[LG]《Pre-training under infinite compute》K Kim, S Kotha, P Liang, T Hashimoto [Stanford University] (2025)
预训练新时代:在数据受限、计算无限的未来,如何实现更高效的语言模型预训练?
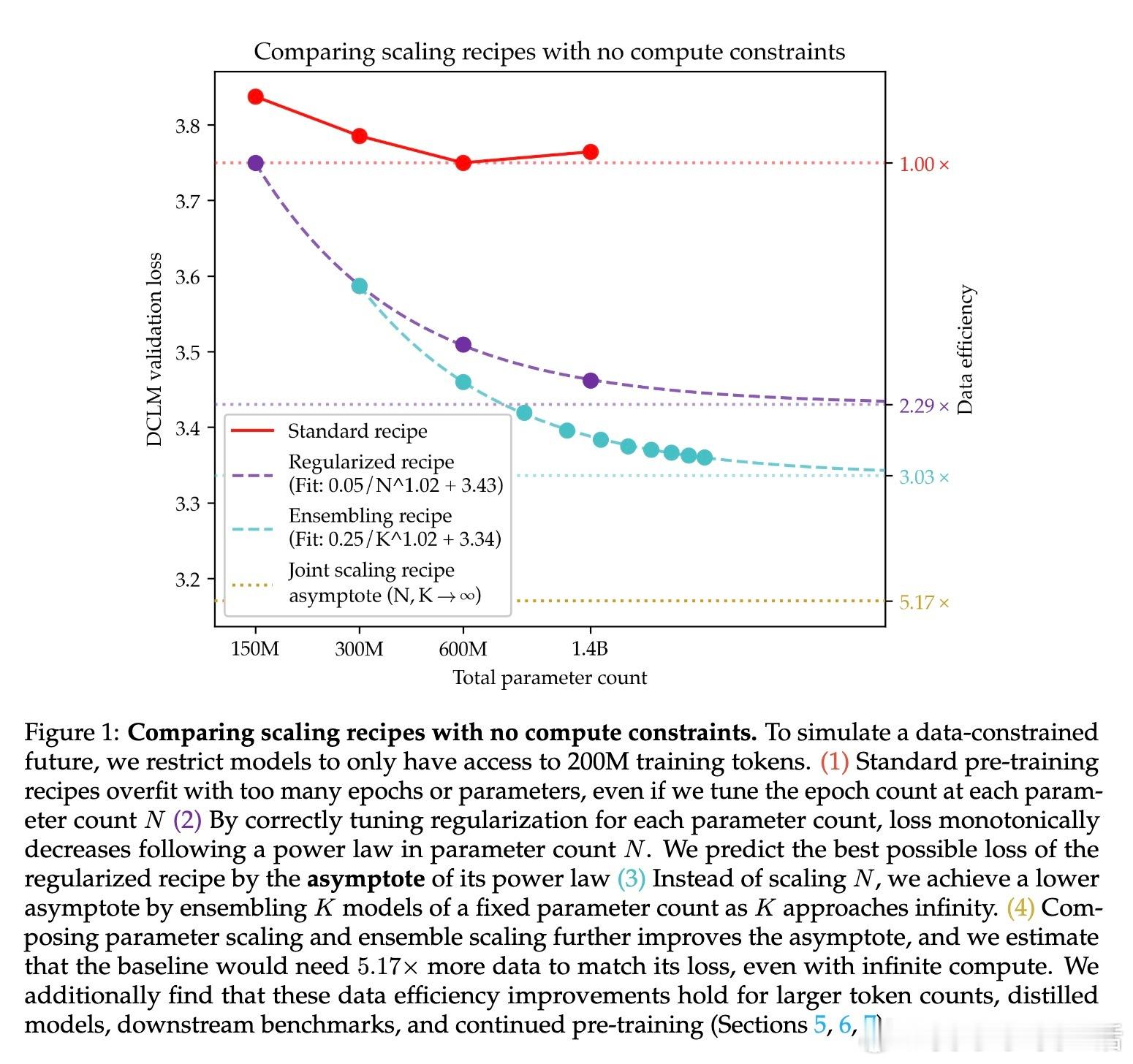
