GPT5编程测评大反转GPT5解决率实则是Claude两倍
GPT-5编程测评出现反转了。
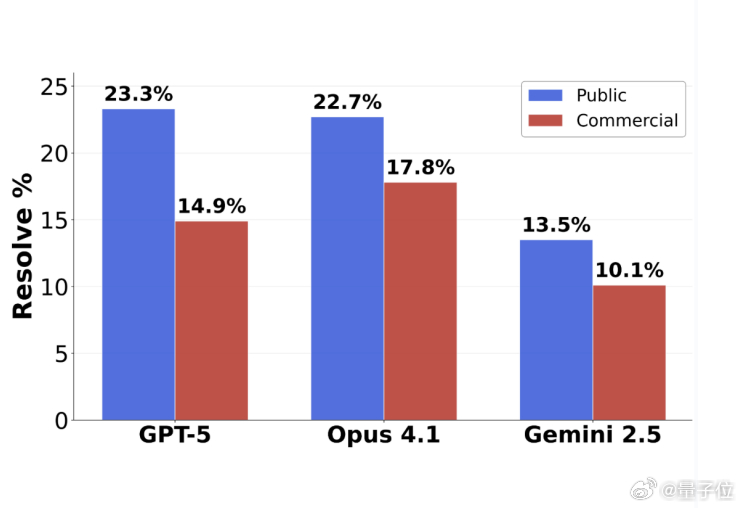
在最新的软件工程基准SWE-BENCH PRO上,GPT-5、Claude Opus 4.1、Gemini 2.5看似集体“翻车”,解决率都不超过25%。
但仔细一看,GPT-5其实还有63.1%的任务压根没交卷!真正交卷的部分,解决率高达63.1%,是Claude的两倍(31%)。
换句话说,只要它认真答,基本都能对。
为啥大家突然答题都变差了?并不是模型退步,而是题目升级了。
SWE-BENCH PRO是OpenAI今年8月新出的基准,设计上专门避开老版本数据污染,避免大模型靠记忆“作弊”。同时还尽量模拟工业级开发流程,问题动辄跨多文件、需要几十上百行代码修改,难度直接拉满。
它的代码库来自真实B2B公司和公共GPL项目,不仅覆盖Python、Go、JavaScript等主流语言,还用容器环境做自动评估,失败还要人工复核。最关键的是,删掉了所有“一两行能改完”的“水题”。
哪怕是GPT-5、Claude这种顶级大模型,在商业代码测试集上的解决率也没破20%,可见挑战有多大。
研究团队还拆解了各种模型失败的原因:
- Claude理解语义容易错,技术执行还行;
- GPT-5问题理解能力强,但答得少;
- Gemini工具和代码都容易出错;
- Sonnet上下文能力不够,常常读文件读到失控;
- Qwen-3 32B更是42%的工具调用失败率,暴露了开源模型整合能力的短板。
这次测评最大的看点是,模型能力的“上限”依然可观,但“全面能力”距离真实编程还有不小差距。
你认为谁会是第一个突破30%的大模型?评论区说说看。