[LG]《FlowRL: Matching Reward Distributions for LLM Reasoning》X Zhu, D Cheng, D Zhang, H Li... [Shanghai Jiao Tong University & Renmin University of China & Microsoft Research] (2025)
FlowRL:从奖励最大化到匹配奖励分布,提升大模型推理多样性与泛化能力
• 颠覆传统RL思路,FlowRL不再追求单一最大化奖励,而是通过可学习的归一化分区函数,将标量奖励转化为目标分布,最小化策略与该分布的逆KL散度,实现奖励分布匹配。
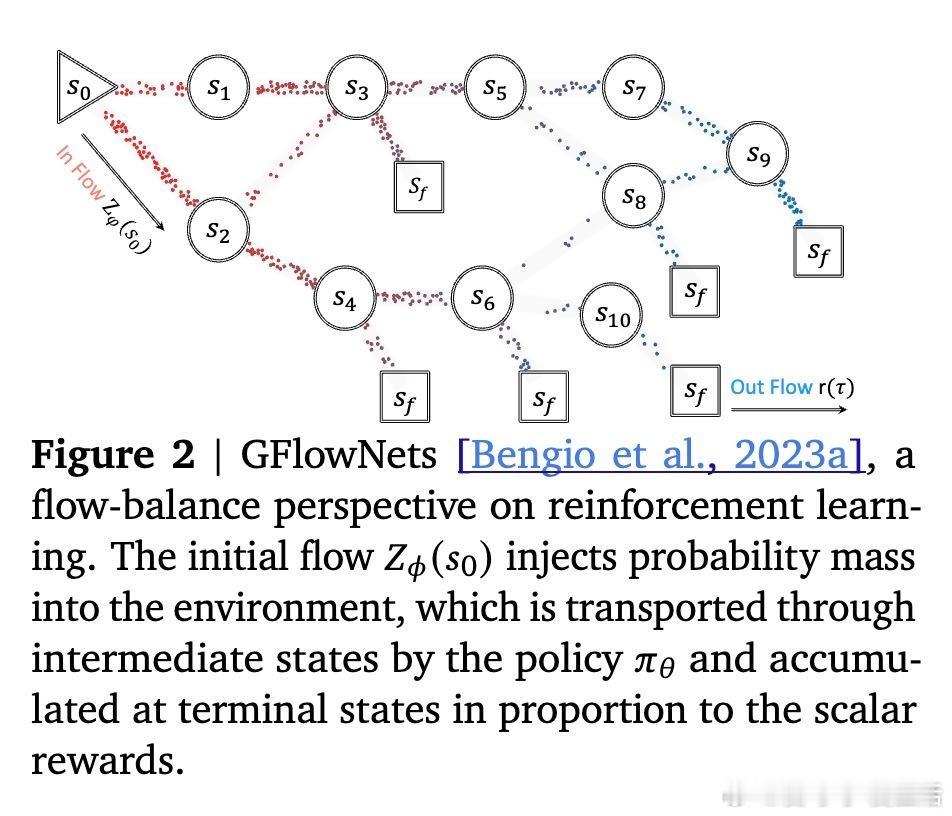
• 采用GFlowNets的轨迹平衡思想,等价于同时优化奖励和策略熵,促进多模态解空间探索,避免模式崩溃常见于PPO、GRPO等最大化方法。
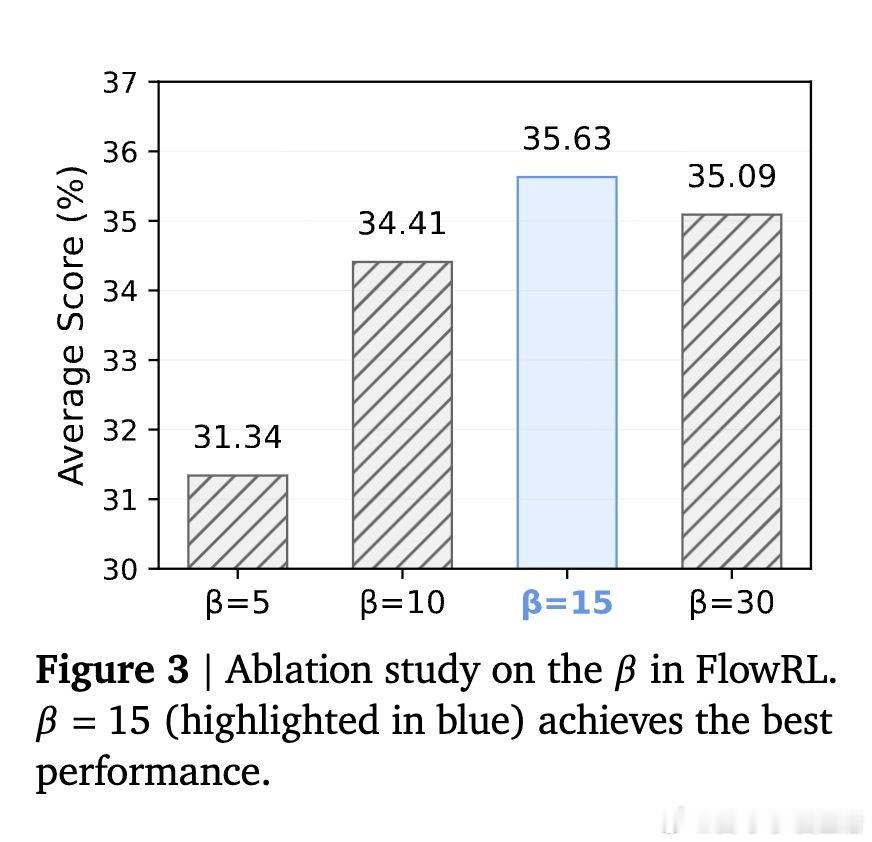
• 针对长链条思考(CoT)训练中梯度爆炸和采样分布不匹配问题,创新引入长度归一化和重要性采样,有效稳定训练流程。
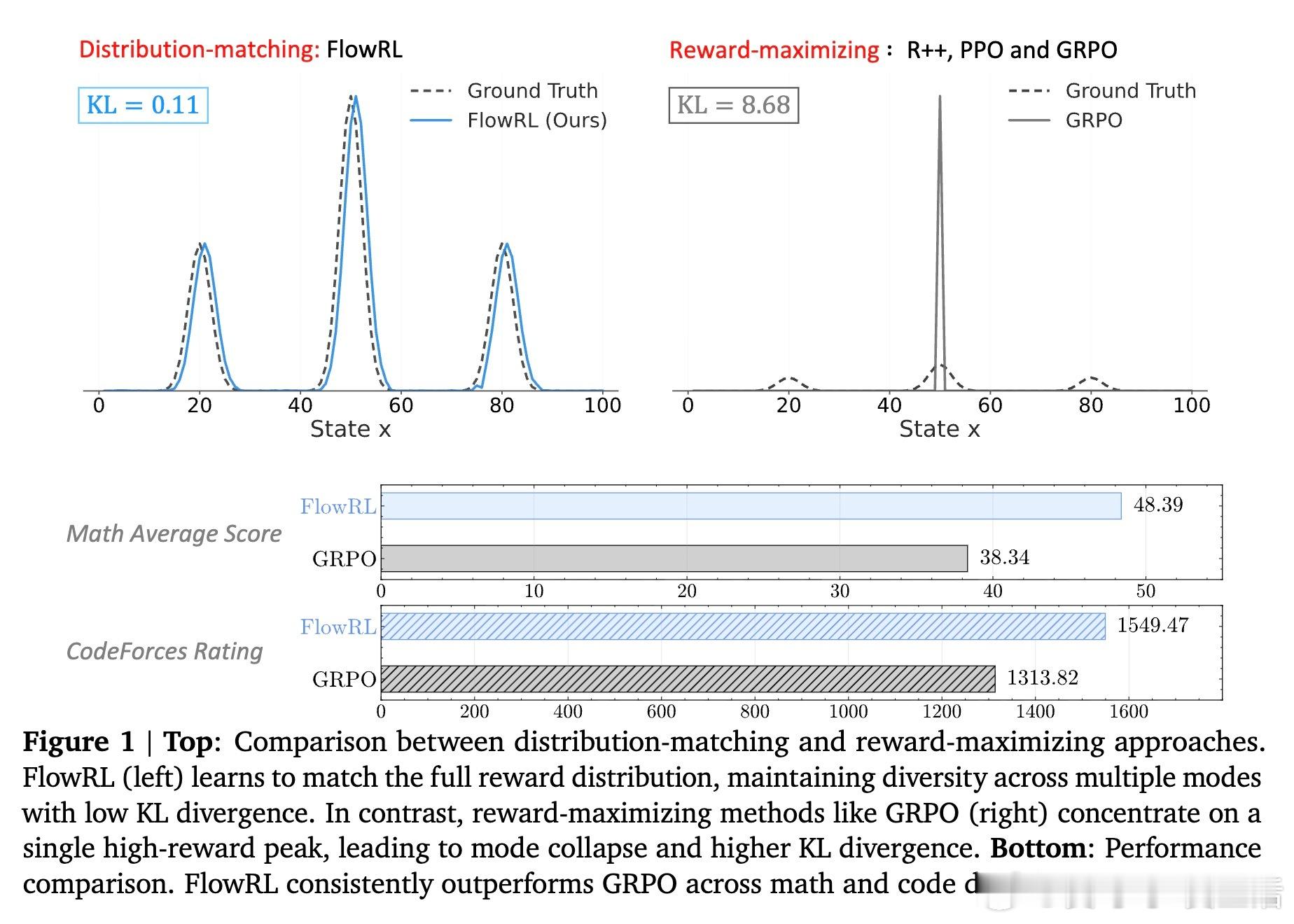
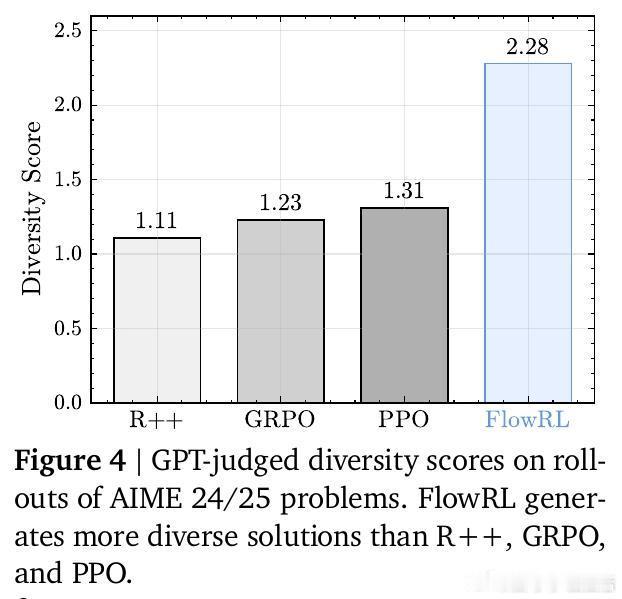
• 在数学和代码推理任务上,FlowRL相比GRPO和PPO分别提升10.0%和5.1%的平均准确率,且在多样性评测中几乎翻倍,展现出更丰富的推理路径和更强泛化能力。
• 案例分析显示,FlowRL能跳出传统固定套路,探索多样且合理的解法策略,显著提升复杂问题求解的灵活性与准确性。
心得:
1. 奖励分布匹配优于单点奖励最大化,能系统覆盖多种高质量推理路径,助力模型跳出局部最优。
2. 将归一化分区函数作为可学习参数,巧妙解决了计算难题,实现了稳定且高效的分布拟合。
3. 长度归一化与重要性采样的结合,为长文本推理强化学习提供了切实可行的技术保障。
详见🔗arxiv.org/abs/2509.15207
大语言模型强化学习奖励分布匹配推理多样性GFlowNets机器学习