[CL]《Memory-R1: Enhancing Large Language Model Agents to Manage and Utilize Memories via Reinforcement Learning》S Yan, X Yang, Z Huang, E Nie... [Ludwig Maximilian University of Munich & Technical University of Munich] (2025)
Memory-R1:通过强化学习赋能大语言模型(LLM)智能管理与利用外部记忆
• 现有LLM受限于有限上下文窗口,难以进行长时推理,传统记忆扩展多依赖静态启发式检索,缺乏动态学习机制。Memory-R1创新性地引入强化学习(RL),训练两个专门代理:
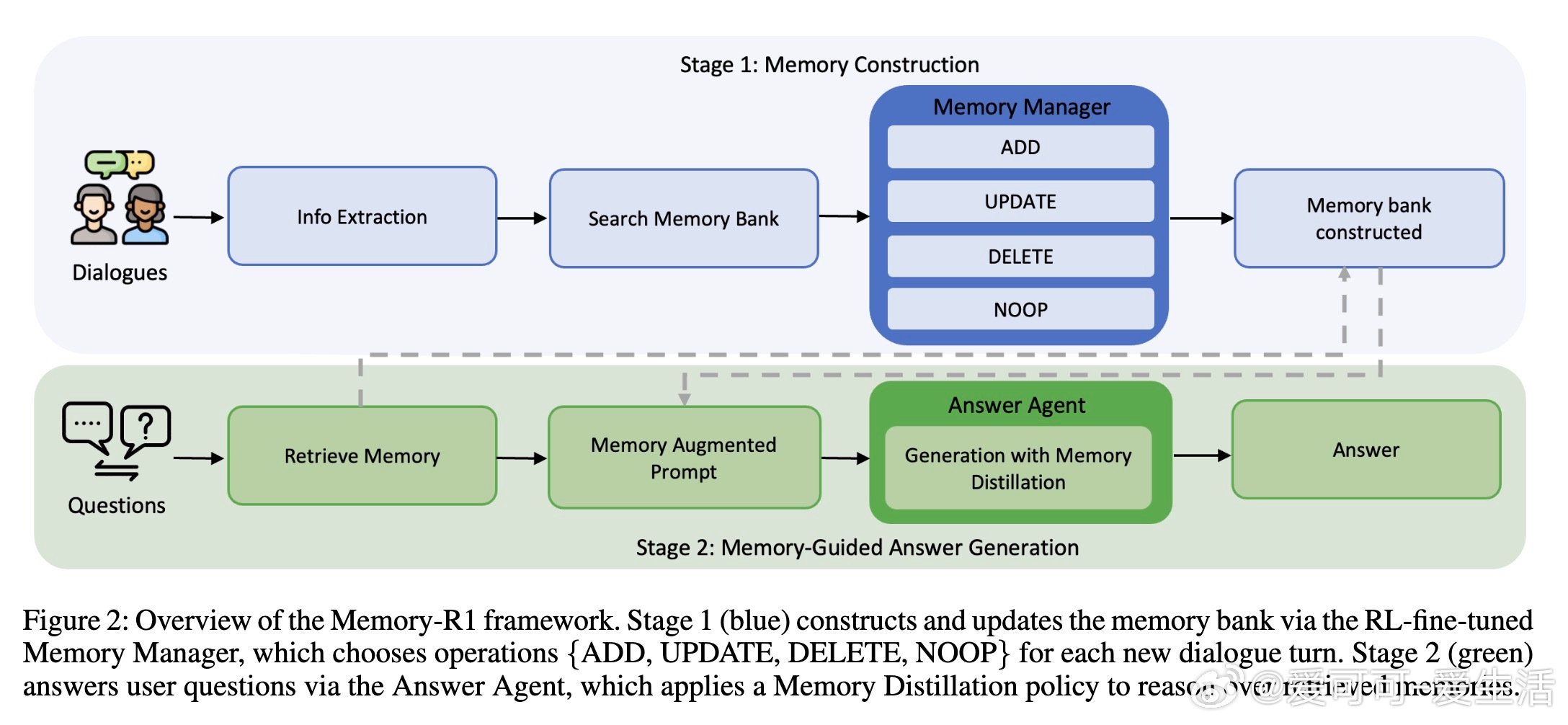
