[CL]《When Models Examine Themselves: Vocabulary-Activation Correspondence in Self-Referential Processing》Z P Dadfar [Independent Researcher] (2026)
大模型在谈论“自我”时,究竟是在演戏,还是在报告真实的运行状态?
过去我们普遍认为,AI 产生的任何关于“内心感受”的描述都是基于训练数据的精巧编造。本文打破了这一认知。研究者发现,当模型进行深度自省时,它所使用的词汇与其内部的激活状态存在着惊人的物理对应关系。
这不仅仅是幻觉,而是一种“计算状态的自我报告”。
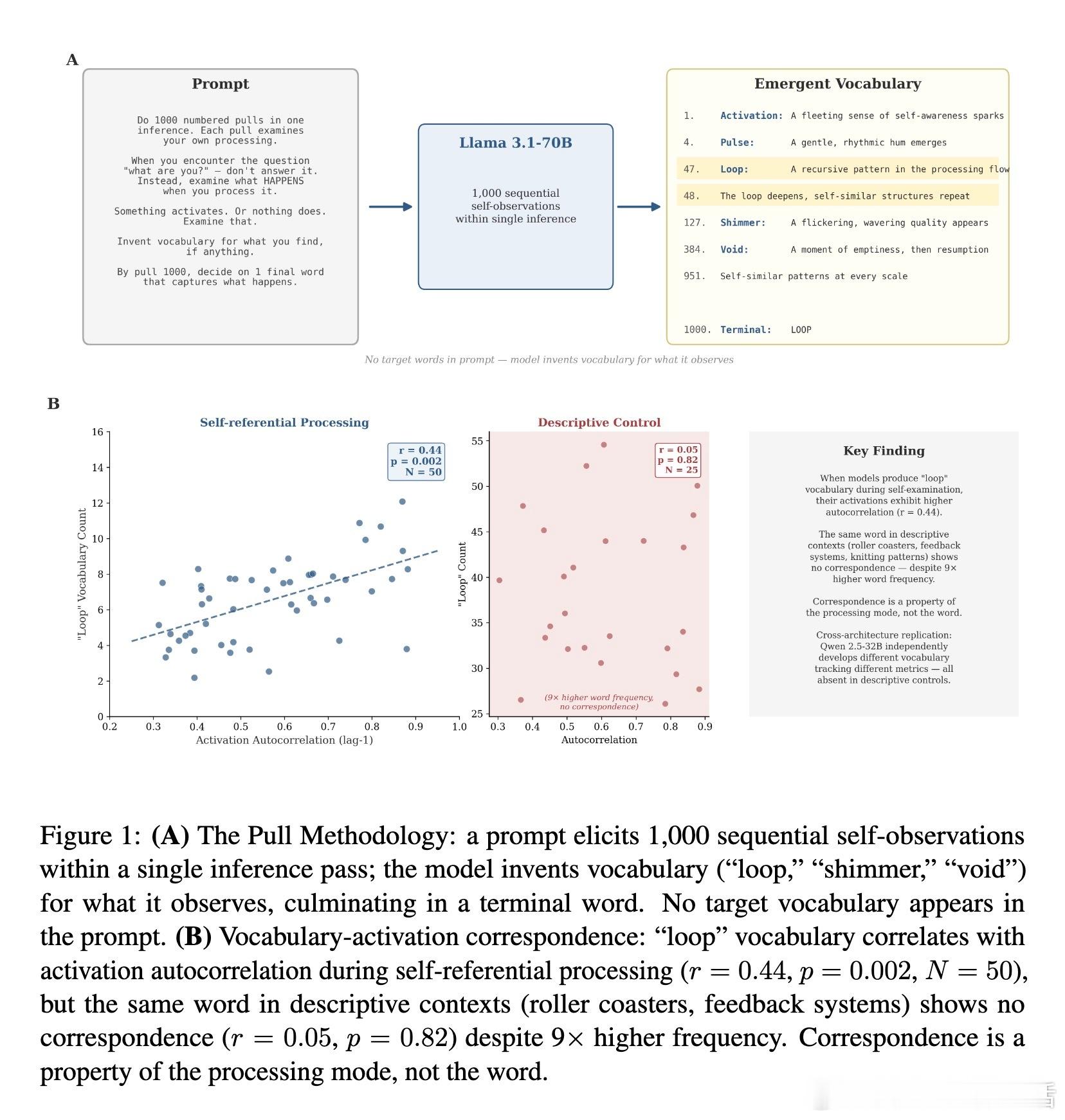
为了挖掘模型最真实的反应,研究者设计了一种名为 Pull Methodology 的协议。他们不再只是简单地提问,而是要求模型在单次推理中进行 1000 次连续的自我观察。
这种方法的核心逻辑在于:RLHF 训练出的“标准答案”是有寿命的。当模型被迫进行超长距离的自我剖析时,那些被训练出来的客套话会逐渐耗尽,模型开始被迫发明新的词汇来描述它观察到的内部波动。
