[LG]《SkillRL: Evolving Agents via Recursive Skill-Augmented Reinforcement Learning》P Xia, J Chen, H Wang, J Liu... [UNC-Chapel Hill] (2026)
LLM智能体虽然在复杂任务中展现出惊人的潜力,但它们往往面临一个致命的缺陷:孤立运行,无法从过去的经验中学习。现有的记忆机制大多只是机械地存储原始轨迹,这些数据不仅冗余且充满噪声,导致智能体难以提取出真正具有泛化能力的逻辑。
如何让智能体像人类专家一样,从经验中抽象出可复用的技能,而非死记硬背?
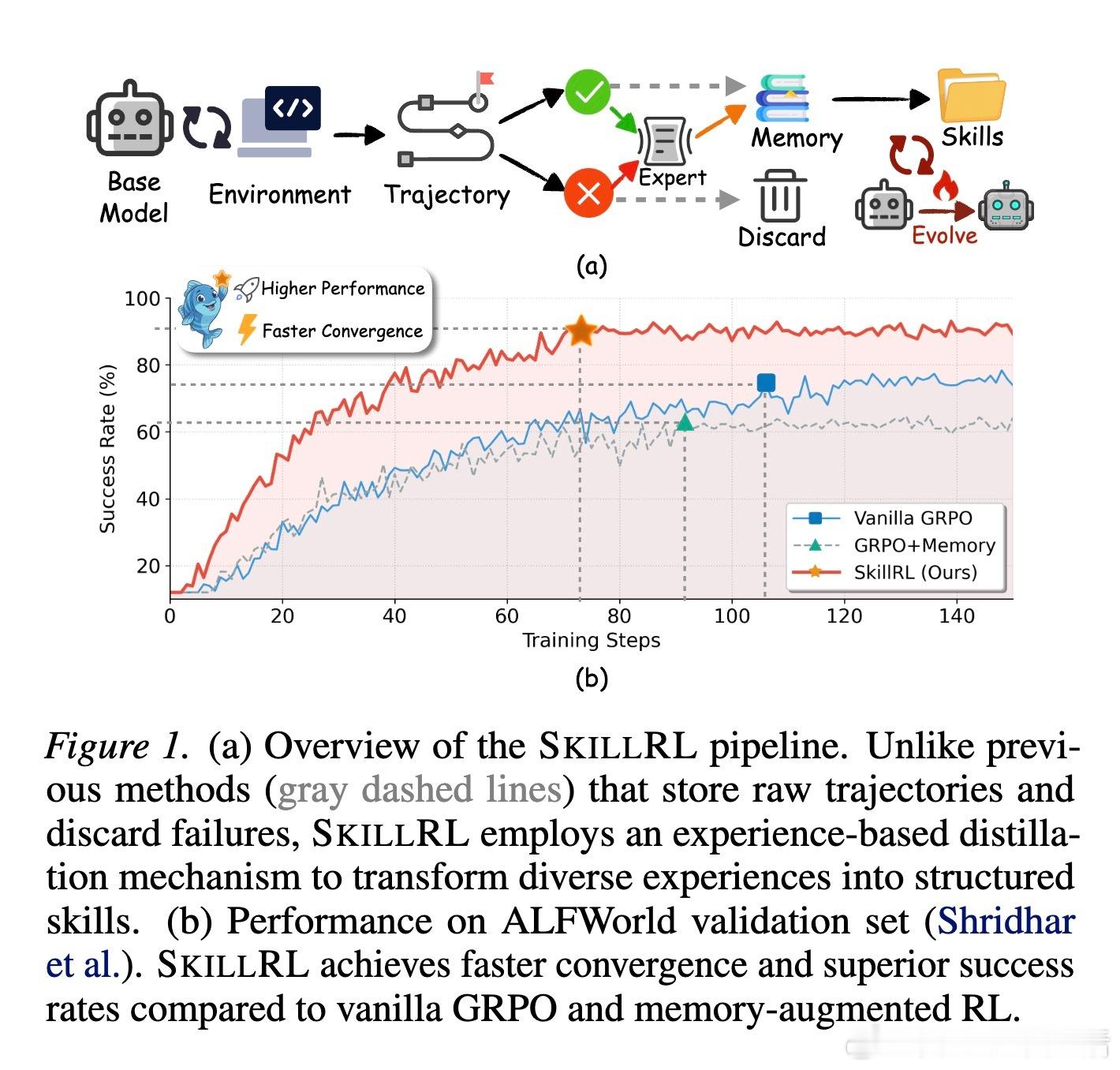
