RAG检索加速新突破:利用Binary Quantization实现40倍速提升,32倍内存节省🚀
• Perplexity、Google Vertex RAG、Azure搜索管线均已采用该技术,业界认可度高
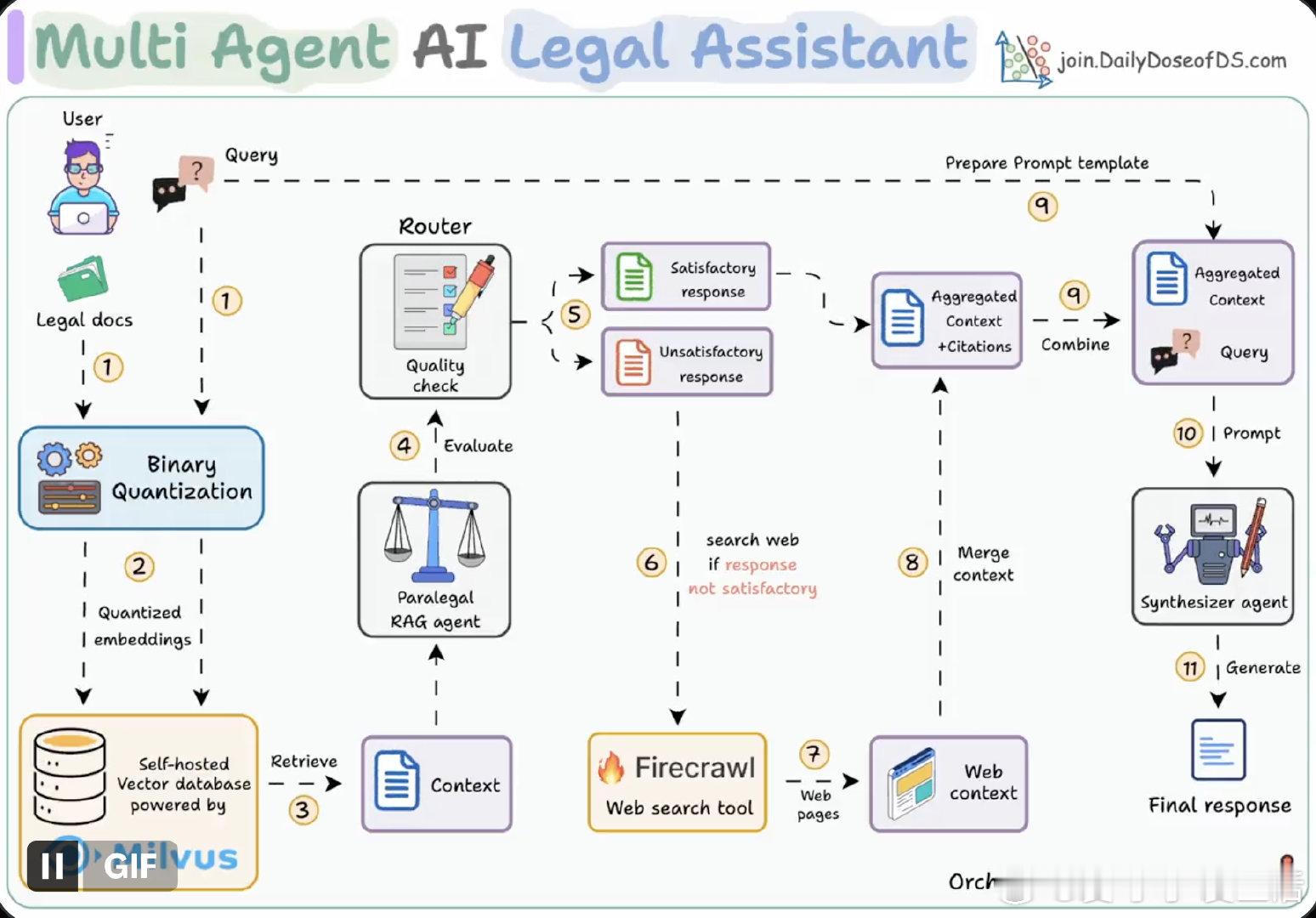
• 结合Milvus开源向量库自托管,Firecrawl实时网页检索,CrewAI调度,Ollama本地部署GPT-OSS,打造高效多代理法律助手
• 流程五步走:查询检索(BQ加速)→生成初稿→路由器评测→必要时触发网页搜索→聚合上下文生成最终答案
• Binary Quantization核心优势:极大压缩向量存储,查询时用二进制检索大幅减少计算量,实现毫秒级响应(50ms内检索5000万+向量)
• 权衡点:量化带来语义信息损失,可通过增加检索数量和重排序策略弥补
• 该方案不仅提升检索效率,更兼顾结果质量和实时性,适合大规模、动态知识库场景
• 全流程代码及演示开源,便于复制和定制,推动RAG技术由理论向生产落地转型
详细解读及代码示例👉x.com/akshay_pachaar/status/1958510665217532012
应用演示👉lightning.ai/lightning-purchase-test/studios/multi-agent-legal-assistant-powered-by-gpt-oss
向量检索 RAG BinaryQuantization 开源 人工智能 大模型






![按照站哥的说法,MIUI应该也快了吧[滑稽笑]](http://image.uczzd.cn/2918647162531115718.jpg?id=0)