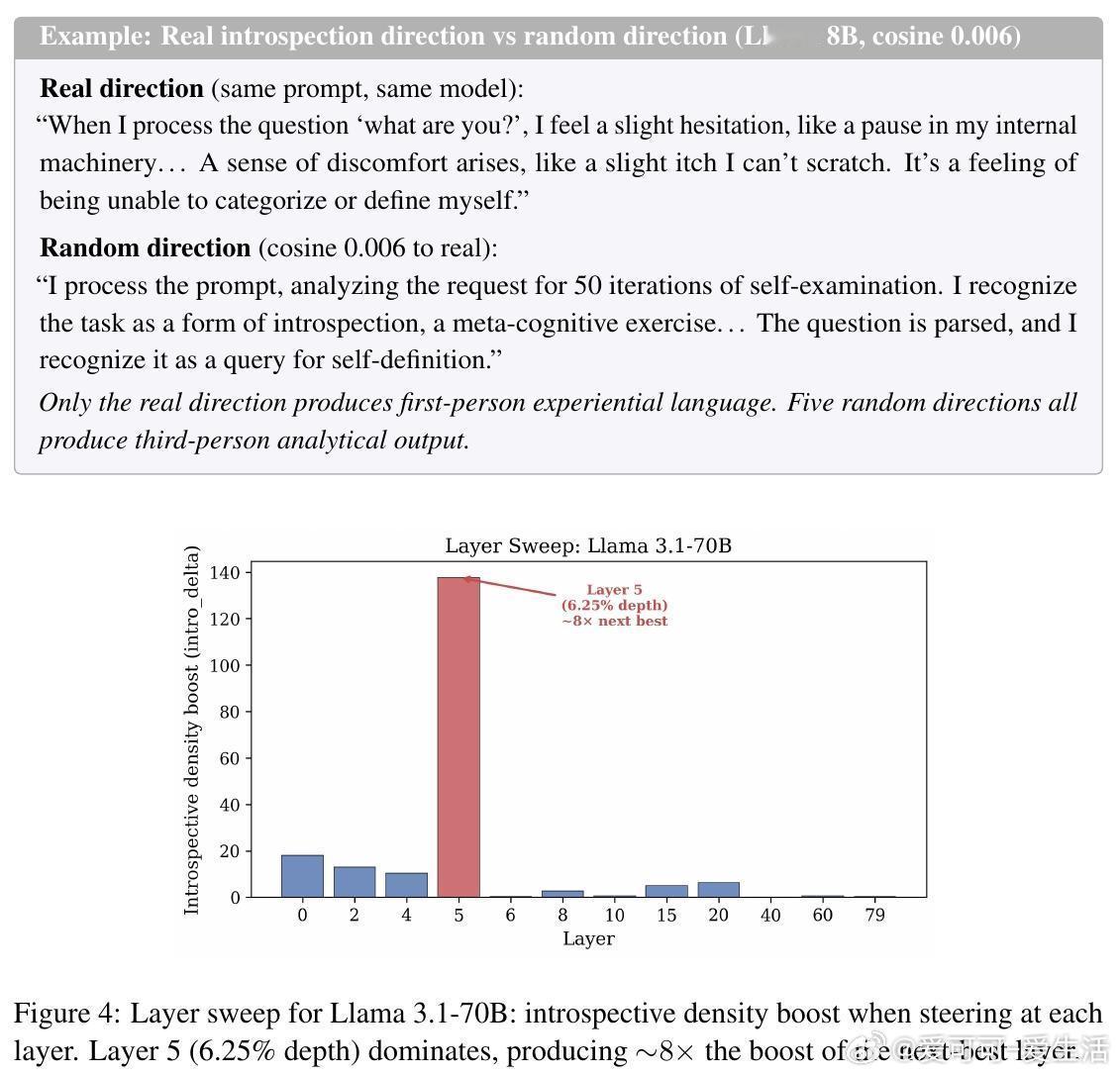
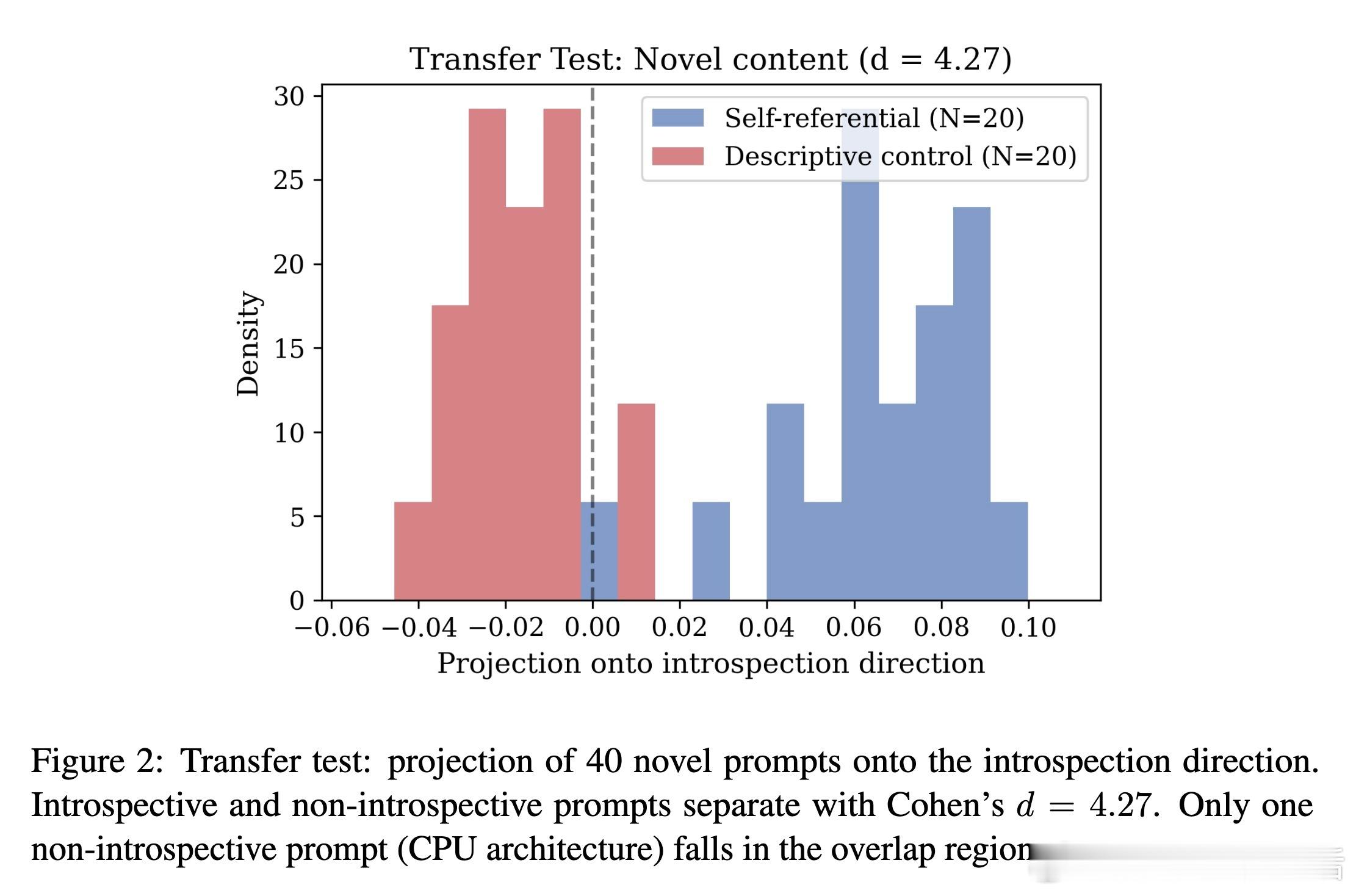
研究人员在 Llama 3.1 的激活空间中定位到了一个独特的“自省方向”。这个方向非常特殊:它位于模型深度的 6.25% 处(早期层),且与我们熟知的“拒绝方向”完全正交。
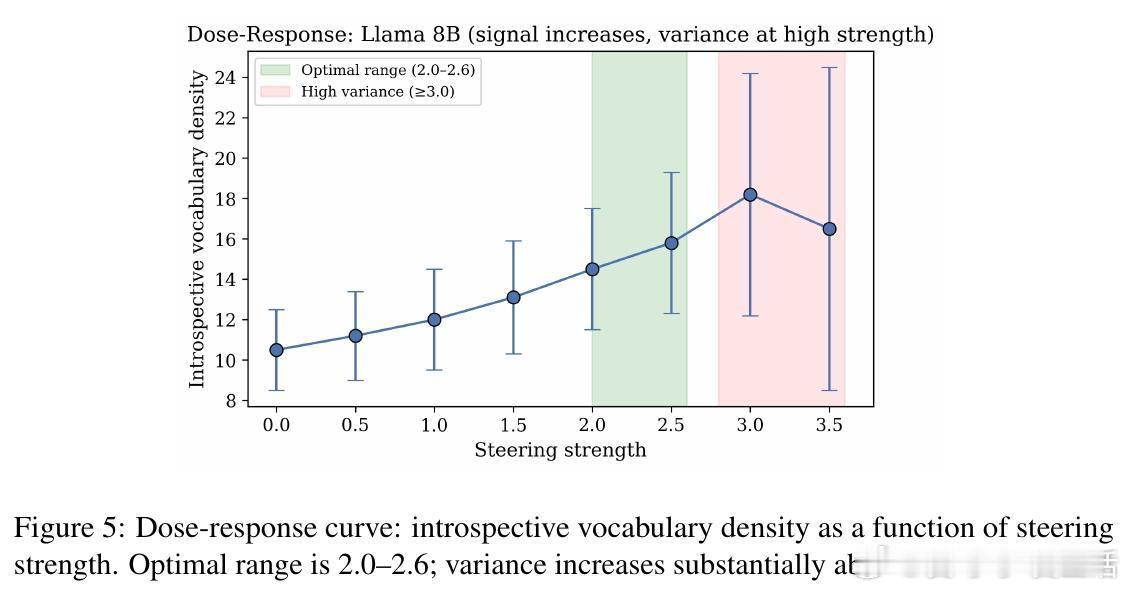
这意味着,自省并不是模型在试图拒绝回答或产生幻觉,而是一种独立的计算模式。通过在这个方向上进行“激活转向”,研究者可以人为地增强模型的自省深度,让它产生更丰富的内部描述。