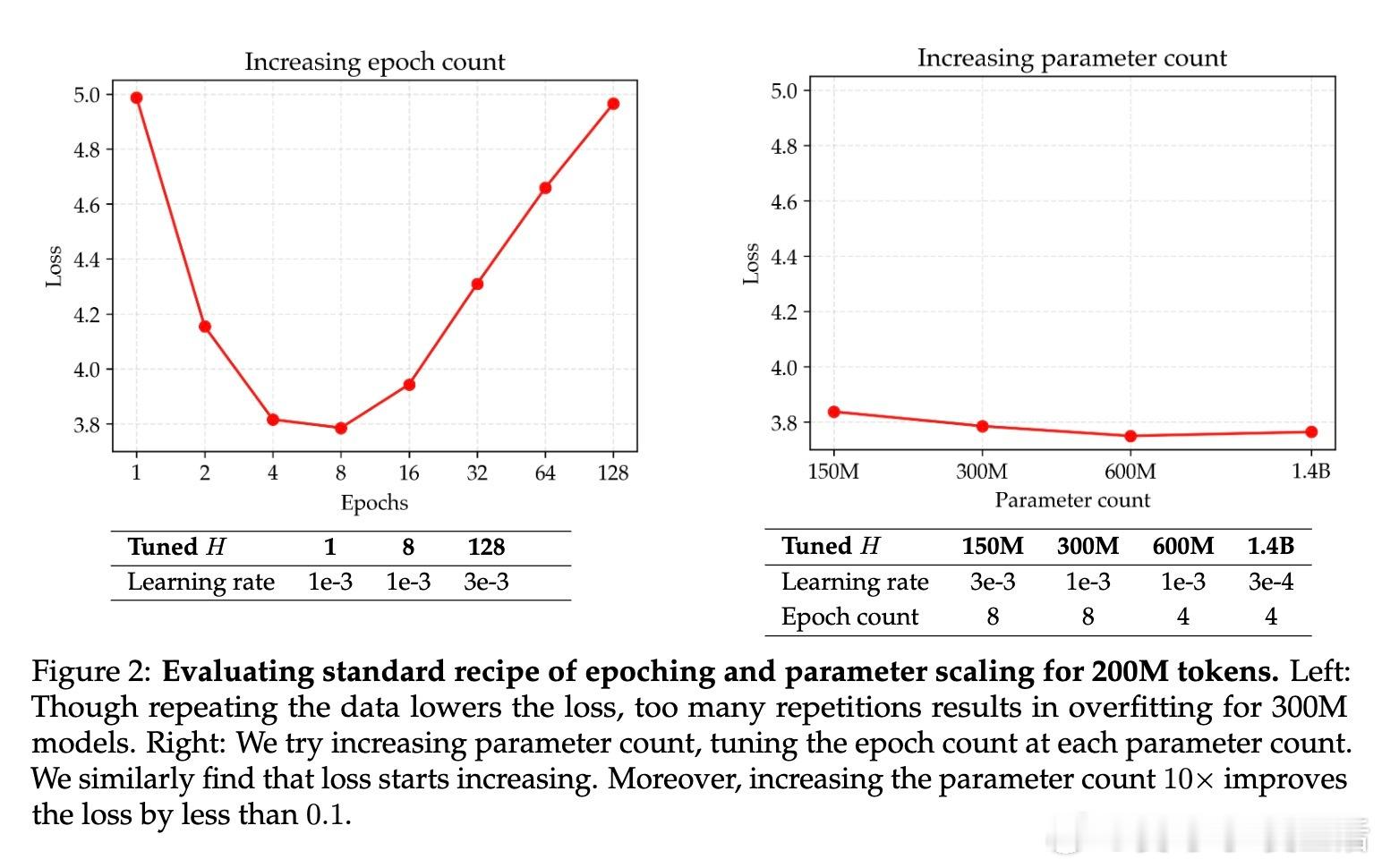
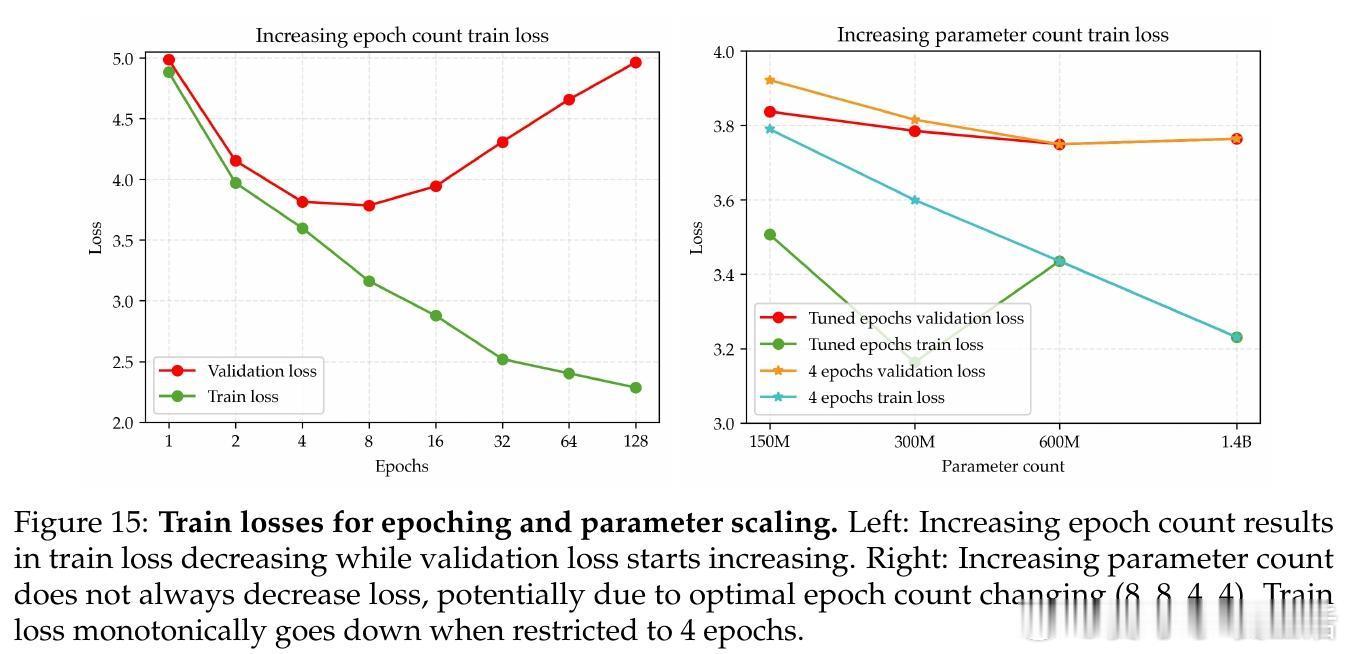
• 传统做法下,重复训练数据(epoching)和扩大模型参数规模都会导致过拟合,优化空间受限。
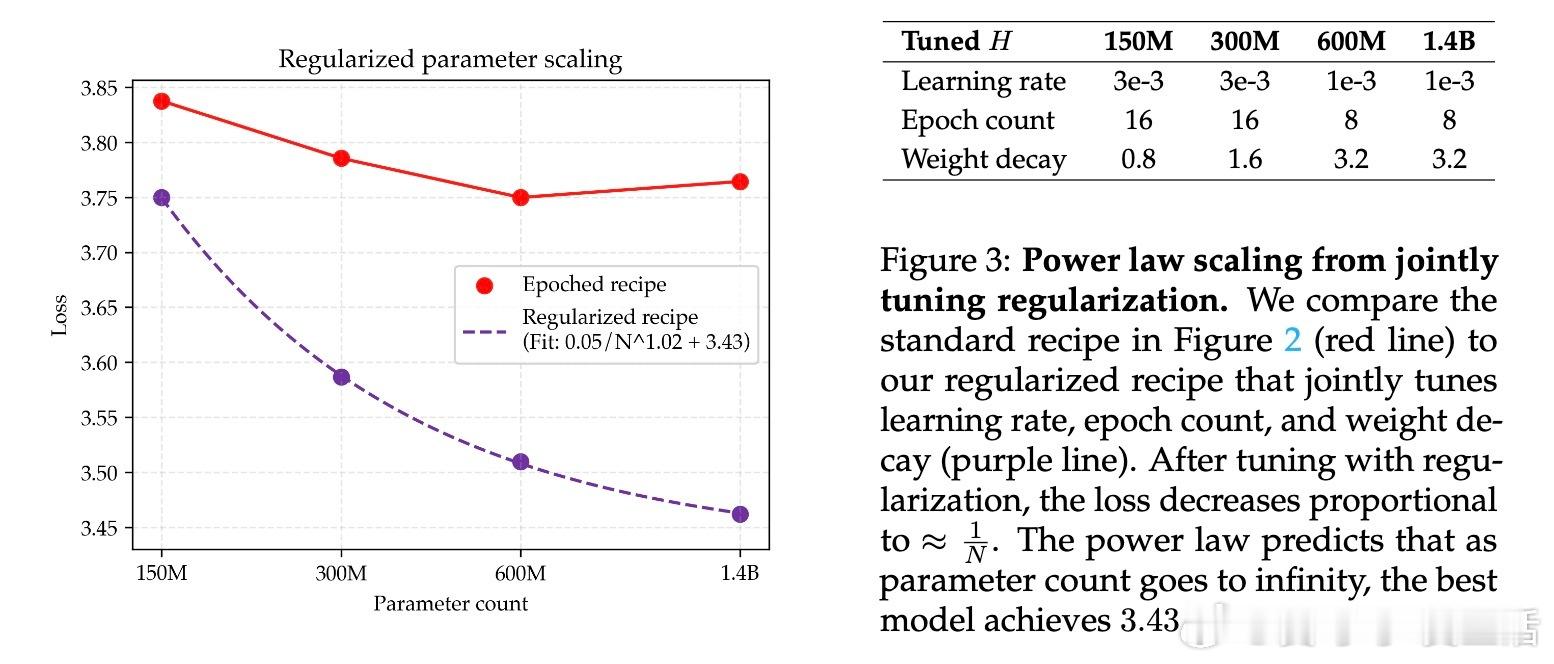
