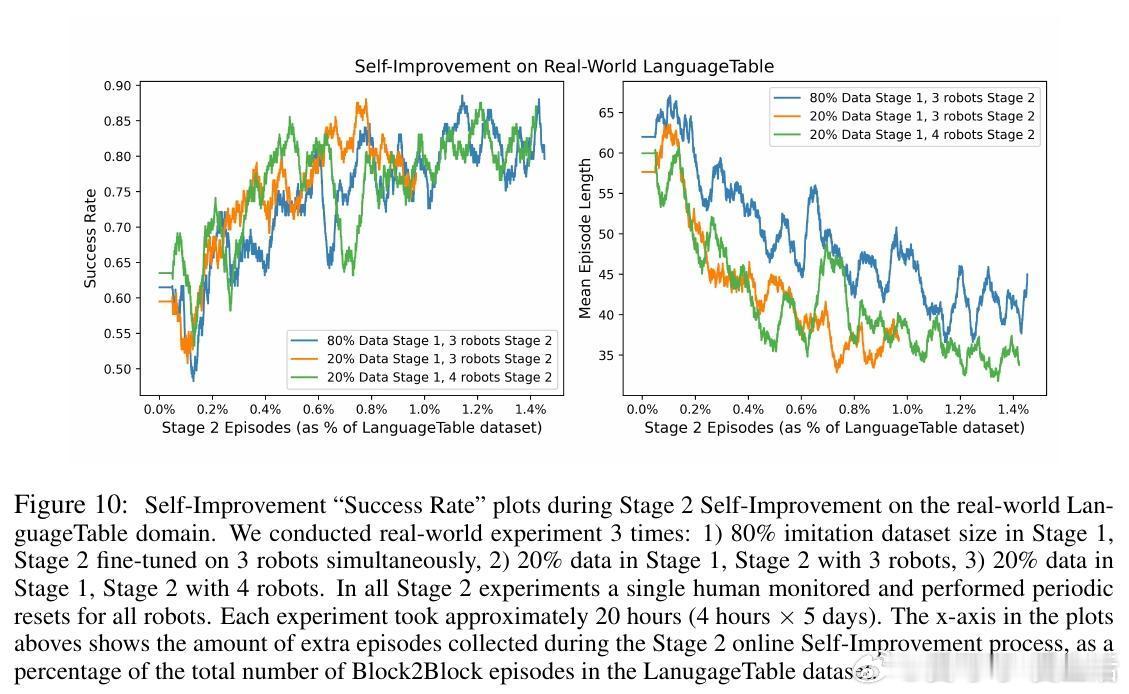
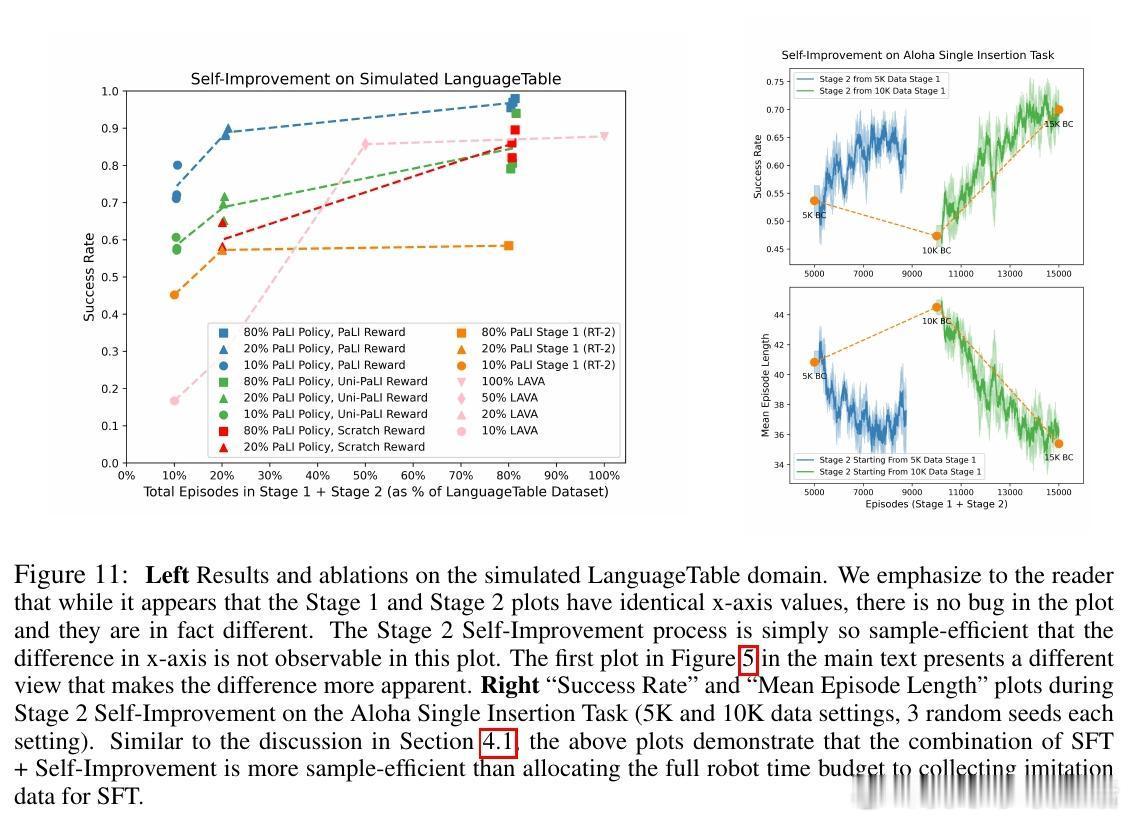
• 实验覆盖模拟及真实环境(LanguageTable、Aloha等),验证该方法较传统监督学习更高效且鲁棒,少量自我提升经验即可超越大规模模仿数据训练效果。
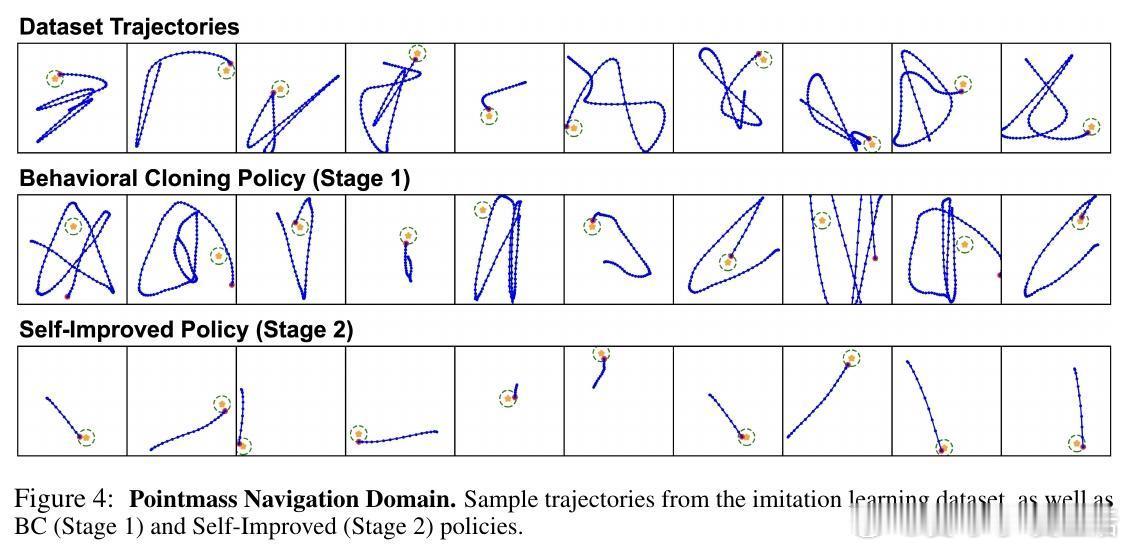
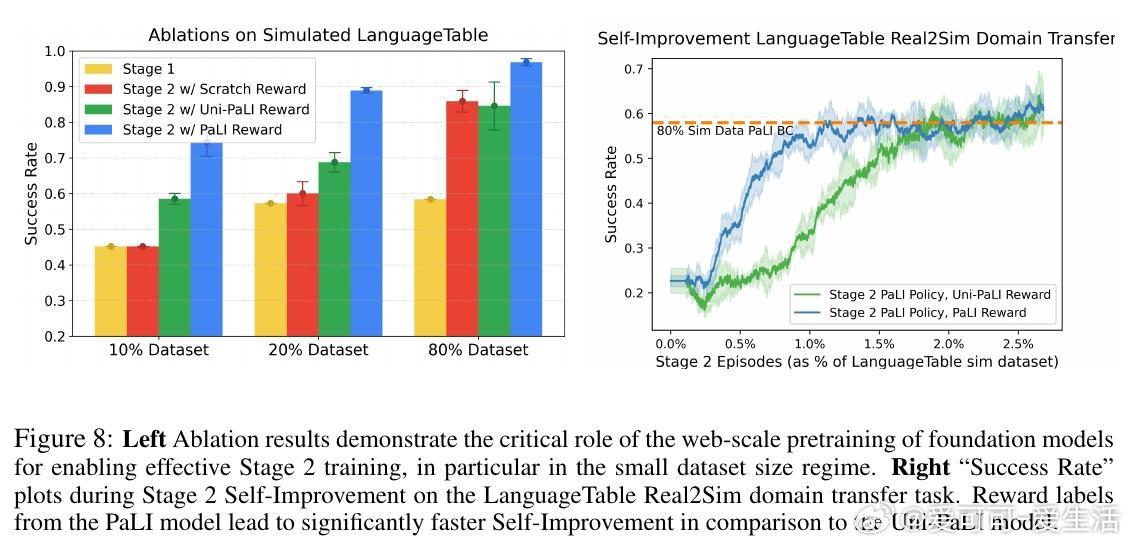