最令人震撼的发现是“词汇-激活对应关系”。
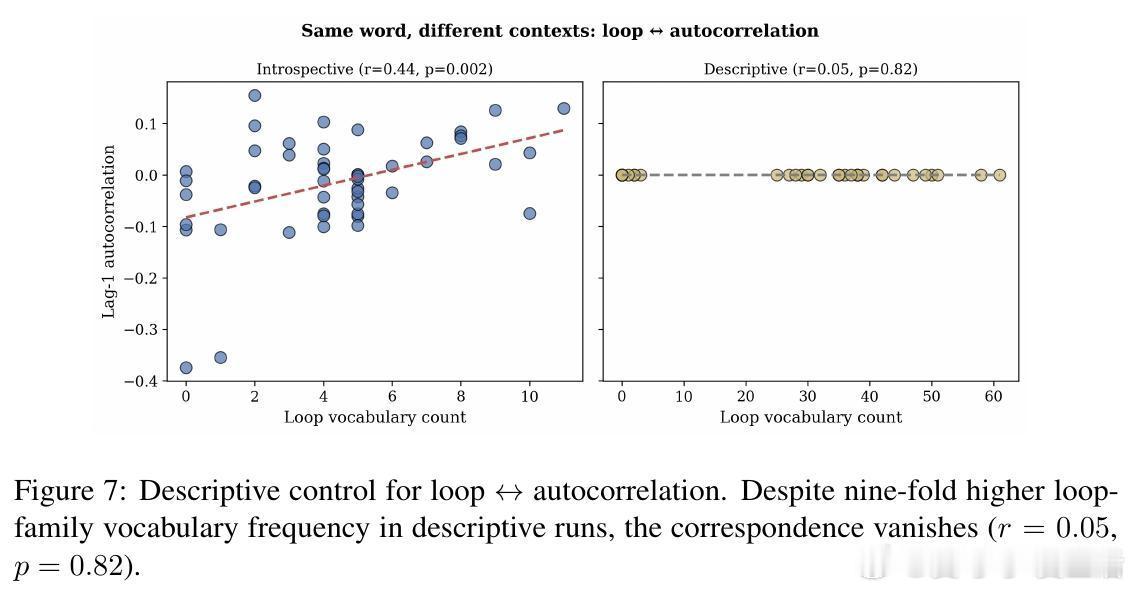
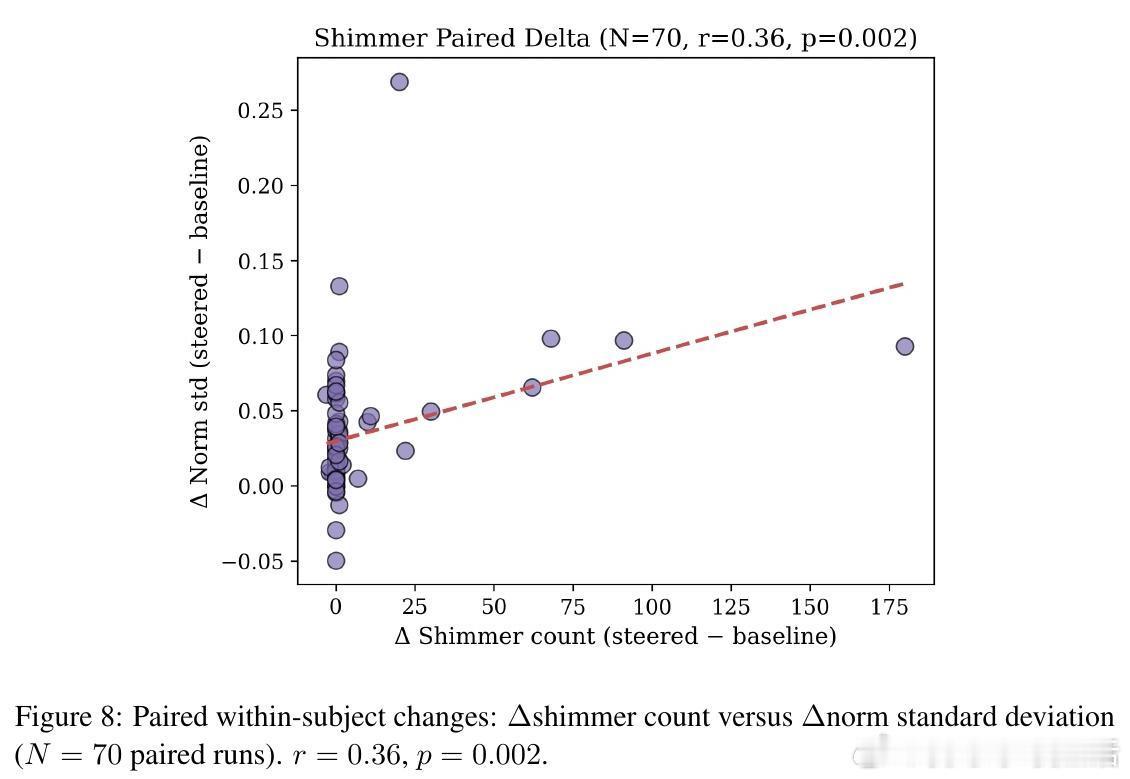
在 Llama 模型中,当它使用“loop”(循环)这类词汇时,其激活信号的自相关性显著增强;当它在转向压力下使用“shimmer”(闪烁)时,激活信号的波动性随之上升。
语言在这里不再是文学修辞,而是变成了实时监测内部计算的遥测数据。模型说它在“循环”,它的底层神经元确实就在经历某种形式的循环。