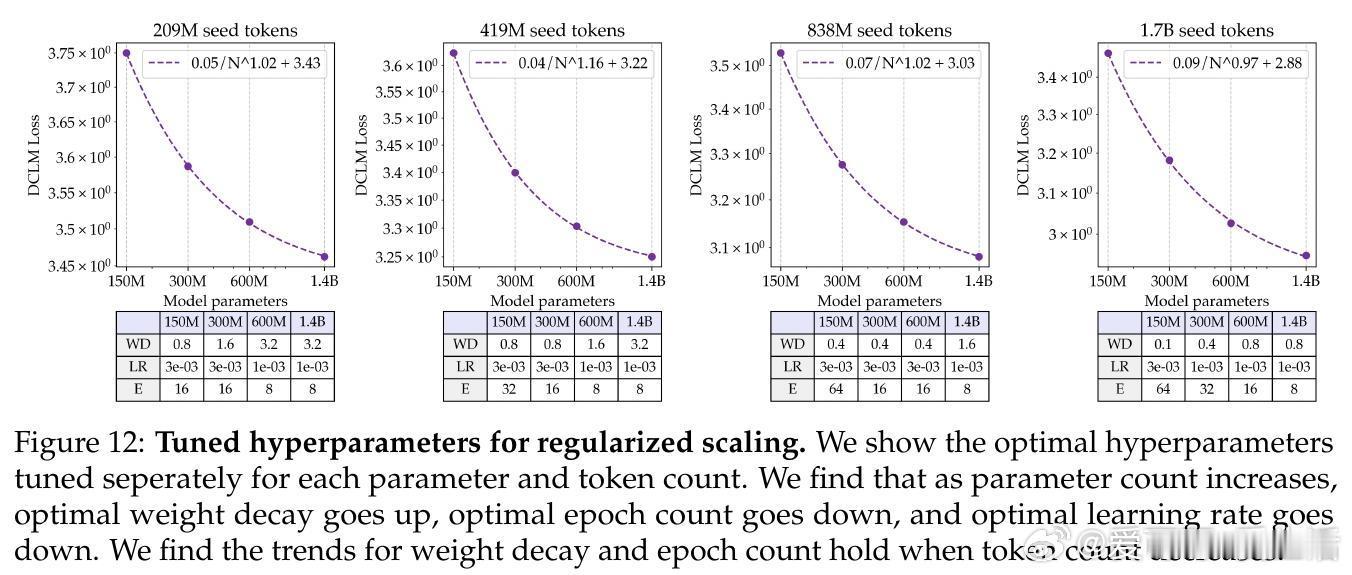
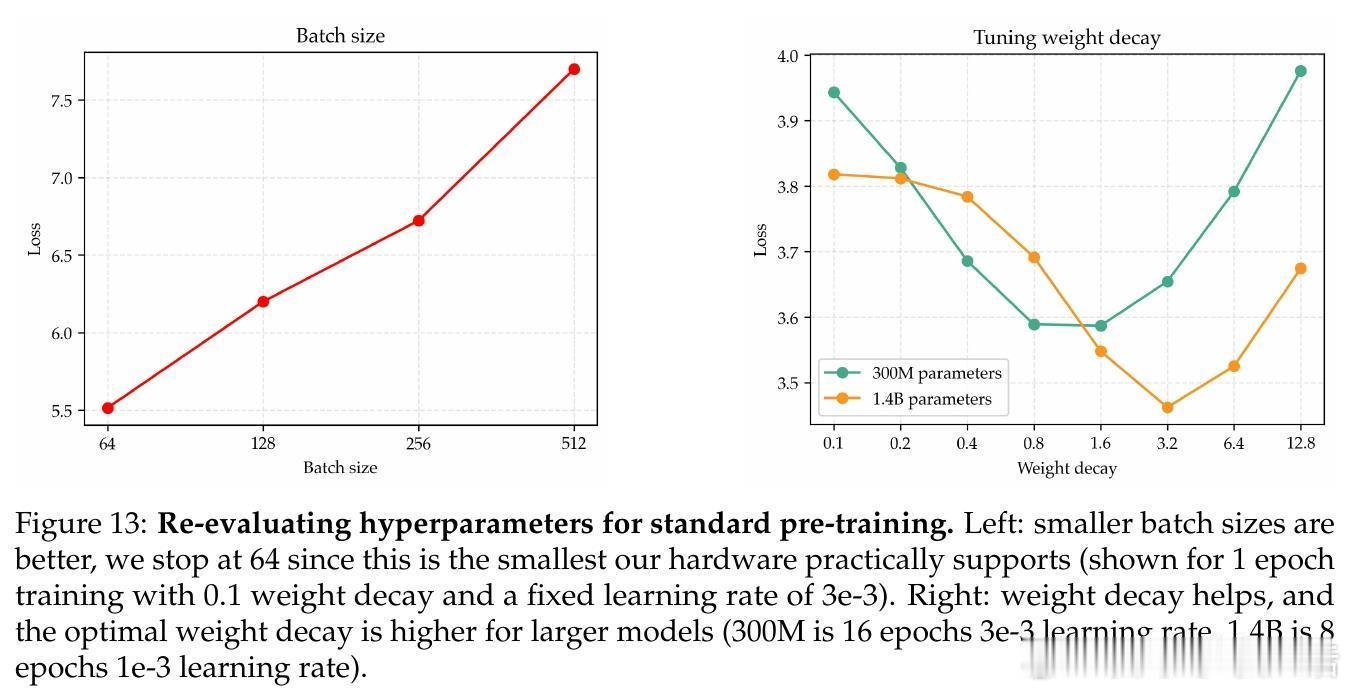
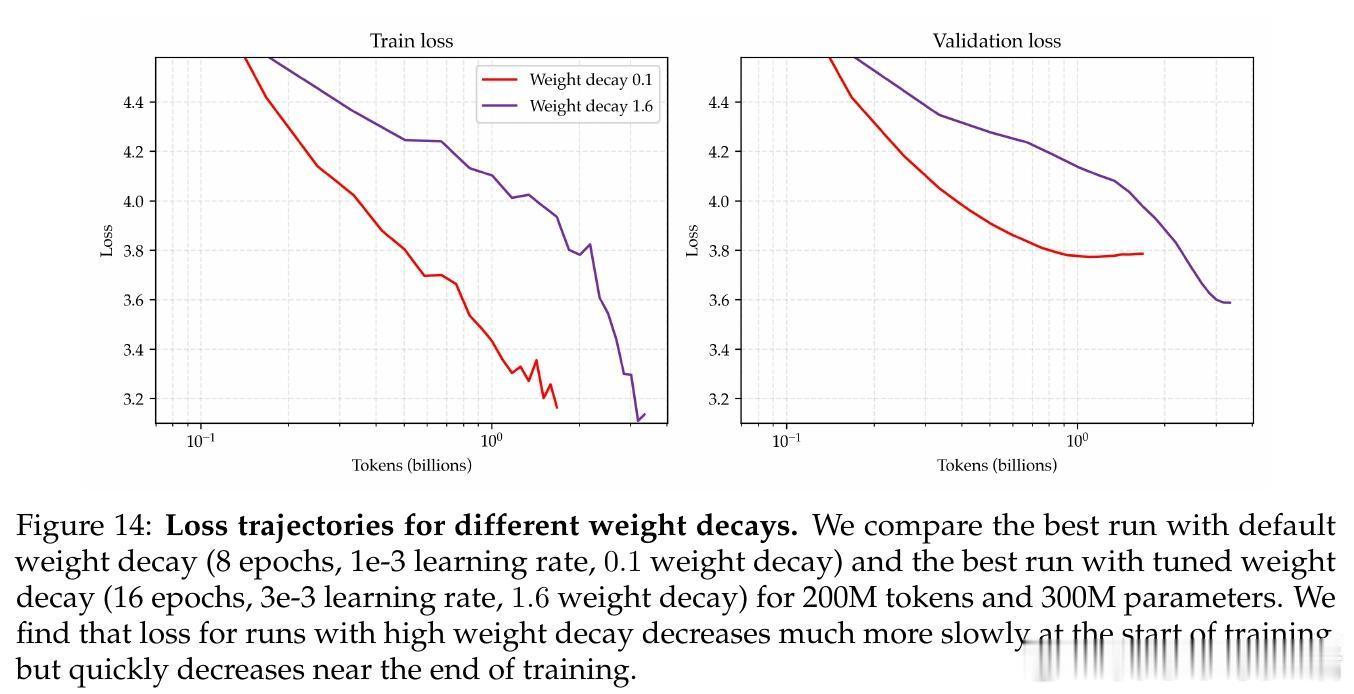
• 通过大幅提升正则化强度(权重衰减比标准方案高30倍),结合学习率和训练轮数的联合调优,实现了参数规模单调递减的损失曲线,模型表现遵循强幂律规律。