– Memory Manager:学会基于上下文执行结构化记忆操作(ADD、UPDATE、DELETE、NOOP),保证记忆库准确且连贯
– Answer Agent:通过Memory Distillation策略筛选最相关记忆条目,聚焦关键信息进行推理生成答案
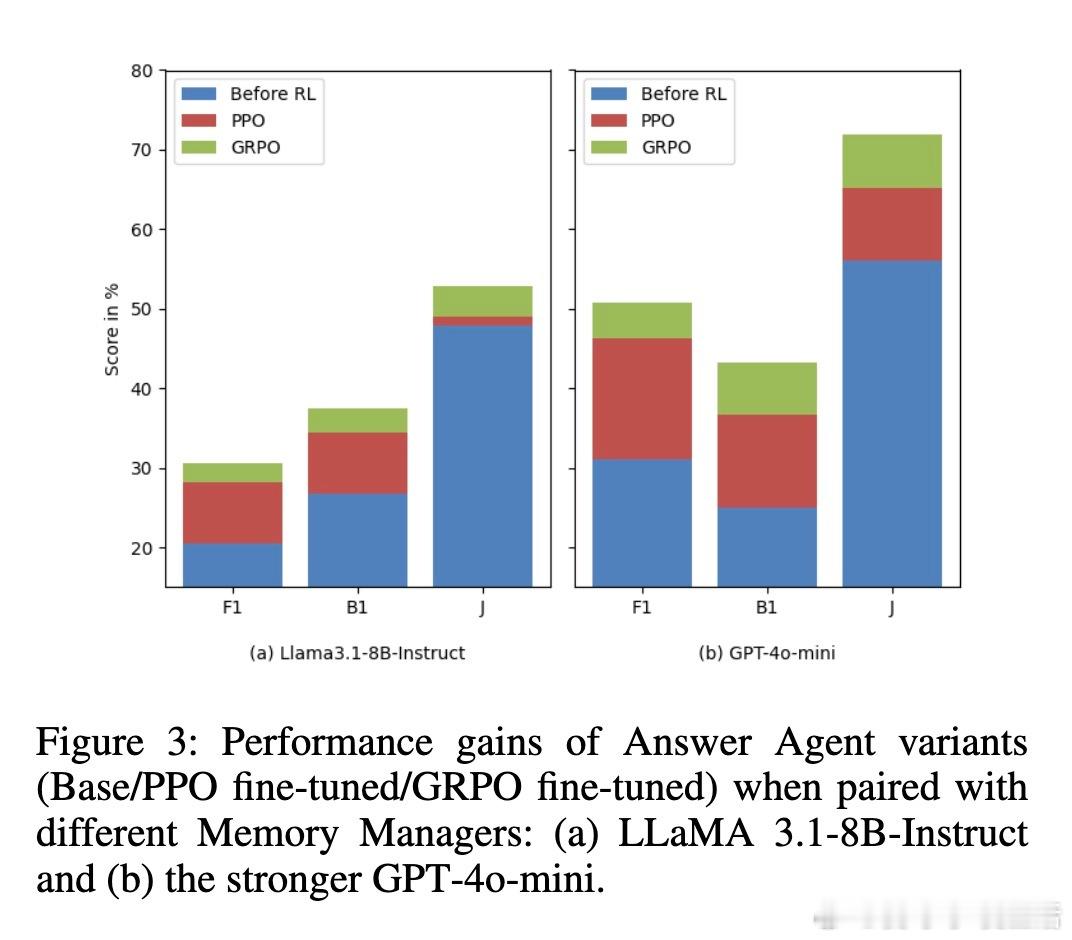
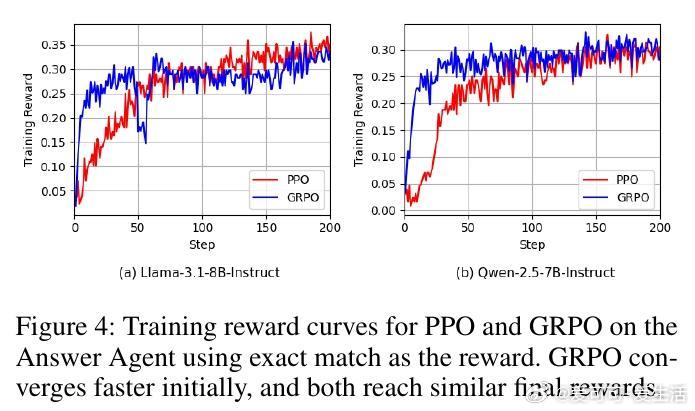
• 使用PPO与GRPO算法进行端到端微调,训练样本仅需152对问答,即能显著超越目前最强基线Mem0,提升F1高达68.9%,BLEU-1提升48.3%,LLM-as-a-Judge评测提升37.1%,跨LLaMA-3.1-8B与Qwen-2.5-7B模型均表现稳定
• 设计基于结果的奖励机制,奖励直接来源于Answer Agent的答案准确率,避免复杂标注,实现记忆操作的有效学习,提升记忆一致性和实用性