• 多模态预训练是实现高样本效率和泛化能力的关键,支持从现实到模拟的域迁移,并能自主习得模仿数据未覆盖的新行为,如BananaTable任务中的新颖操作技巧。
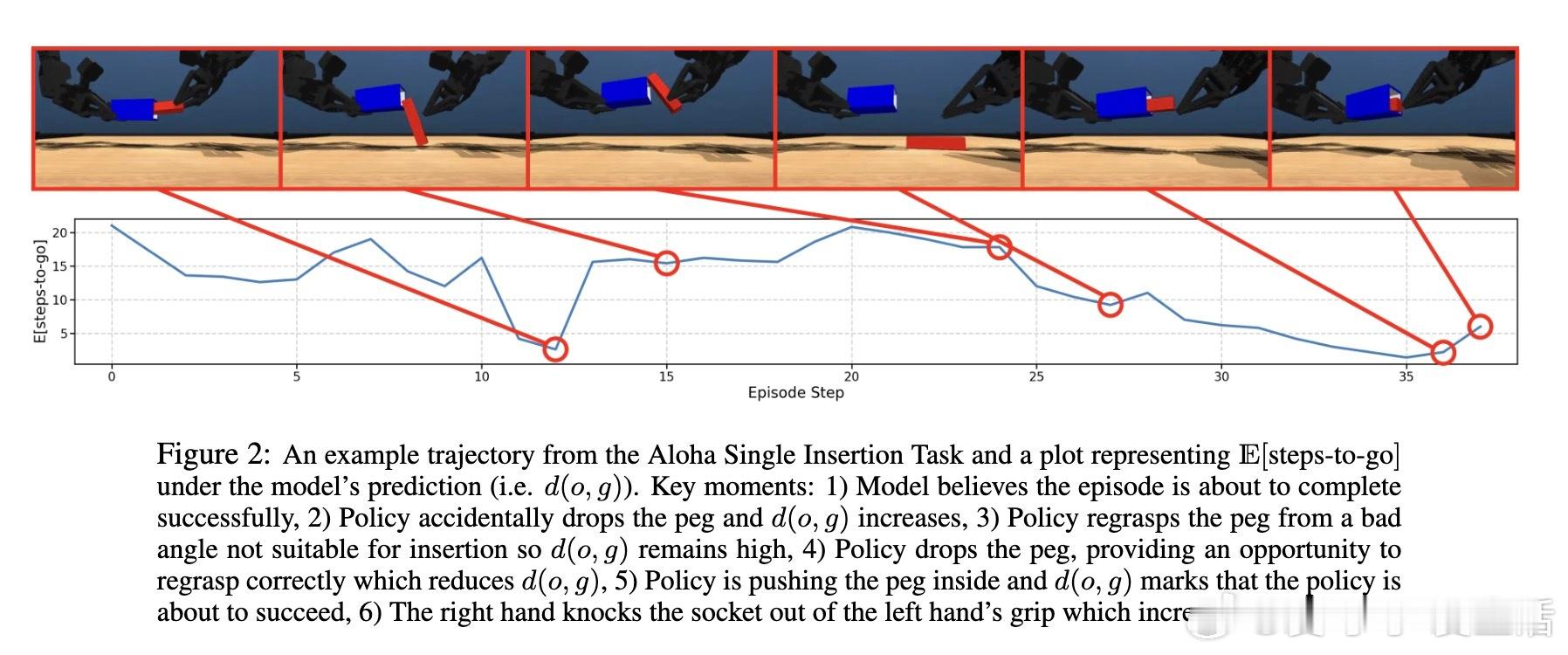
• 自我提升奖励函数基于steps-to-go的差值,隐含策略正则化,确保新策略在熟悉状态空间内优化,减少训练方差,避免复杂奖励设计与人工标注。
• 系统架构设计支持多机器人并行训练,一位操作员可监控多台机器人,极大降低人力成本。
• 未来方向包括技能分段、长时序任务的层次控制、利用更强奖励模型提升鲁棒性,以及探索离线与离策略算法提升样本利用率。
心得:
1. 预训练模型赋予的丰富视觉语言知识为机器人自主学习奠定基础,远超随机初始化或单模态预训练效果。
2. 利用模型自身的steps-to-go预测构建奖励与成功判定,突破传统奖励工程瓶颈,实现无需人工定义即可在线强化学习。
3. 结合行为克隆与自我提升的两阶段训练策略,不仅提升样本效率,更开启机器人自主习得新技能的可能,推动通用机器人智能发展。
详见🔗arxiv.org/abs/2509.15155
机器人基础模型强化学习自主学习多模态预训练样本效率