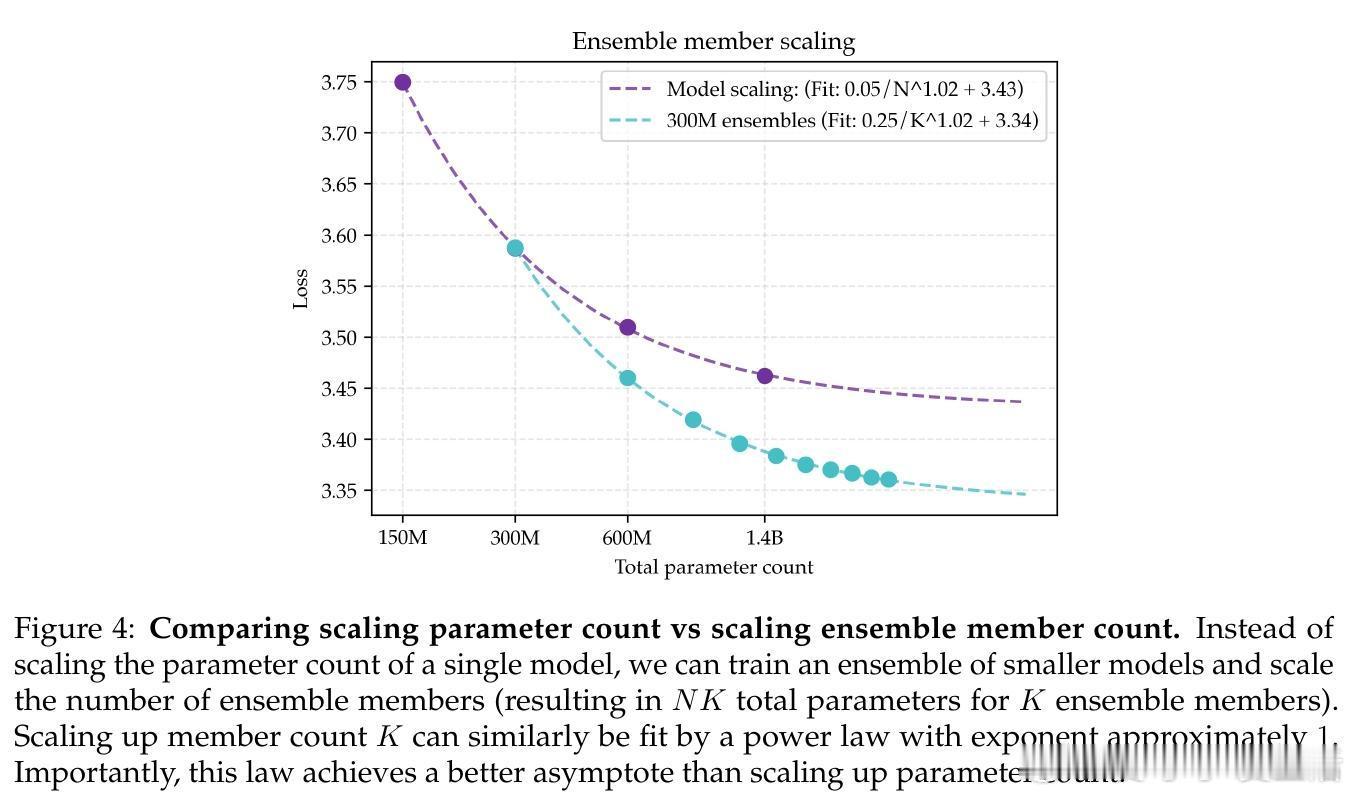
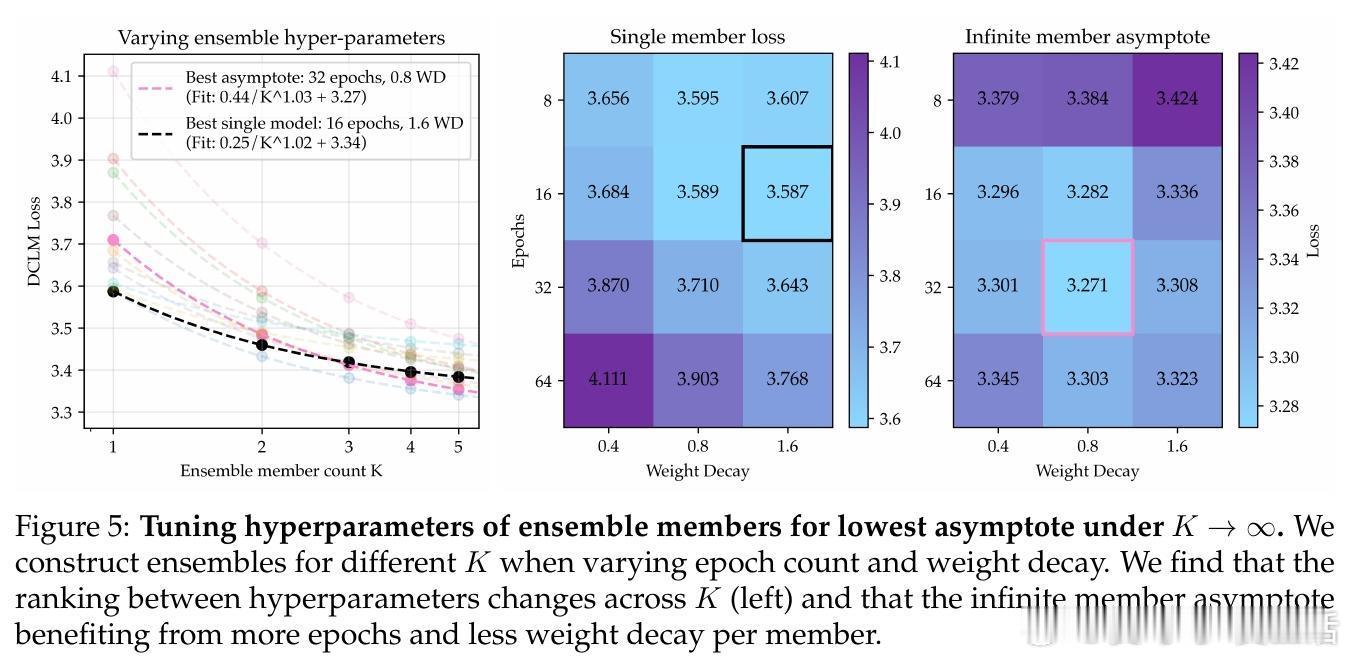
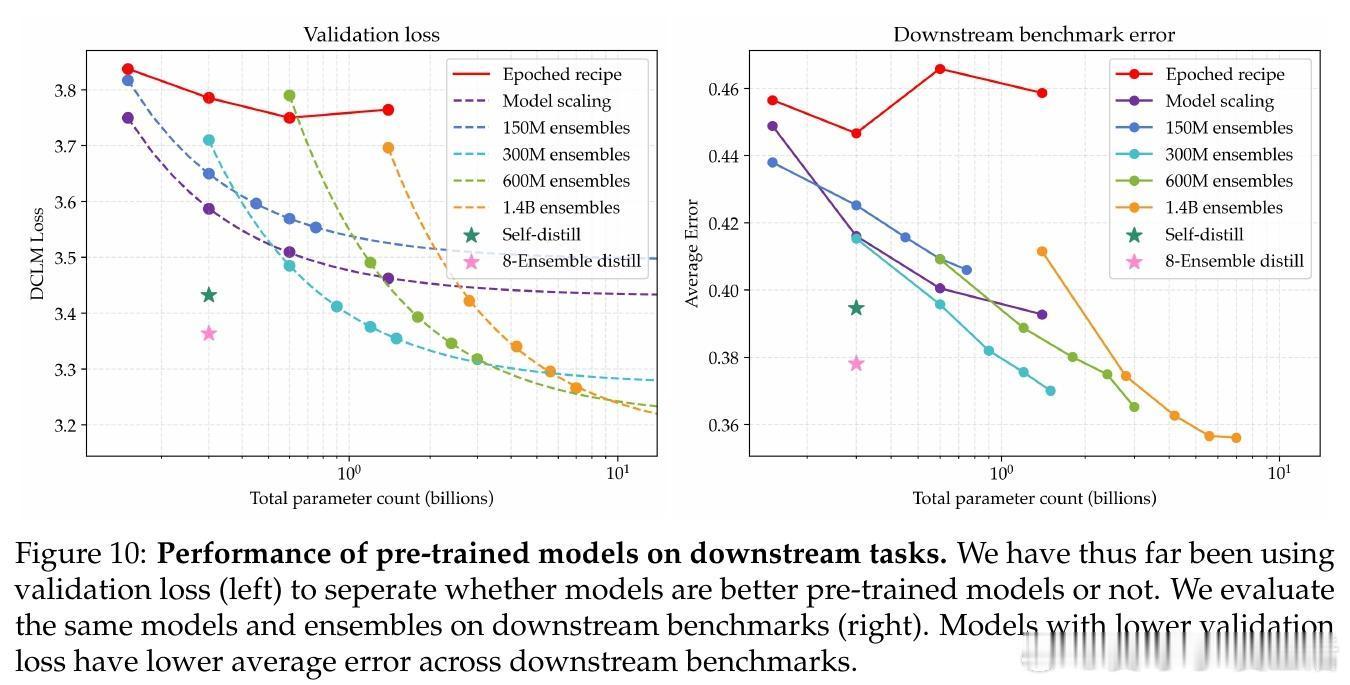
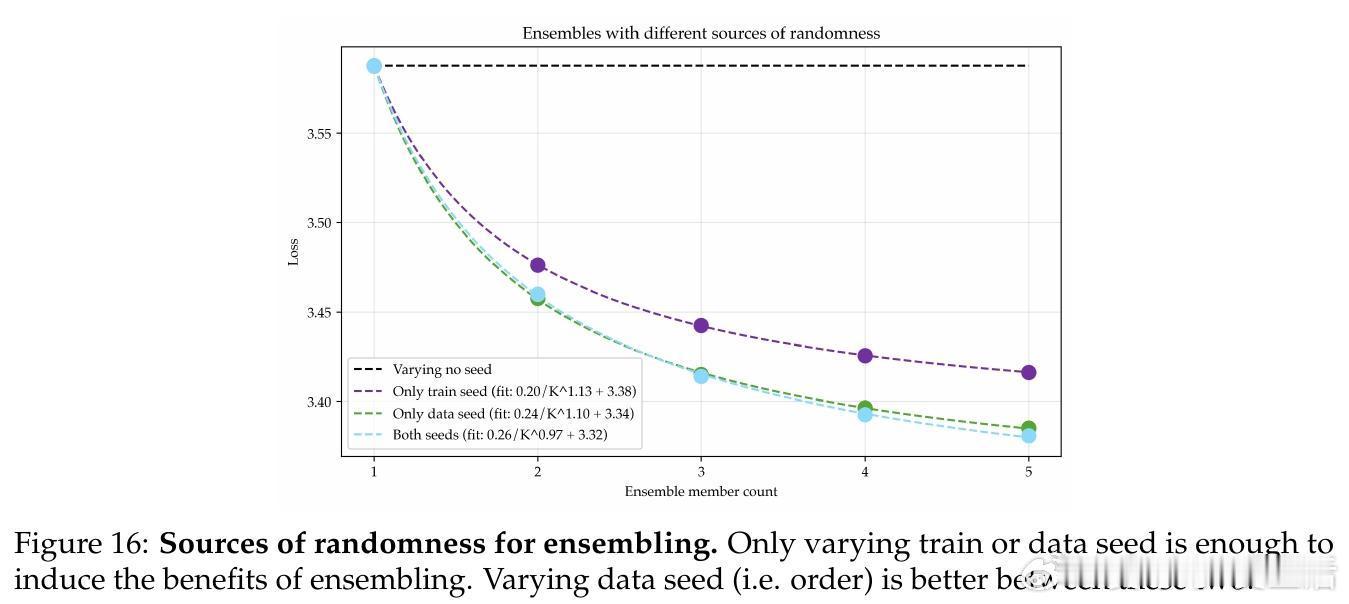
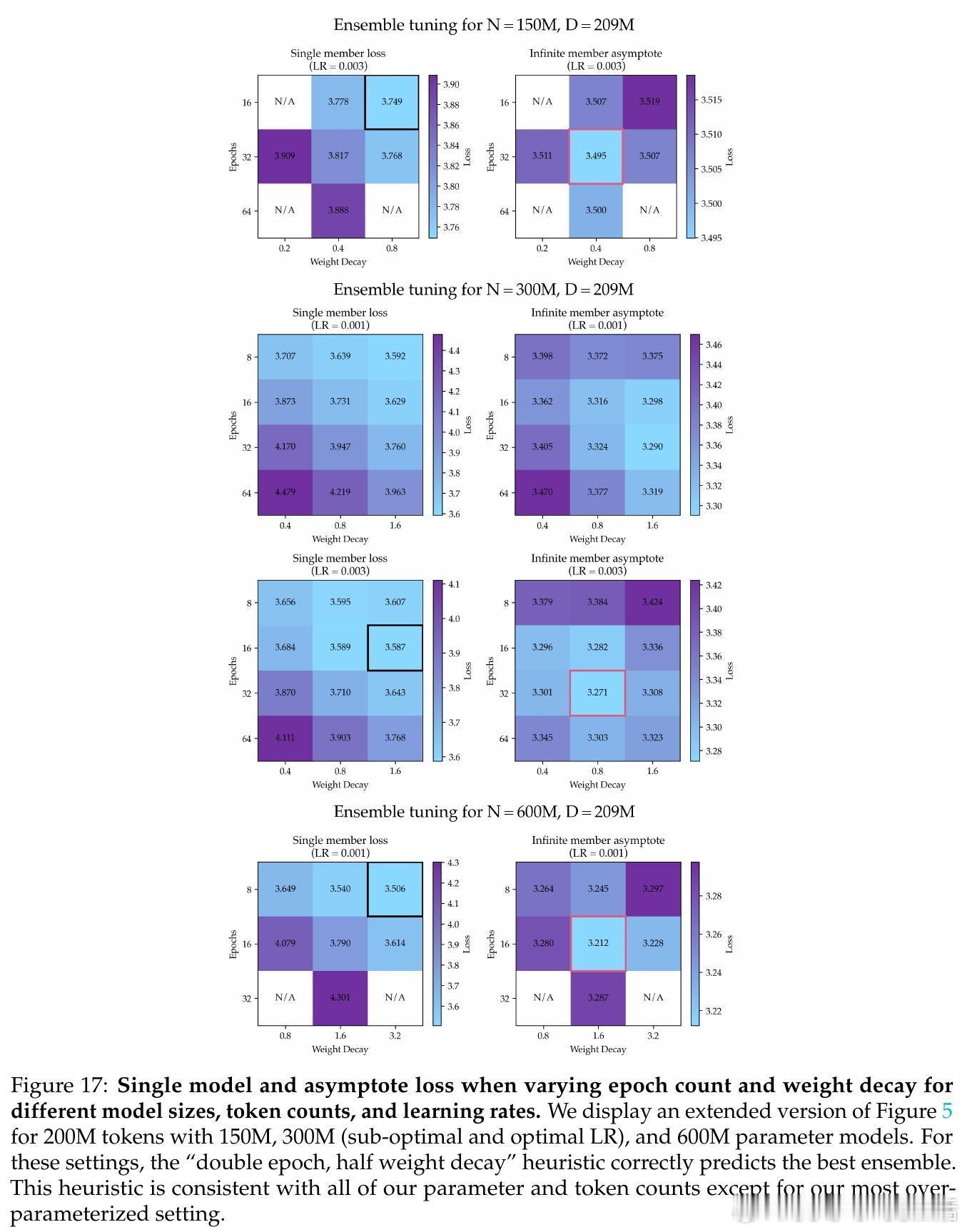
