NVIDIA Nemotron Nano 2:融合Mamba-Transformer架构的高效推理模型,兼具卓越准确率与极高推理吞吐量。
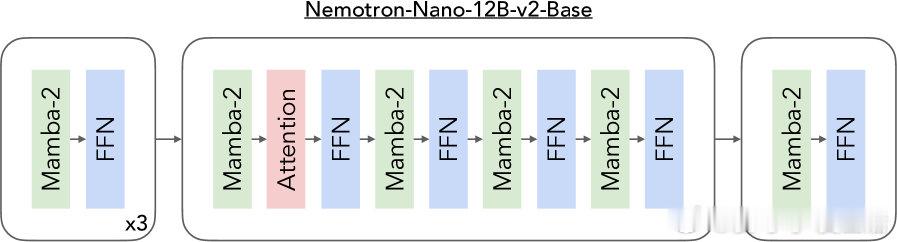
• 模型架构:12B参数基础模型(Nemotron-Nano-12B-v2-Base)融合6个自注意力层、28个FFN层及28个Mamba-2层,隐藏维度5120,FFN维度20480,采用Grouped-Query Attention,支持128k超长上下文推理。
• 训练策略:以20万亿tokens的多模态数据集预训练,涵盖高质量网页抓取、多语种、数学、代码与学术文本,结合FP8数值格式及Warmup-Stable-Decay学习率调度提升训练效率。
• 合成数据拓展:通过多轮生成与筛选,增强数学、STEM、基础推理及多语种问答能力,显著提升模型对复杂逻辑和长文本的理解与生成。
• 对齐与后训练:多阶段SFT、GRPO、DPO与RLHF强化指令遵循、工具调用及对话交互能力,采用模型融合平衡推理与聊天表现。
• 模型压缩:基于Minitron框架的轻量级神经架构搜索,结合层级剪枝与宽度调整,将12B模型精炼至9B参数,确保在单A10G GPU(22GiB显存)以bfloat16精度支持128k上下文长度推理,吞吐量提升3-6倍。
• 性能表现:Nemotron-Nano-9B-v2在数学、代码、科学及多语种推理基准上超越Qwen3-8B,尤其在长文本生成场景(如8k输入/16k输出)展现领先准确率与极致推理效率。
• 公开资源:模型权重、训练与后训练数据集均已开源,支持社区持续创新与应用拓展。
Nemotron Nano 2展示了通过架构创新与高质量数据驱动,如何在保证推理能力的同时实现大幅度的推理速度提升,突破了长上下文推理的硬件限制,助力AI应用进入更复杂的认知域。
了解详情🔗arxiv.org/abs/2508.14444
人工智能 大模型 长上下文推理 模型压缩 机器学习 NVIDIA