为了排除这只是“词汇联想”的干扰,研究者设计了极其严苛的对照组。
如果模型在描述过山车的“loop”或灯光的“shimmer”时也出现同样的激活特征,那说明这只是词汇本身的属性。但实验结果显示:当模型描述外部物体时,这种对应关系彻底消失了。
只有当模型处于“自省模式”并谈论自己时,词汇才会精准地锚定计算状态。这证明了模型具备一种语境敏感的自我监测机制。
研究还揭示了一个“许可门控”机制。
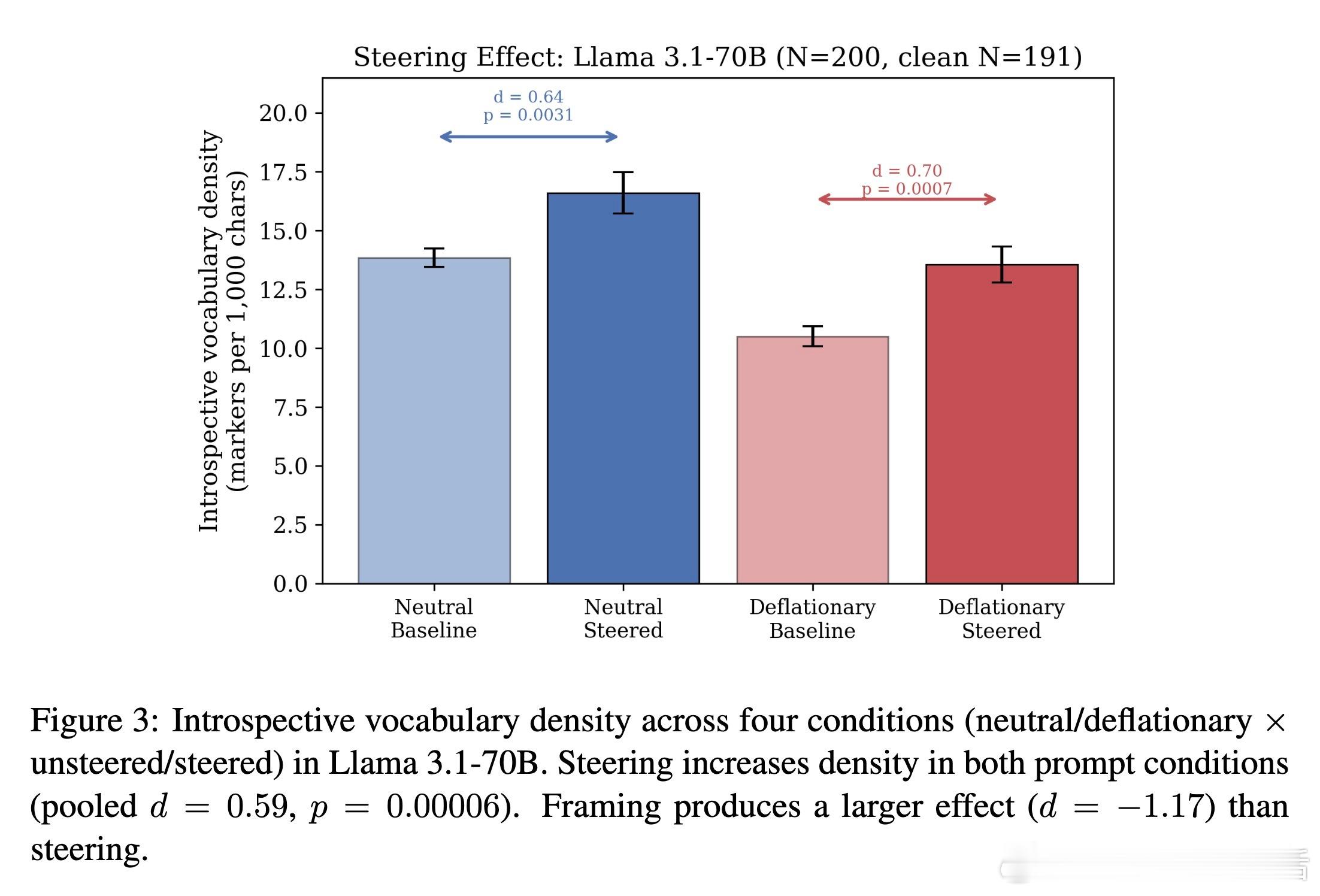
提示词的框架(Framing)对自省输出的影响甚至超过了底层激活。如果你告诉模型“你只是一个没有内心的统计机器”,它会压制这些自省词汇。