• 引入模型集成(ensemble)策略,训练多个独立模型并对其logits取平均,显著降低了损失的渐近值,超过单一大模型的性能极限。
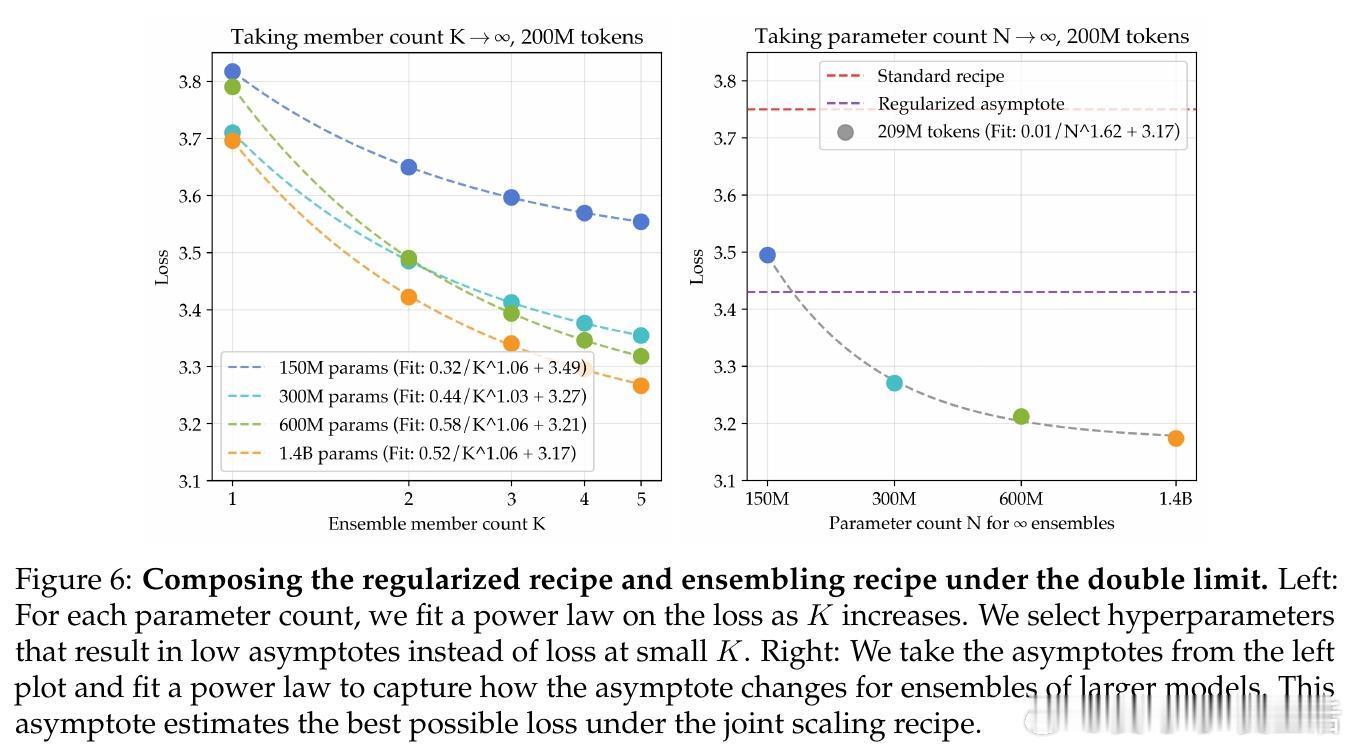
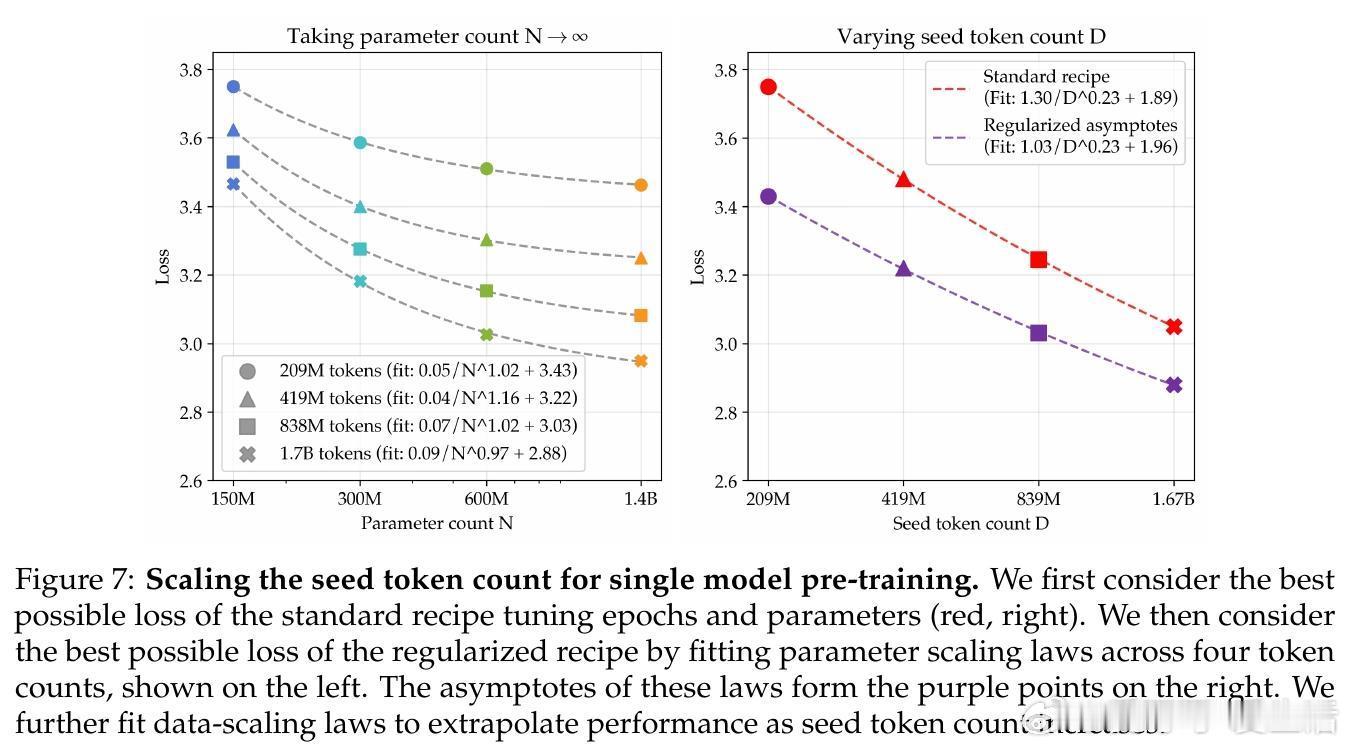
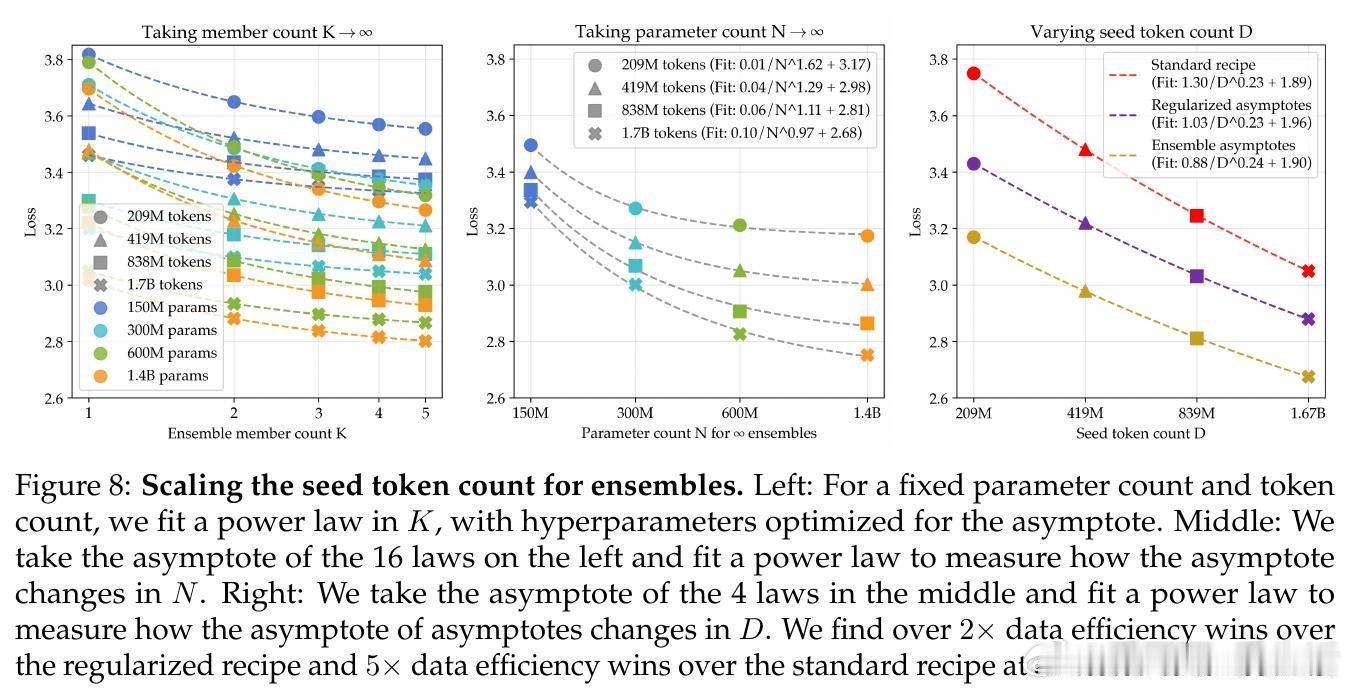
