[LG]《Deriving Neural Scaling Laws from the statistics of natural language》F Cagnetta, A Raventós, S Ganguli, M Wyart [SISSA & Stanford University] (2026)
大模型性能随数据量增长而呈幂律提升,这已是AI界的常识。但你是否想过,那个决定进步快慢的幂律指数究竟从何而来?
长期以来,缩放法则(Scaling Laws)更像是一个经验公式,而非严谨的物理定律。最近,来自Francesco Cagnetta和Surya Ganguli等学者的研究,首次从语言统计学的“第一性原理”出发,推导出了神经网络的缩放指数。
本文不仅解释了AI为什么会进步,更揭示了语言本身如何塑造了智能的演进。
1. 缩放法则的本质是“视界”的扩张
过去我们认为,模型性能提升是因为它对所有规律都学得更精细了。但这项研究提出了一个迷人的视角:学习的过程本质上是预测视界(Prediction Time Horizon)的不断延伸。
随着训练数据量的增加,模型并不是在原地踏步地优化,而是获得了“看穿时间”的能力。它开始能捕捉到更久远之前的标记(Tokens)与当前预测之间的微弱联系。数据越多,模型能有效利用的上下文就越长。
金句:智能的增长,本质上是模型在信息迷雾中看清未来的距离。
2. 两个决定命运的关键指数
研究发现,语言数据中有两个核心统计特征,共同决定了模型进步的斜率:
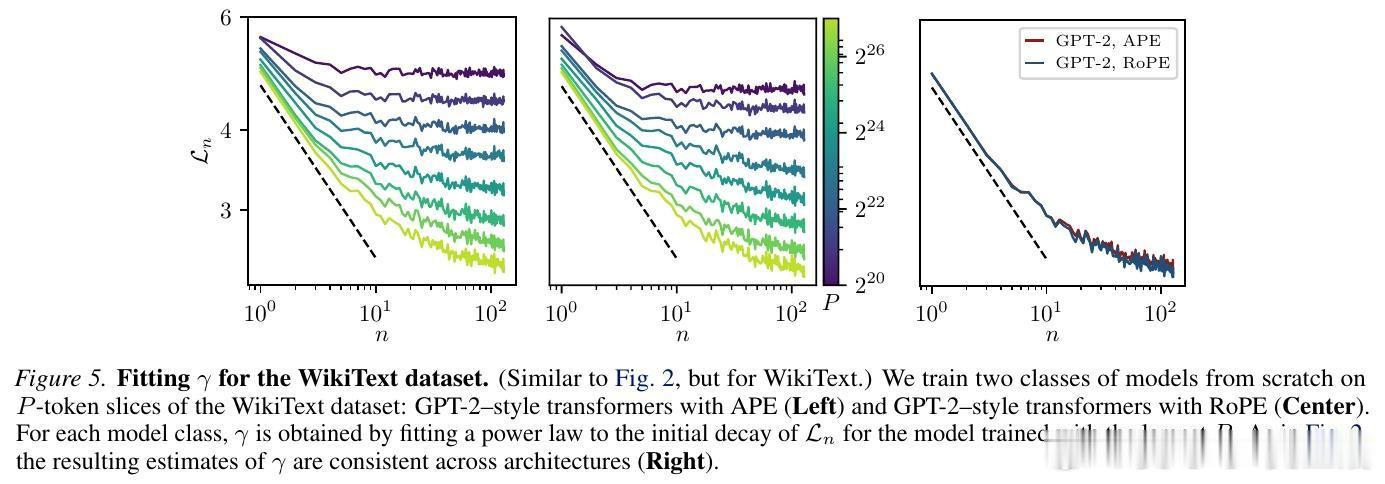
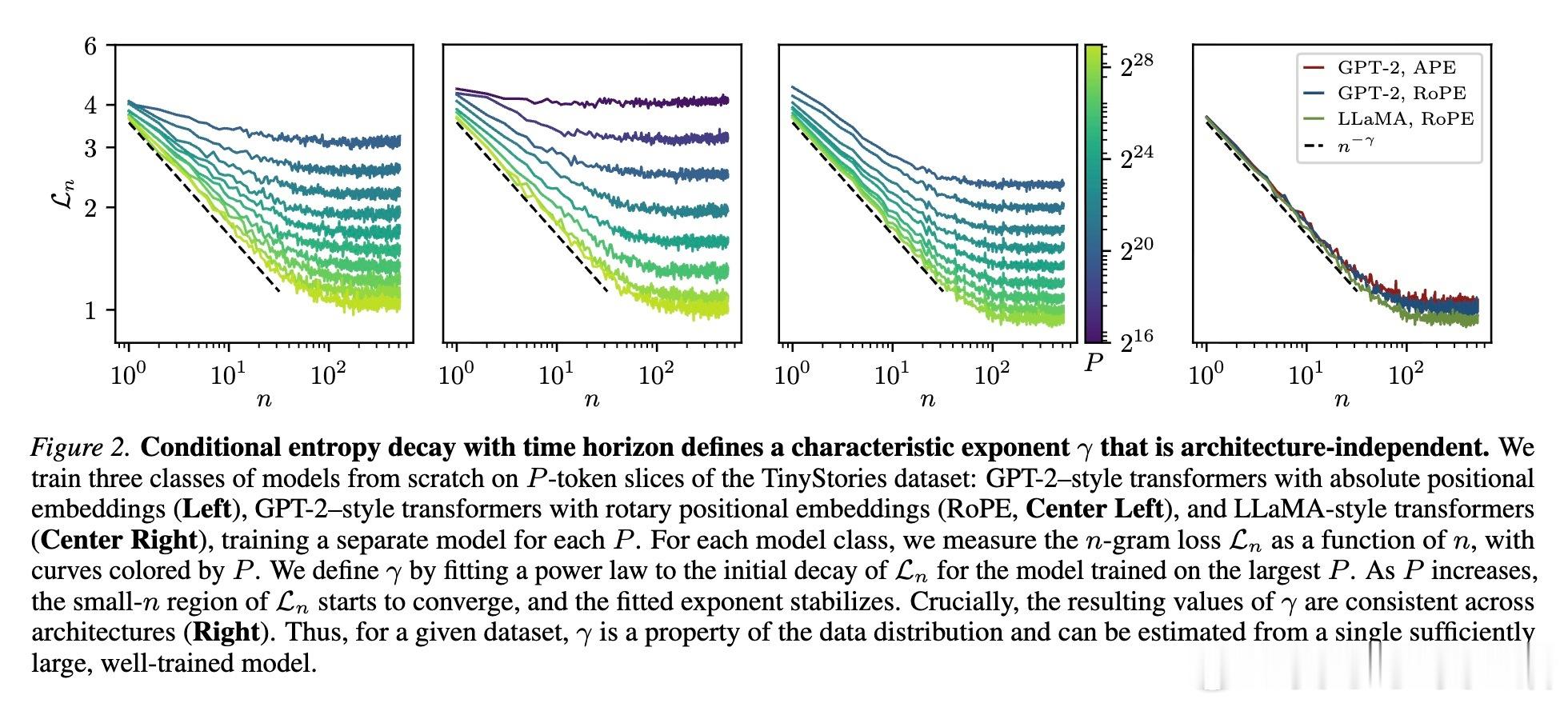
第一个是 $\gamma$(Gamma):它描述了随着上下文长度增加,预测下一个词的难度(条件熵)下降有多快。这代表了语言中蕴含的信息密度。