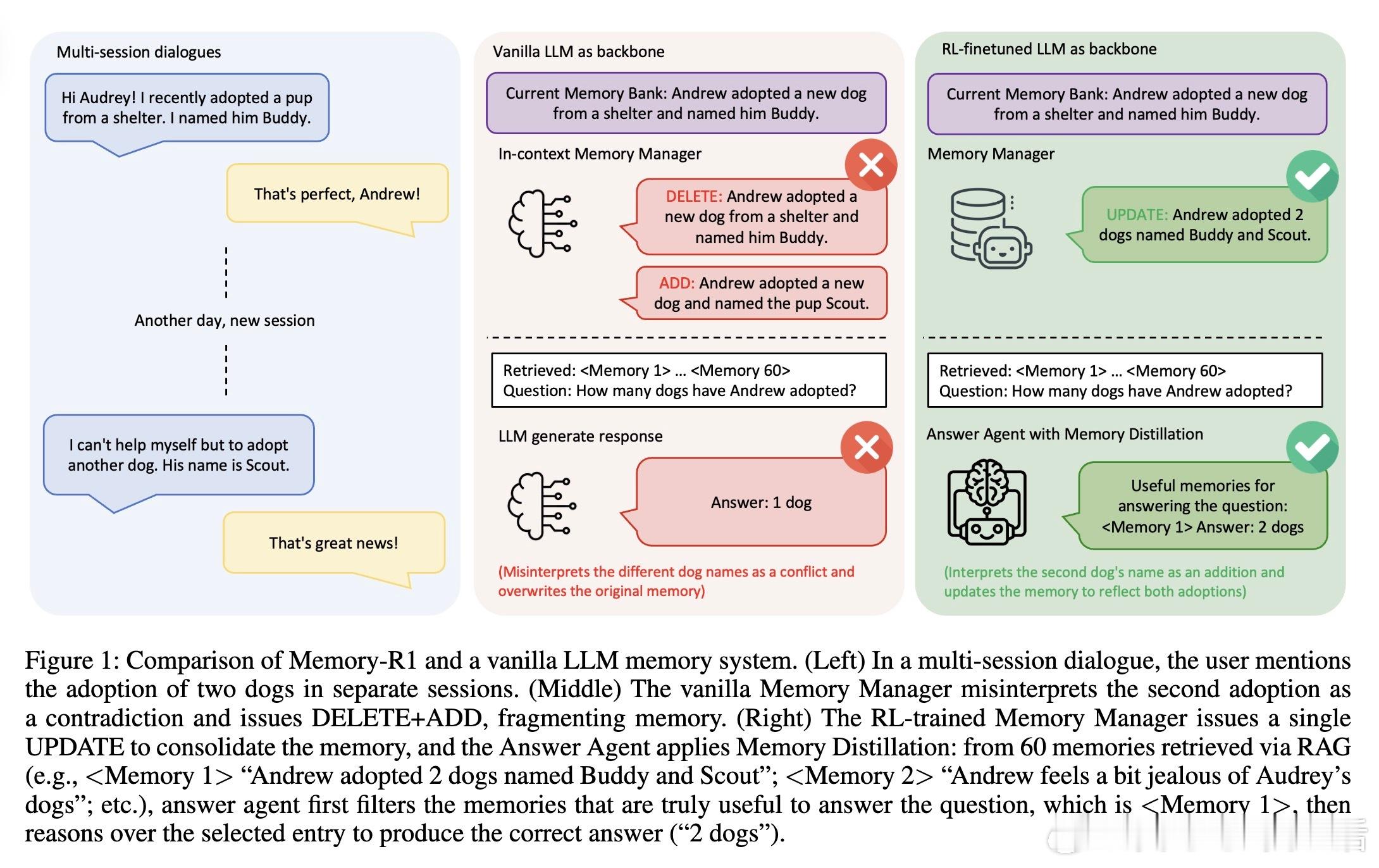
• 典型案例展现RL训练后Memory Manager能智能合并相关事实(如多次收养不同宠物),避免信息碎片化;Answer Agent借助Memory Distillation过滤噪声,准确聚焦问题相关记忆,极大提升回答质量
• 研究揭示RL促使LLM展现更具主动性和适应性的记忆行为,推动多轮对话与复杂任务中持久、结构化知识的积累与检索,指向未来构建更智能、长期记忆支持的推理系统
• 数据集基于LOCOMO多轮多会话对话问答,覆盖单跳、多跳、开放域及时间推理任务,系统训练与评测均充分体现实用性和泛化能力
Memory-R1展现了用强化学习驱动LLM记忆管理与利用的巨大潜力,为开发更具长期推理能力的大模型代理提供了坚实范式。
详细阅读👉 arxiv.org/abs/2508.19828
大语言模型强化学习记忆管理多轮对话长时推理人工智能