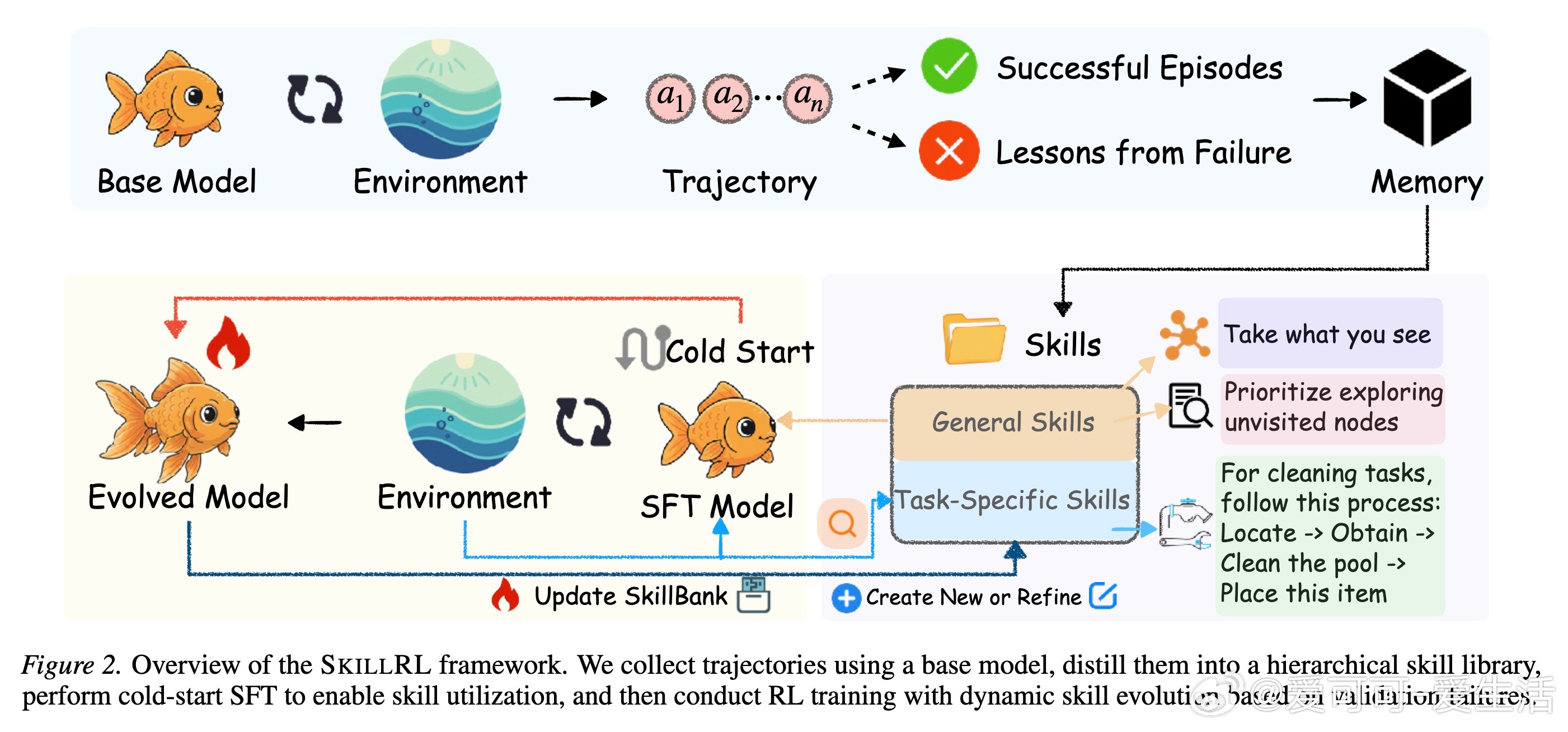
SkillRL框架提供了一个全新的视角。它通过自动技能发现与递归进化,在原始经验与策略改进之间架起了一座桥梁。核心理念在于:有效的经验传递需要抽象。人类专家不会记住每一个动作,而是开发出紧凑且可复用的技能。
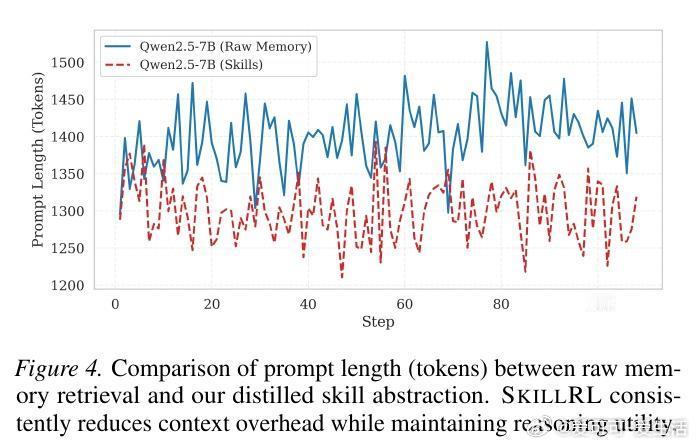
SkillRL的核心组件是层次化技能库SkillBank。它将知识分为两个维度:通用技能负责全局战略引导,如系统化搜索和状态校验;任务特定技能则沉淀局部启发式策略。这种抽象机制实现了10到20倍的Token压缩,让智能体在有限的上下文窗口内,拥有了更高效的推理效用。