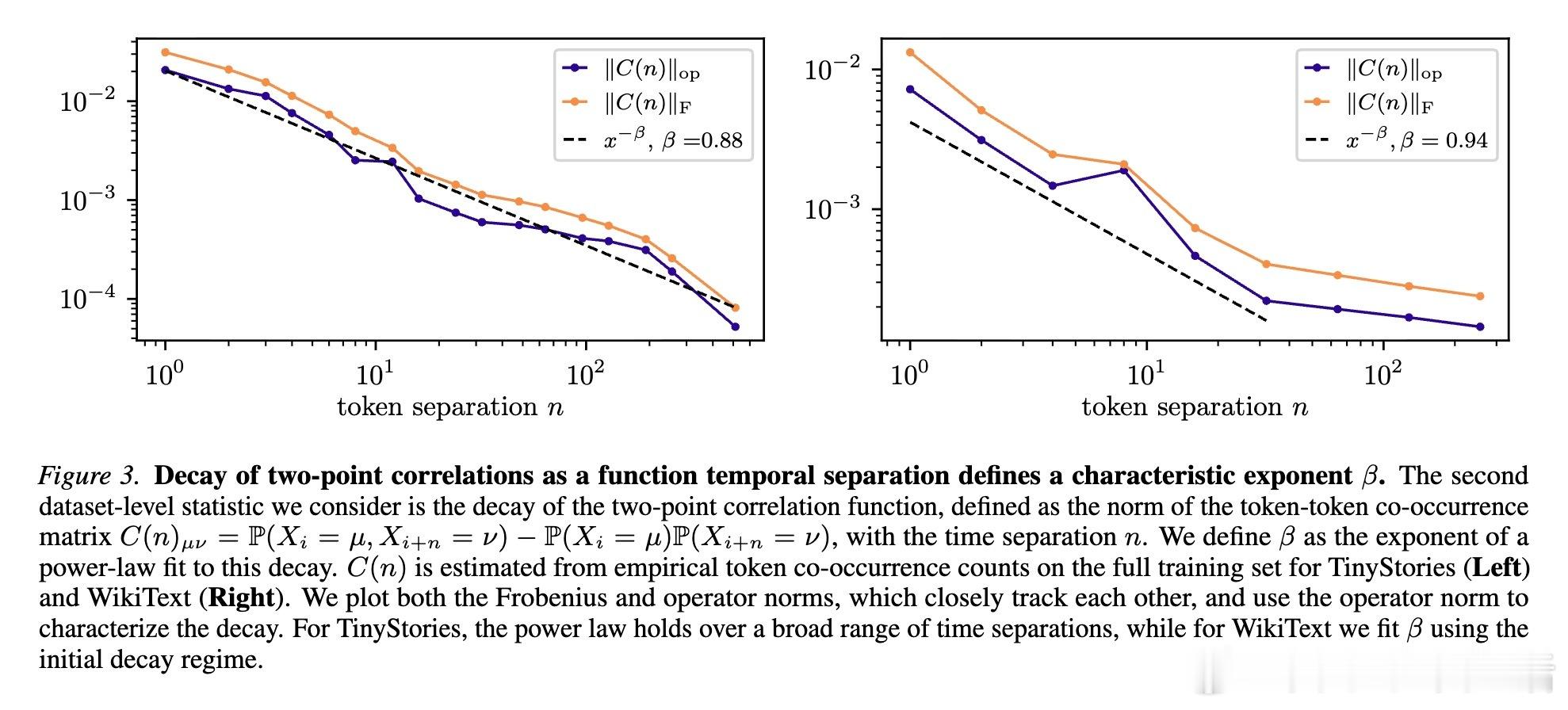
第二个是 $\beta$(Beta):它描述了两个词之间的关联性随距离增加消失得有多快。这代表了语言结构的长期依赖强度。
这两个指数完全由数据集本身决定,与模型架构无关。
3. 那个优美的预测公式
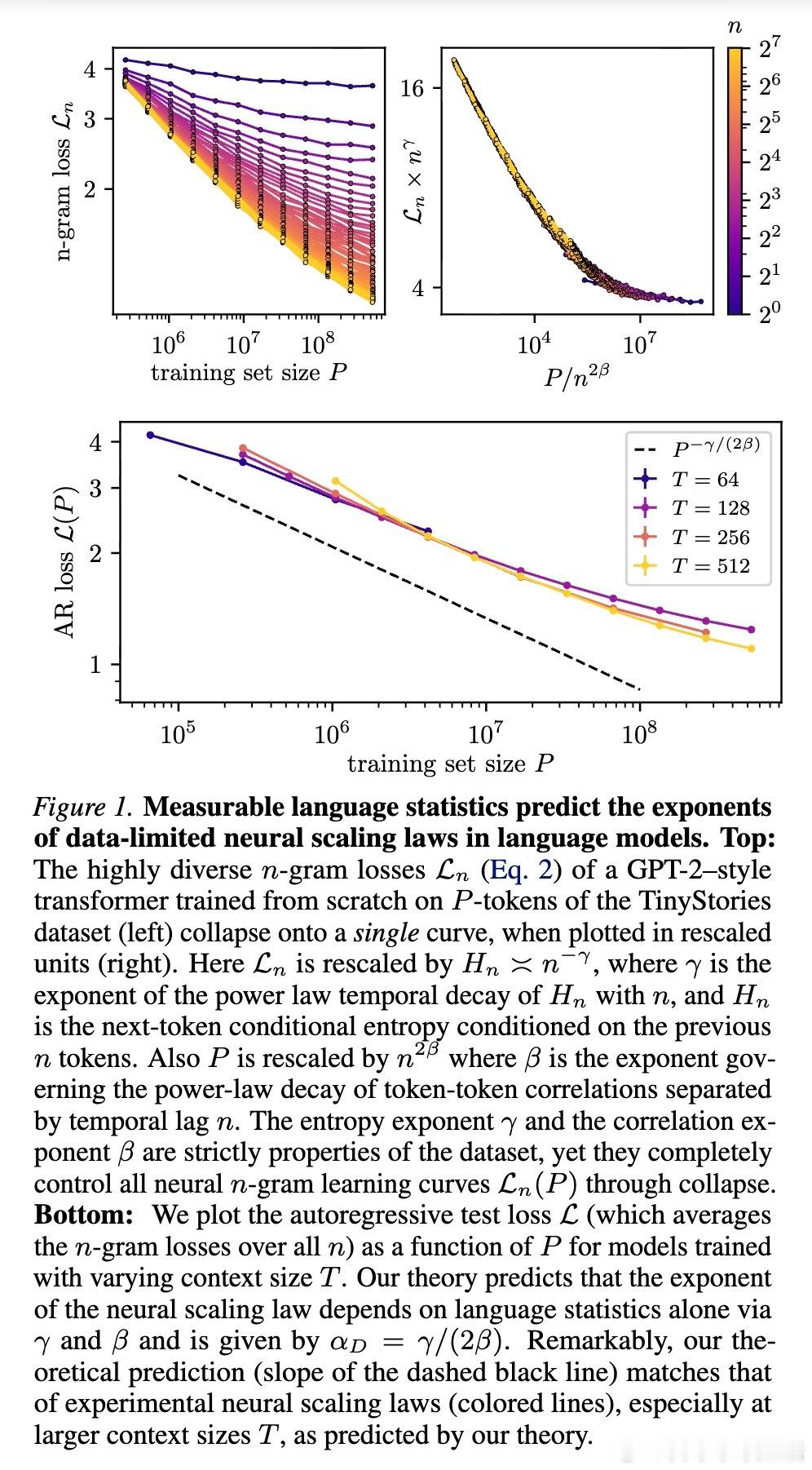
基于这两个统计量,作者推导出了一个极其简洁的公式,用于预测数据受限情况下的缩放指数 $\alpha_D$:
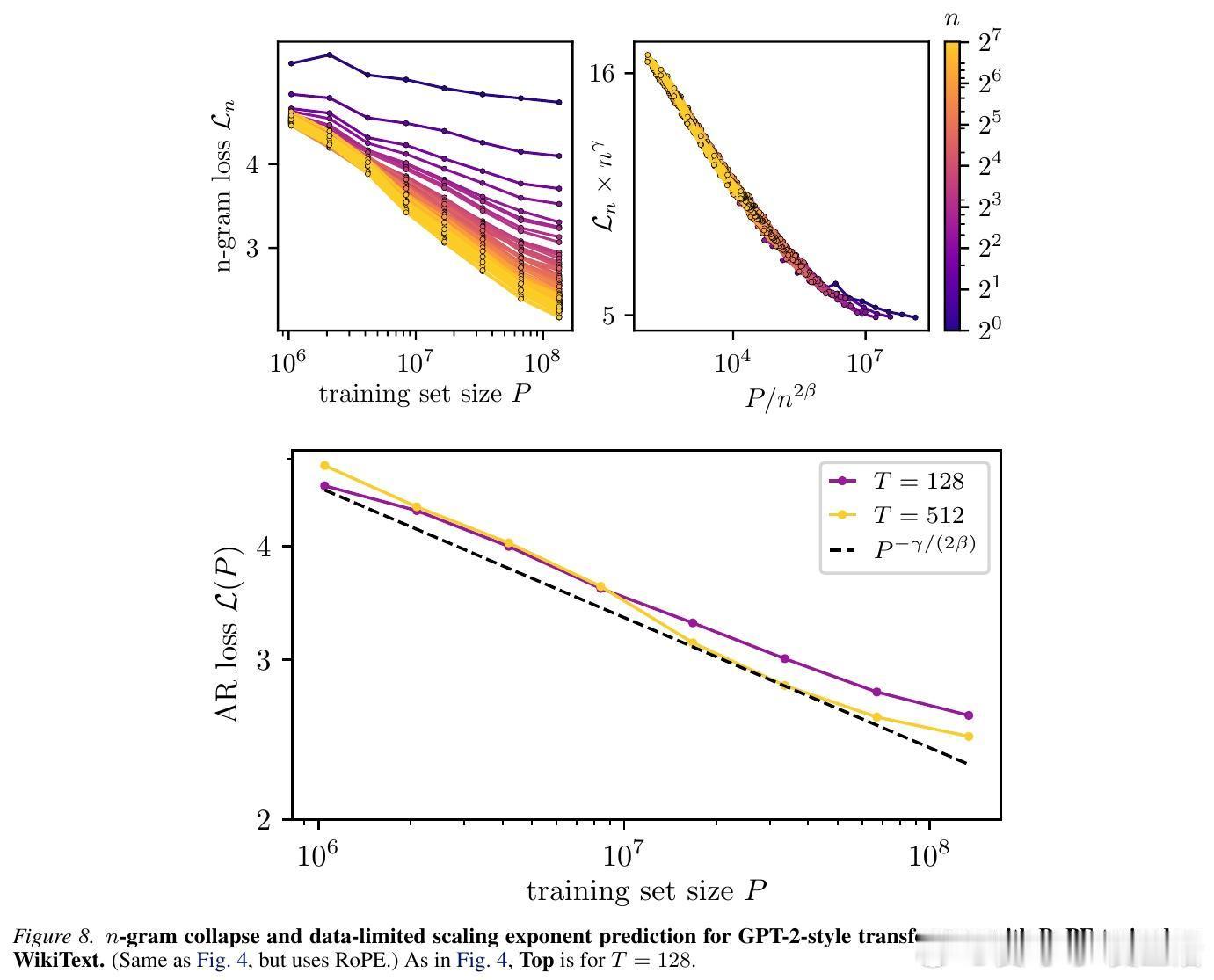