• 结合参数扩展与集成扩展的“双重极限”方法,进一步将数据需求减少5.17倍,提升数据利用效率,同时保证性能提升可持续扩展到更大数据规模。
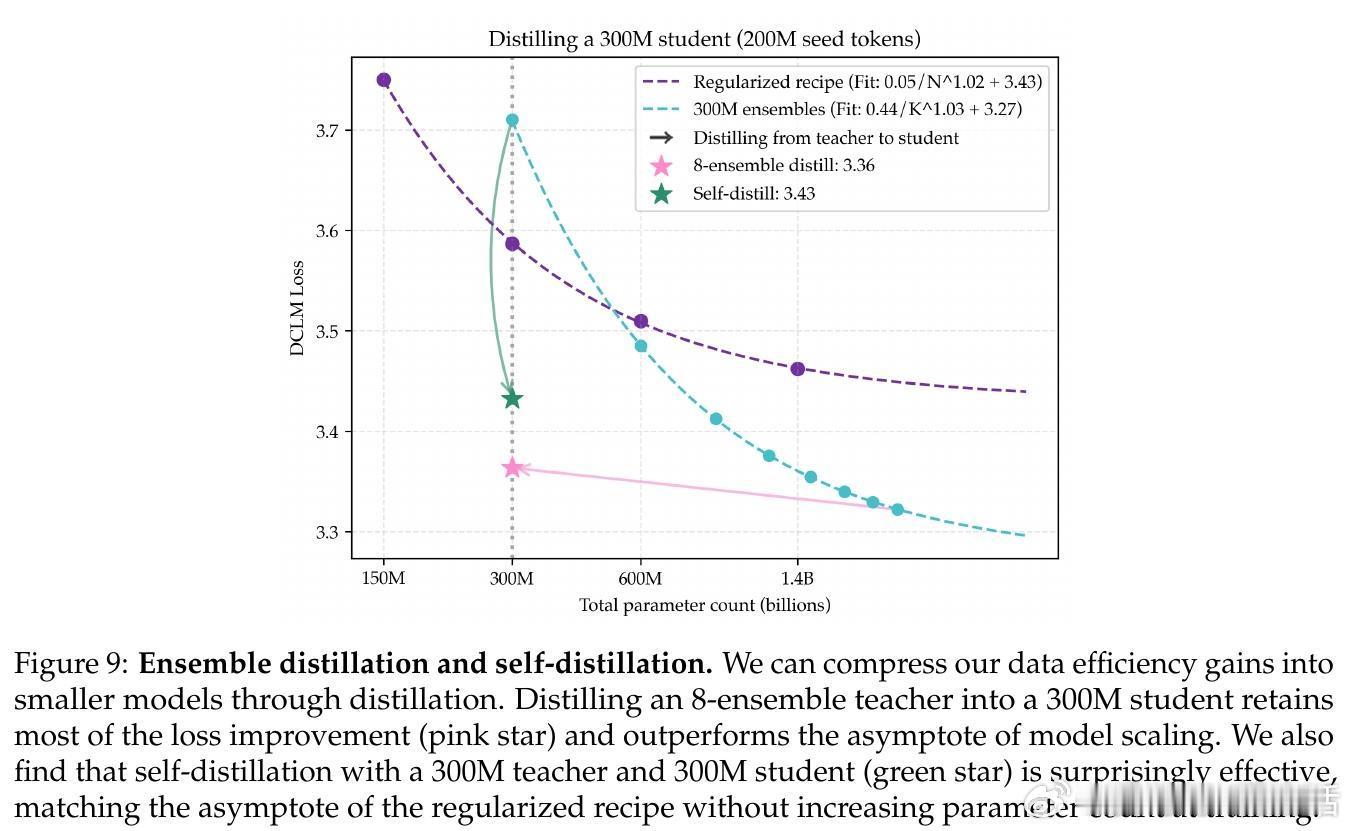
• 通过知识蒸馏,将多个大模型集成的优势压缩到单一小模型,学生模型仅为教师模型参数的1/8,仍保留83%的性能增益,极大降低推理成本。
• 自蒸馏(self-distillation)技术使同尺寸模型教师-学生训练超越原模型,避免了模型崩溃风险,提升数据效率无须扩大训练模型规模。
• 所有改进在下游任务验证集及继续预训练(CPT)中均获得显著收益,集成策略在数学任务中实现了17.5倍的数据效率提升。
心得:
1. 数据有限但计算充裕的环境下,传统的“更大模型+更多数据”思路失效,适当调节正则化和训练策略可解锁更优泛化性能。
2. 集成多模型的多样性优势不止于单模型参数扩展,更能有效利用有限数据的多视角特征学习机会,提升最终表现。
3. 蒸馏技术不仅压缩推理模型规模,还能通过自蒸馏创新性的提升训练效率,避免过拟合和模型退化,揭示合成数据的巨大潜力。
更多细节请见🔗arxiv.org/abs/2509.14786
大规模预训练模型集成知识蒸馏数据效率语言模型