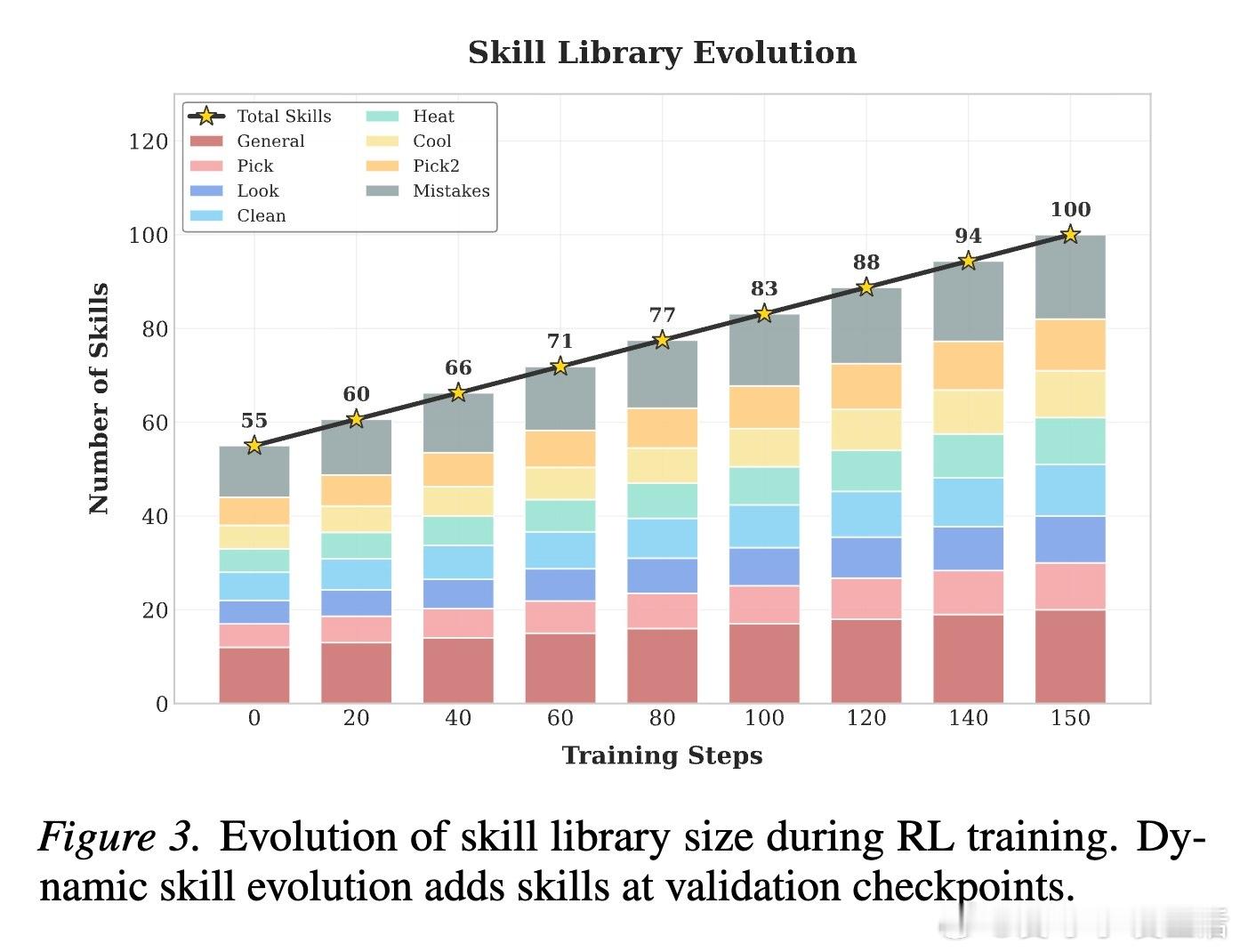
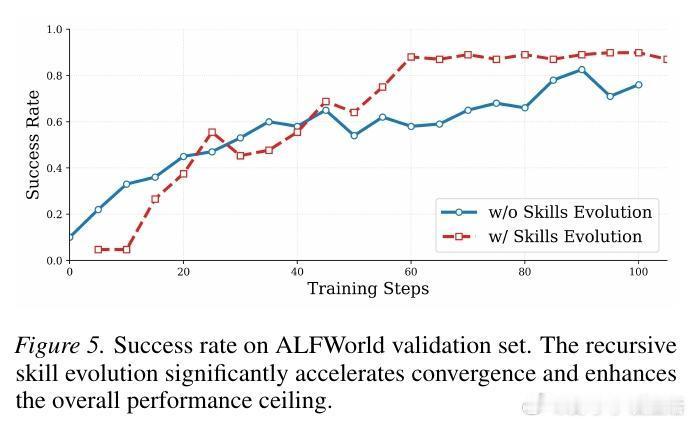
进化不应是静态的,而是一个动态的闭环。SkillRL引入了递归进化机制,让技能库与智能体策略在强化学习过程中共同成长。在每个验证周期后,系统会自动分析失败模式,生成新技能或修正现有技能。这种在战争中学习战争的模式,确保了技能库能随着任务复杂度的提升而不断自我迭代。
为了解决基础模型不会使用技能的问题,SkillRL设计了冷启动监督微调阶段。通过教师模型生成的推理轨迹,教会智能体如何检索、理解并应用这些抽象技能。随后,利用GRPO算法进行强化学习,在保持技能利用能力的同时,最大化任务成功率。
实验结果令人振奋。在ALFWorld、WebShop等挑战性基准测试中,基于Qwen2.5-7B的SkillRL性能提升了15.3%以上,显著超越了GPT-4o和Gemini-2.5-Pro等闭源巨头。这证明了结构化的经验抽象可以弥补模型规模的差距,让开源小模型也能在专业领域展现出顶尖的竞技水平。
SkillRL的研究揭示了一个深刻的洞察:智能体的真正进化,不在于存储了多少数据,而在于从数据中提炼出了多少原则。当智能体学会了自我反思与技能沉淀,它就从一个单纯的执行者转变为一个能够持续自我完善的学习者。
真正的智慧不在于记住了多少细节,而在于从细节中提炼出了多少通往成功的路径。当技能库开始递归进化,智能体才真正拥有了跨越任务边界的生命力。
arxiv.org/abs/2602.08234