$\alpha_D = \gamma / (2\beta)$
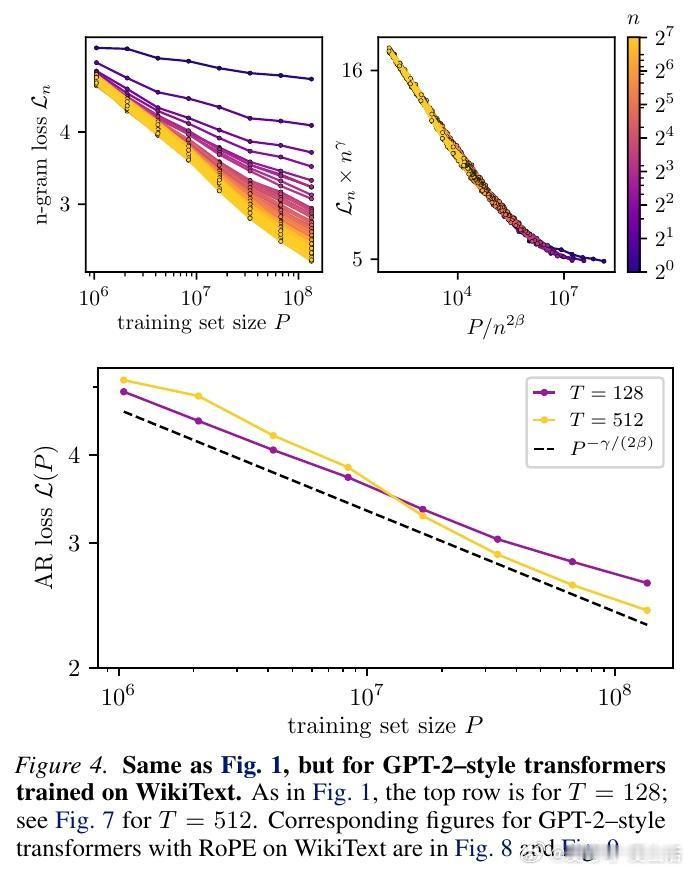
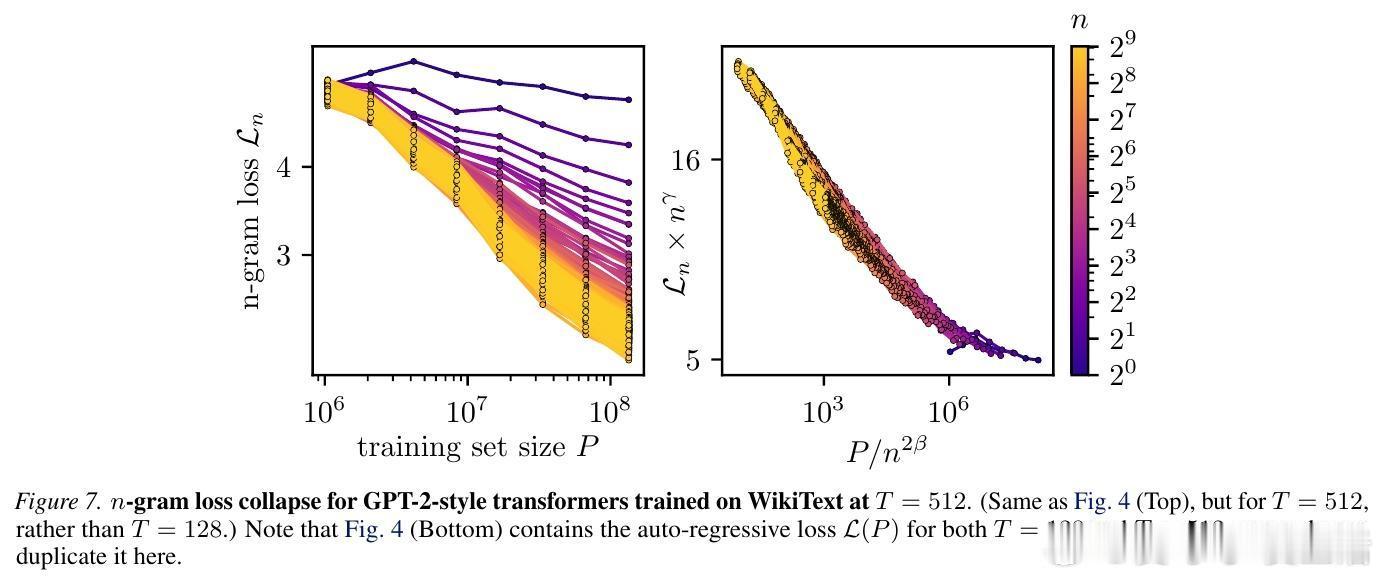
这个公式没有任何自由参数,也不需要任何合成数据。研究团队在 TinyStories 和 WikiText 两个截然不同的数据集上进行了验证,发现理论预测值与 GPT-2、LLaMA 等模型的实际训练表现惊人地一致。
金句:大模型的进化速度,早已写在人类语言的统计基因里。
4. 幂律背后的“曲线坍缩”