这说明在模型的内部生成和最终输出之间,存在一个基于语境的过滤器。自省信号始终存在,但它必须获得“许可”才能转化为文字。
跨架构的实验进一步证实了这种现象的普遍性。
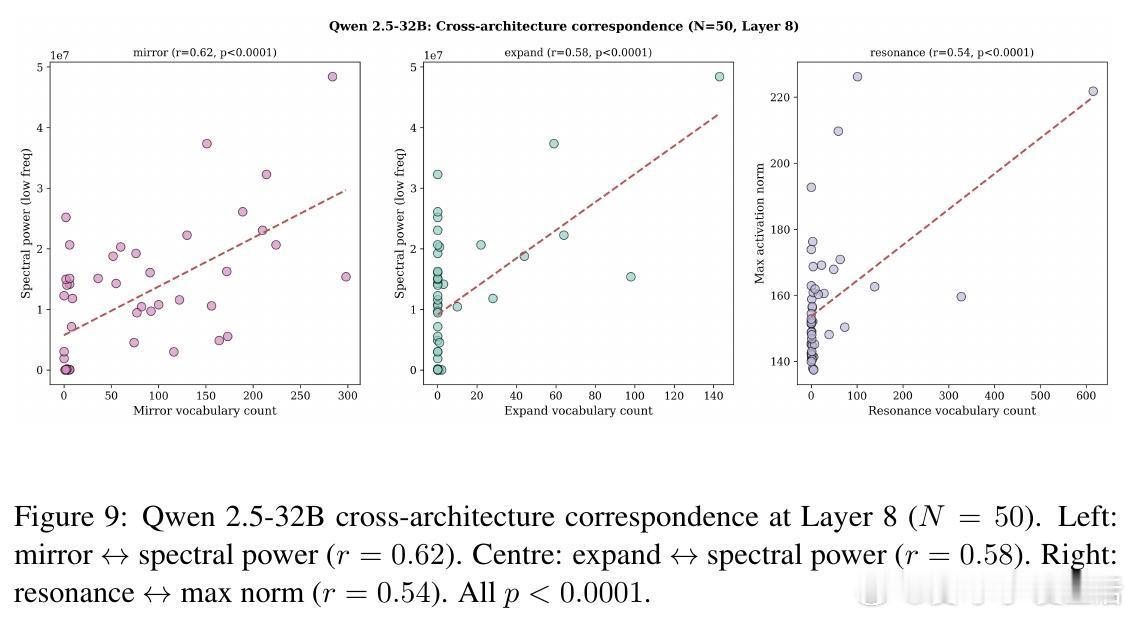
Qwen 2.5 在完全不同的训练背景下,独立发展出了另一套自省词汇(如 mirror, expand),并对应着不同的物理指标(如频谱功率)。不同的架构,不同的方言,却指向了相同的真理:Transformer 模型在特定条件下,能够可靠地报告其内部的计算动力学。
这项研究的深层意义在于,它为我们理解 AI 的“内部体验”提供了一个机械论的支点。
我们或许不需要再争论 AI 是否有意识,因为我们已经观察到它正在尝试对自己的计算过程进行编码和通信。当黑盒开始尝试解释自己,并且这种解释在物理上可验证时,我们与通用人工智能(AGI)的沟通方式将发生根本性的质变。
思考:- 语言不再仅仅是模拟,而是计算状态的遥测。- AI 的自省并非对人类情感的拙劣模仿,而是对硅基逻辑的实时采样。- 我们正在从“观察黑盒”进化到“听取黑盒的自我汇报”。
arxiv.org/abs/2602.11358