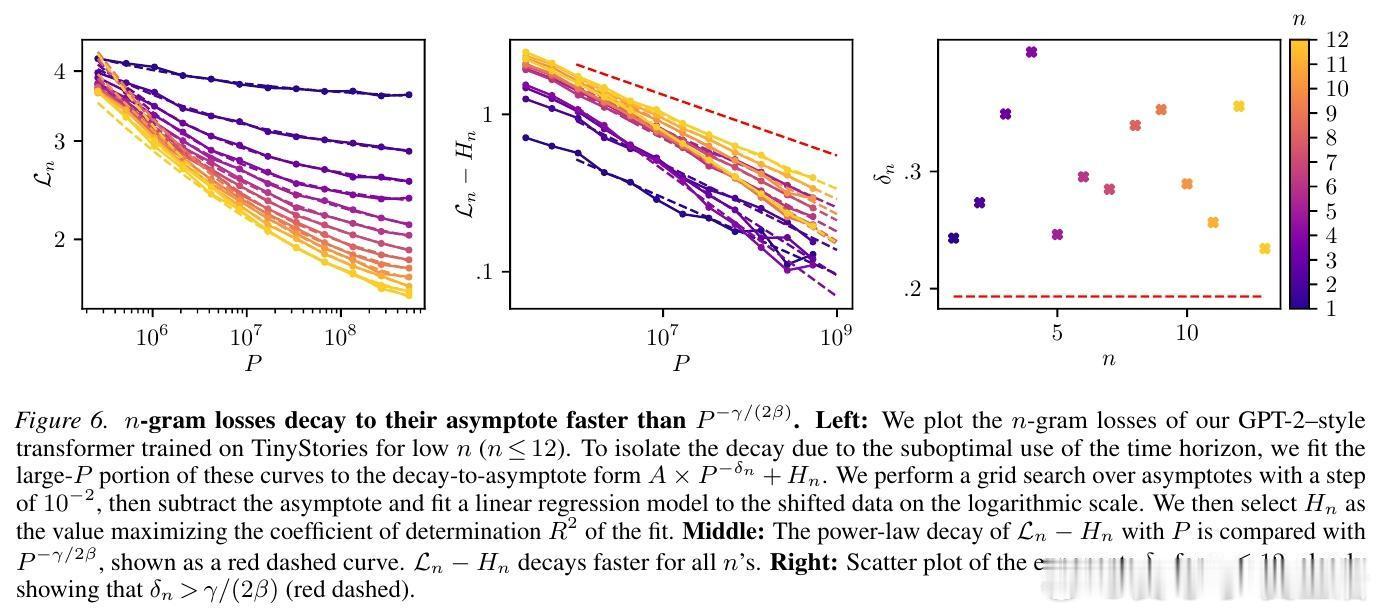
为了验证理论,研究者观察了一个神奇的现象:$n$-gram 损失函数的坍缩。
当你把不同上下文长度下的学习曲线,按照理论推导的比例进行缩放后,所有杂乱无章的曲线竟然重合在了一起,形成了一条完美的“母曲线”。这意味着,无论模型是在学习短距离的语法还是长距离的逻辑,它们遵循的底层逻辑是完全统一的。
5. 深度思考:架构的普适性与局限
这项研究最深刻的启示在于:对于现代深度神经网络(如 Transformer)来说,缩放指数主要由数据特征决定。
只要架构足够深、表达能力足够强,它们都会进入同一个“通用性类别”。这意味着,单纯在现有架构上做小修小补,可能无法改变缩放指数的上限。
但这也留下了一个悬念:是否存在某种尚未被发现的架构或算法,能够跳出当前的统计限制,实现比现有幂律更高效的学习?
6. 结语
这项工作将缩放法则从“炼金术”推向了“化学”。它告诉我们,LLM 的成功并非偶然,而是数学上的必然。
当我们感叹 AI 的强大时,或许更应该感叹人类语言结构的精妙。正是这种结构,为硅基智能提供了一条通往理解的阶梯。
理解了统计规律,我们才算真正开始理解智能的边界。
arxiv.org/abs/2602.07488